
Mar 28, 2023

Author(s)


Pre-trained computer vision (CV) and natural language processing (NLP) models yield high accuracy in real-world applications but have low latency and throughput due to their large size. The models are also difficult and expensive to deploy. The problem is solved by reducing the models' size through pruning and reducing the precision of the weights through quantization. Pruning and quantization lead to smaller models that are more performant but may be less accurate. As model accuracy is one of the most important desired outcomes of successful ML projects, dropping accuracy in hopes of an easier and faster deployment is not optimal. Enter SparseML.
SparseML provides tools for applying state-of-the-art model compression techniques, such as pruning and quantization in a few lines of code without loss of accuracy. Sparsification makes deployment easier by reducing the model’s size and increasing inference speed. SparseML allows you to sparsify models through pre-configured pipelines or by defining custom ones that work best for your needs. SparseZoo, an open-source ML model repository, provides compressed CV and NLP models for immediate use, for free. However, you still need a way to deploy these models for fast inference. Enter DeepSparse.
DeepSparse is an inference runtime offering GPU-class performance on CPUs and APIs to integrate ML into your application and take advantage of model sparsity. By enabling you to deploy models with the flexibility and scalability of software on commodity CPUs, you benefit from best-in-class performance of hardware accelerators, standardized operations and a reduction in infrastructure costs. Like Hugging Face, DeepSparse provides off-the-shelf pipelines for CV and NLP that wrap the model with proper pre- and post-processing to run performantly on CPUs using sparse models.
This article outlines how to use DeepSparse CV and NLP pipelines to deploy models to production quickly and efficiently. DeepSparse provides fast inference and high throughput on deep learning models, especially for compressed models as the runtime was engineered to take advantage of sparsity to deliver best-in-class CPU performance. As a result, you will deploy sparsified and quantized models from SparseZoo to guarantee better performance. You will see good performance even with the free 2vCPU 16GB of hardware provided on Hugging Face Spaces.
