

Jan 04, 2023

Author(s)


In the Sparse Real-time Instance Segmentation post, you saw how to perform real-time segmentation on a laptop using YOLACT (You Only Look At CoefficienTs). You learned that image segmentation is applied in areas such as detecting a fruit, picking it up, and placing it in a bin. Image segmentation models can also:
- Detect defective items in a processing line.
- Be applied in scene understanding.
- Infer relationships between objects in autonomous driving.
Image segmentation—also referred to as semantic segmentation—is the task of assigning a label to each pixel in an image. In semantic segmentation, the label map represents the predicted category for each pixel. Instance segmentation goes a step further and tries to segment different instances of the same object. For example, in an image with many people, an image segmentation model will create the same mask over all the people, while an instance segmentation model will create separate masks for each person.
In this guide, you will learn about the inner workings of YOLACT, plus other image segmentation models. In addition to providing a history of these models, the guide describes implementation challenges and fast and efficient deployment options.
Image Segmentation Models
The computer vision space moves at a terrific speed. A model could be released today, and an advanced version of the same model could ship tomorrow. Because these advances tend to build on previous research, let’s look at the earliest segmentation models in 2015 and make our way to the most recent ones:
- 2015 - Fully Convolutional Networks (FCN), U-Net
- 2016 - SegNet
- 2018 - Mask R-CNN
- 2019 - YOLACT, FastFCN
- 2020 - PointRend, YOLOv5, YOLACT++
- 2022 - SparseInst
- 2023 - YOLOv8
2015 - Fully Convolutional Networks (FCN)
Fully convolutional networks (FCNs)—not to be confused with fully connected layers—are among the earliest models proposed for image segmentation. FCNs solve the semantic segmentation problem by replacing fully connected layers with convolutional layers, which act as the decoder.
The encoder layers are responsible for feature extraction and downsampling, while the decoder up-samples the image and generates a pixel-wise label map. Since the FCN encoders are for feature extraction, you can use existing object detection models such as VGG networks. FCN adapts classification networks such as VGG networks into fully convolutional networks and transfers their learned weights by fine-tuning them to the segmentation task.

A fully convolutional network is achieved by removing the final classification layer and converting all fully connected layers to convolutions. A 1-by-1 convolution is used to predict scores for each class. A deconvolution layer is then used for upsampling the outputs to dense outputs.
Several key features of the FCN architecture are that it:
- Can accept input of arbitrary size.
- Uses upsampling as the last step for decoding the image to the original resolution.
- Uses a 1D convolution instead of a flattened layer between the encoder and decoder.
- Uses skip connections to combine coarse and fine layer information to obtain accurate segmentation.
- Is used for pixel-wise segmentation, meaning that each pixel is placed in a specific class.
2015 - U-Net
The name, U-Net, is inspired by the shape of the architecture. The decoder and encoder layers in U-Net are symmetric, meaning they have the same number of layers arranged similarly. The number of up-sampling and down-sampling steps are equal.
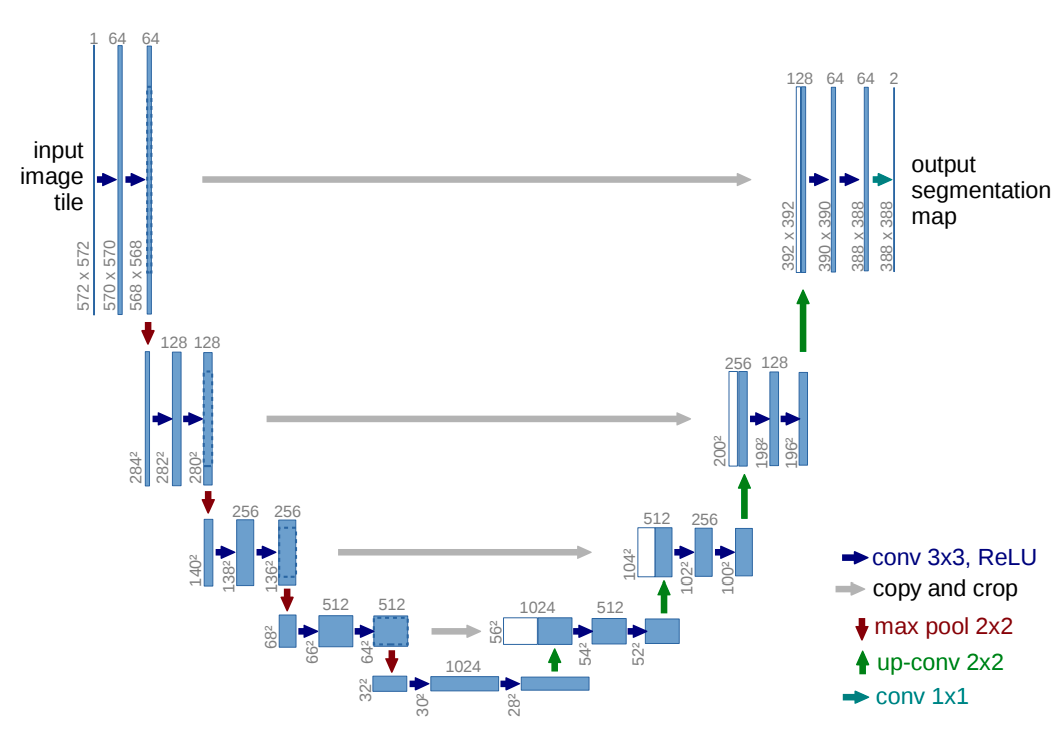
U-Net is a modification of FCN to work with a few training images and generate accurate segmentations. The architecture of U-Net consists of:
- A contracting path on the left.
- An expansive path on the right.
The contracting path comprises two 3-by-3 unpadded convolutions. Each convolution is followed by a rectified linear unit (ReLU). The ReLU is followed by a 2-by-2 max pooling with a stride of 2 for downsampling.
At each step in the expansive path:
- The feature maps are upsampled by a 2-by-2 convolution.
- The features channels are halved by the upsampling operation.
- The feature maps are concatenated with the respective cropped feature maps from the contracting path.
- Two 3-by-3 convolutions are followed by a ReLU.
U-Net is made up of 23 convolution layers. The network is trained using input images and their segmentation maps. The final layer in the network is a 1-by-1 convolution that maps each 64-component feature vector into the required number of classes.
2016 - SegNet
SegNet is an image segmentation model similar to FCN. SegNet is convolutional. Hence it uses no fully connected layers. SegNet was built for memory efficiency and less computational time at inference. It was motivated by scene-understanding applications. Unlike FCN, SegNet has trainable decoder filters.
SegNet, like U-Net, is symmetric. The first layers in the encoder are two convolution layers followed by a pooling layer. The two last layers in the decoder consist of an upsampling layer followed by two convolution layers. The architecture of the encoder is similar to the VGG-16 network with the fully connected layers discarded. Hence the SegNet encoder network has 13 convolutional layers. Training the SegNet model, therefore, can be done using the VGG weights trained for object classification.
The SegNet encoder:
- Produces feature maps through convolution using a filter bank.
- Batch normalizes the feature maps.
- Applies an element-wise rectified linear non-linearity (ReLU).
- Has a max-pool with a 2-by-2 window and non-overlapping stride of 2.
- Sub-samples the result obtained above by a factor of 2.