Deploying Computer Vision Pipelines with DeepSparse and SparseZoo
Image Classification
Image classification involves identifying the type of items in an image and their corresponding confidence. It is applicable in scenarios where you are interested in only classifying objects in an image without localizing them. For example, you can build an image classification model to categorize products in a store.
DeepSparse provides an image_classification pipeline for classifying images. The pipeline enables you to choose a sparsified model from SparseZoo or provide a model in the ONNX format.
Here is a code snippet for a DeepSparse image classification pipeline with the ResNet50 model:
from deepsparse import Pipeline
pipeline = Pipeline.create(task='image_classification',
model_path = "zoo:cv/classification/resnet_v1-50/pytorch/sparseml/imagenet/base-none", )
input_image = "my_image.png" # path to input image
inference = pipeline(input_image)
print(inference)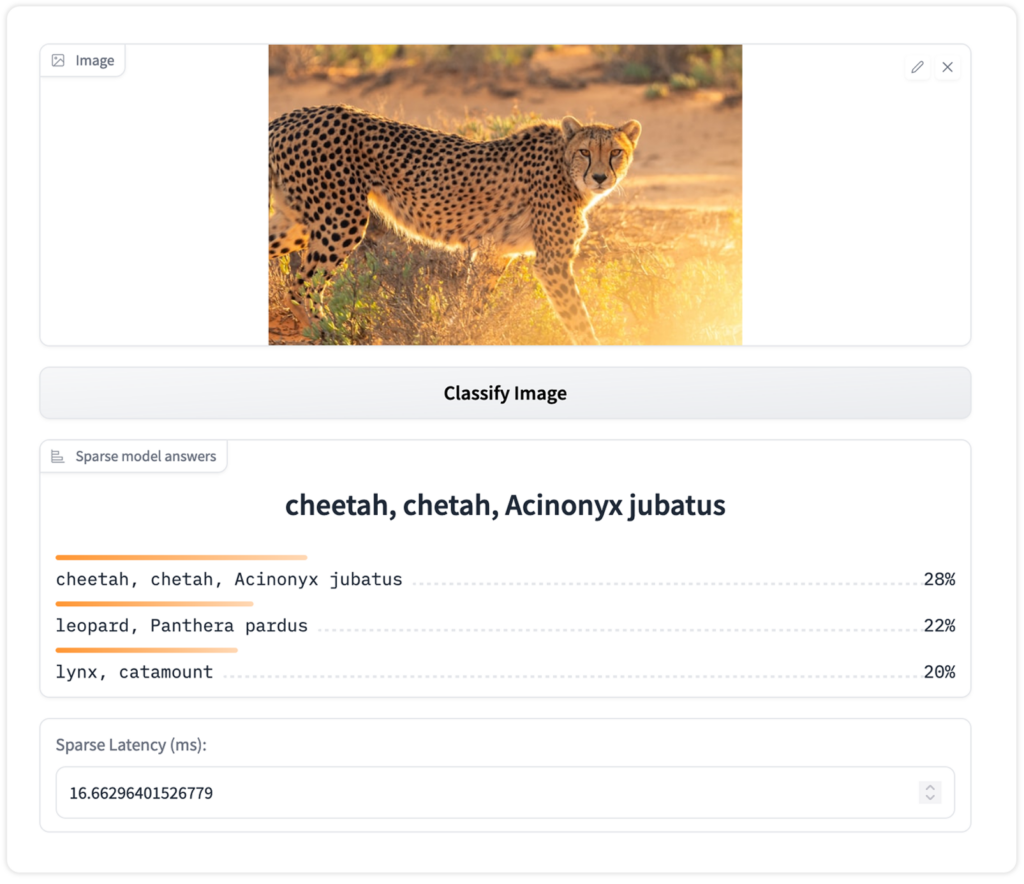
Image Segmentation
YOLACT stands for "You Only Look At Coefficients." YOLACT was one of the first methods to do instance segmentation in real-time. YOLACT extends the popular YOLO (You Only Look Once) algorithm.
The YOLACT pipeline enables real-time object detection. Here is sample code for a YOLACT image segmentation pipeline:
from deepsparse import Pipeline
pipeline = Pipeline.create(task='yolact',model_path="zoo:cv/segmentation/yolact-darknet53/pytorch/dbolya/coco/pruned82_quant-none",
class_names="coco", )
input_image = "my_image.png" # path to input image
inference = pipeline(input_image)
print(inference)
A use case for image segmentation is sorting and packing items in a factory. Accurate detection and segmentation can improve quality and lower inspection costs. Such tasks need real-time detection. This is achieved by acquiring expensive computing resources such as GPUs. What if the same could be achieved using CPUs? Sparsified and quantized YOLACT models deployed with DeepSparse enable you to achieve GPU-class performance on commodity CPUs.
Object Detection
YOLOv5 by Ultralytics is an object detection model in the YOLO family. YOLOv5 translated the popular YOLO architecture from Darknet to PyTorch. YOLOv5 uses data augmentation strategies, such as mosaic augmentation, that help accurately detect small objects. Porting the model to PyTorch also enabled training and inference with lower precision, speeding up inference and training.
Here is sample code for a YOLOv5 object detection pipeline in DeepSparse:
from deepsparse import Pipeline
pipeline = Pipeline.create(task='yolo',model_path="zoo:cv/detection/yolov5-l/pytorch/ultralytics/coco/pruned_quant-aggressive_95",class_names=None, model_config=None, )
input_image = "my_image.png" # path to input image
inference = pipeline(input_image)
print(inference)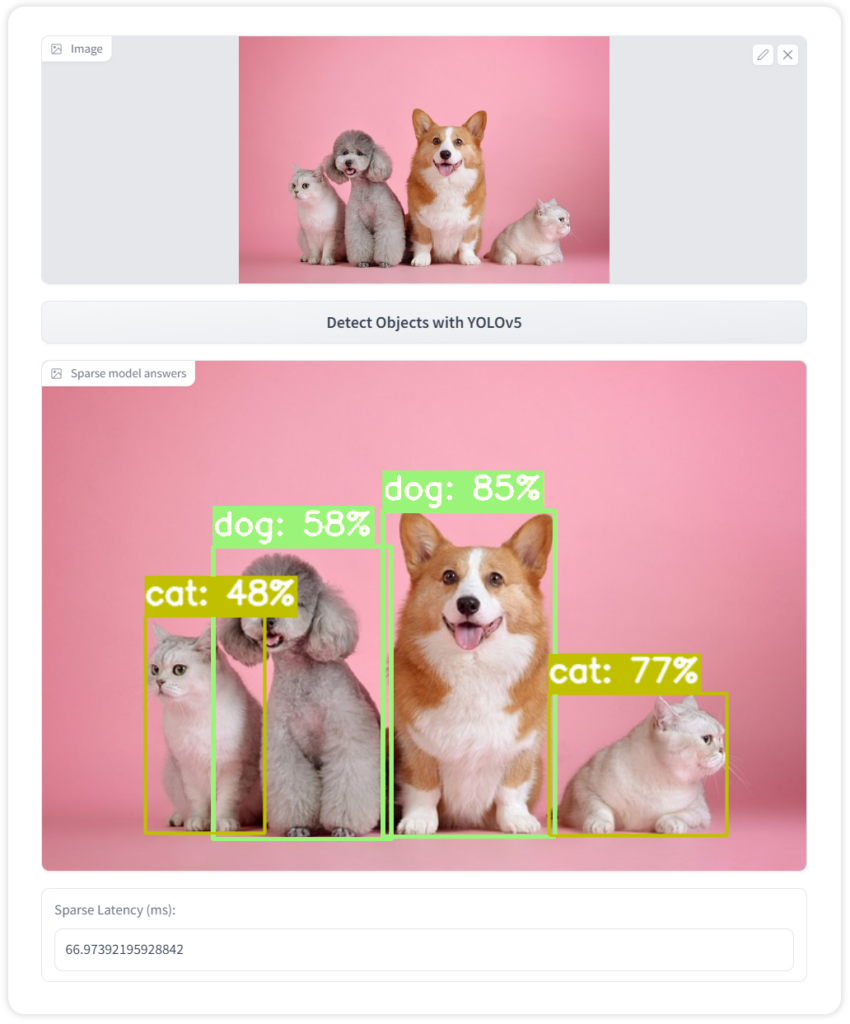
An example use case for object detection is counting people in a shopping center, grocery store or factory. This type of computation needs to happen in real time. Since dense object detection models are large, required performance and accuracy can only be achieved using expensive GPUs. Sparsified and quantized YOLOv5 models enable the same performance you would get on a GPU, but with commodity CPUs.
Deploying Natural Language Processing Pipelines with DeepSparse and SparseZoo
Question Answering
Given a context and question, a question-answering (QA) model provides an answer to the given question. QA models help retrieve answers quickly from large texts.
Here is sample code for a QA pipeline:
from deepsparse import Pipeline
pipeline = Pipeline.create(task="question-answering", model_path="zoo:nlp/question_answering/distilbert-none/pytorch/huggingface/squad/base-none")
question = "DeepSparse is sparsity-aware inference runtime offering GPU-class performance on CPUs and APIs to integrate ML into your application."
context = "What is DeepSparse?"
inference = pipeline(question=question, context=context)
print(inference)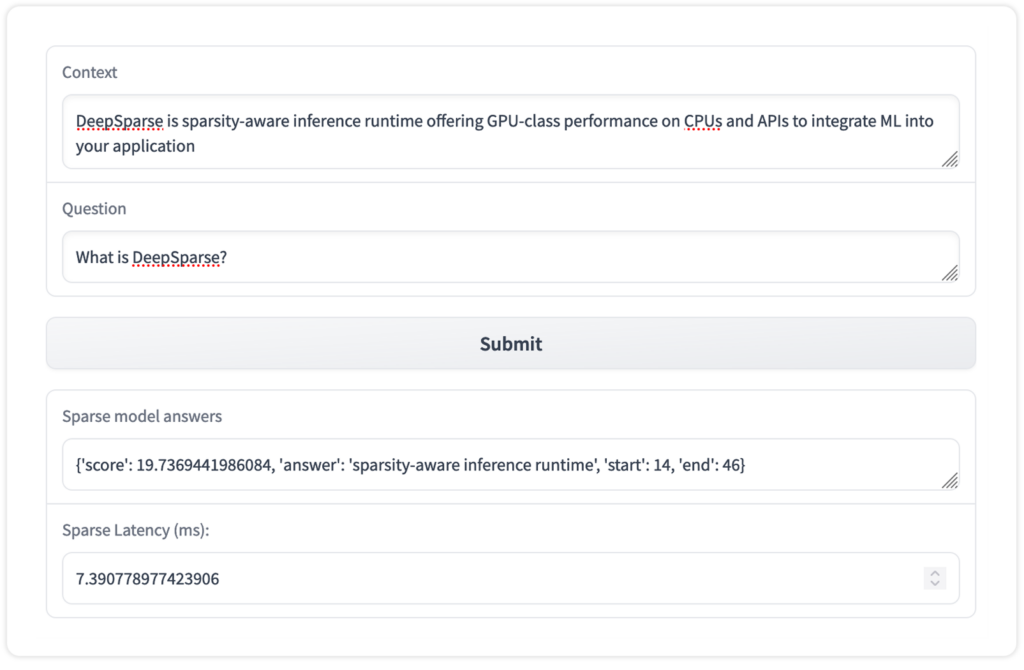
Searching documents is one example of a QA model in use. Imagine a situation where you have thousands of documents but need to find an answer from the documents. At the same time, you would like to retrieve the document where the answer is from. You could open and search the documents individually, but that would take a long time.
Enter extractive question answering (EQA) with DeepSparse. With EQA, you enter a query into the system, and in return, you get the answer and the document containing it.
Named Entity Recognition
Named entity recognition involves extracting and locating named entities in a sentence, such as people's names, locations, or organizations.
Here is sample code for a token classification pipeline in DeepSparse:
from deepsparse import Pipeline
pipeline = Pipeline.create(task="ner", model_path="zoo:nlp/token_classification/distilbert-none/pytorch/huggingface/conll2003/pruned80_quant-none-vnni and sentiment analysis to zoo:nlp/sentiment_analysis/bert-base/pytorch/huggingface/sst2/12layer_pruned80_quant-none-vnni")
text = "Mary is flying from Nairobi to New York"
inference = pipeline(text)
print(inference)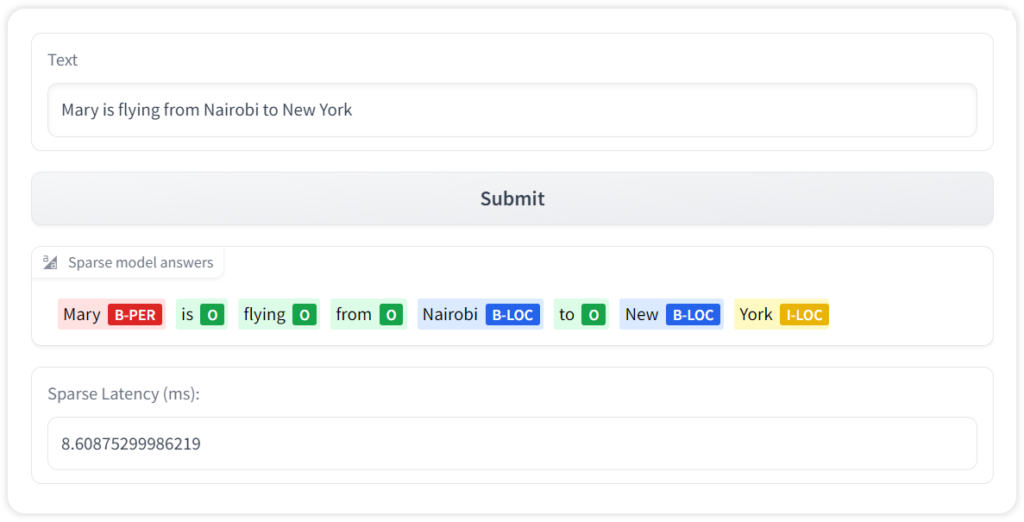
The named entity recognition pipeline can process text before inserting the information into a database. For example, consider processing the text and storing the entities in different columns based on the entity type.
Text Classification
Text classification involves assigning a label to a given text. The text classification pipeline wraps an NLP model with the proper preprocessing and postprocessing steps, such as tokenization.
Here is sample code for a text classification pipeline with DeepSparse:
from deepsparse import Pipeline
pipeline = Pipeline.create(task="zero_shot_text_classification", model_path="zoo:nlp/text_classification/distilbert-none/pytorch/huggingface/mnli/pruned80_quant-none-vnni",model_scheme="mnli",model_config={"hypothesis_template": "This text is related to {}"},)
text = "The senate passed 3 laws today"
inference = pipeline(sequences= text,labels=['politics', 'public health', 'Europe'],)
print(inference)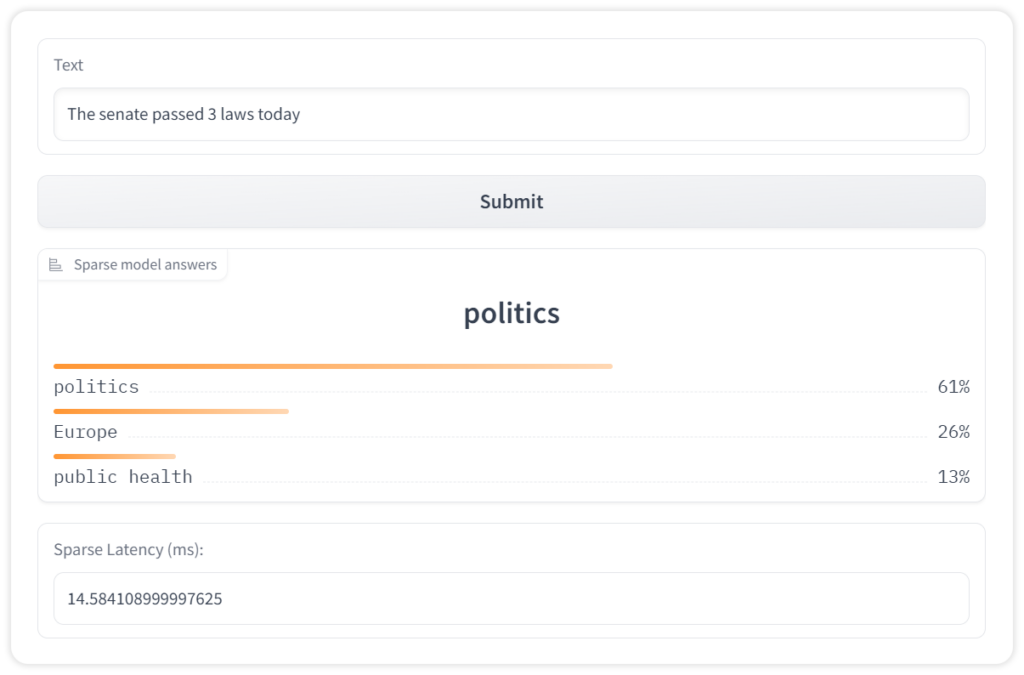
An example of text classification is classifying customer support queries accurately and directing them to the appropriate department, leading to fast query resolution. When deploying such a model, decreasing the latency and increasing its throughput is critical. This is where SparseZoo can be useful, as it provides optimized text classification models that you can prototype from, ultimately deploying on CPUs at GPU speeds, using DeepSparse.
Sentiment Analysis
Sentiment analysis determines whether a sentence is positive or negative. The sentiment analysis pipeline has pre-trained models and pre-processing steps, enabling you to pass raw text to the model.
Here is sample code for a sentiment analysis pipeline with DeepSparse:
from deepsparse import Pipeline
pipeline = Pipeline.create(task="sentiment-analysis", model_path="zoo:nlp/sentiment_analysis/bert-base/pytorch/huggingface/sst2/12layer_pruned80_quant-none-vnni")
text = "kept wishing I was watching a documentary about the wartime Navajos and what they accomplished instead of all this specious Hollywood hoo-ha"
inference = pipeline(text)
print(inference)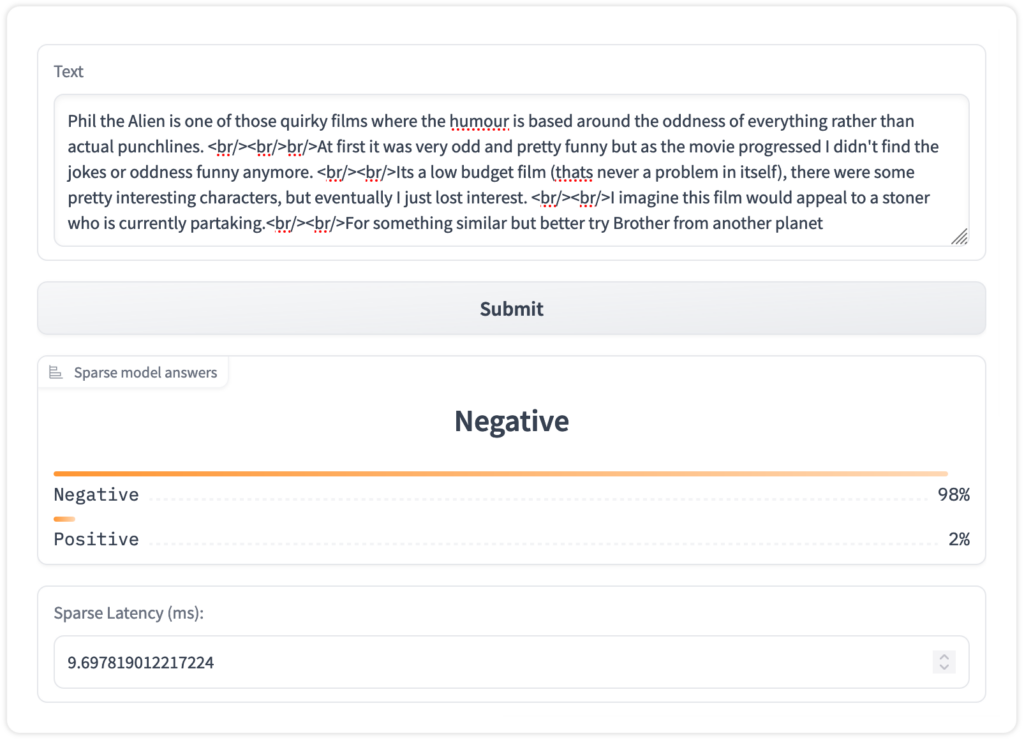
A use case for sentiment analysis is classifying the sentiment of customer reviews. Customer review classification is crucial for customer-facing enterprises across retail, entertainment, food, and beverage industries. Knowing what customers say about your product or solution can help you quickly address negative customer reviews, reduce churn and provide a better customer experience.
Final Thoughts
In this article, you have seen how to deploy CV and NLP models with DeepSparse for fast inference by picking compressed models from SparseZoo and deploying them on simple hardware such as a 2vCPU with 16GB RAM on Hugging Face Spaces. You have learned that you can deploy any model in the ONNX format using DeepSparse. You can also use SparseML to sparsify and quantize models on your private data and deploy them using DeepSparse.
SparseML reduces the size of CV and NLP models without losing accuracy. Deploying these models with DeepSparse leads to fast inference and high throughput. Join the Neural Magic Slack Community to ask questions about using state-of-the-art NLP and CV compression techniques or create an issue on GitHub.







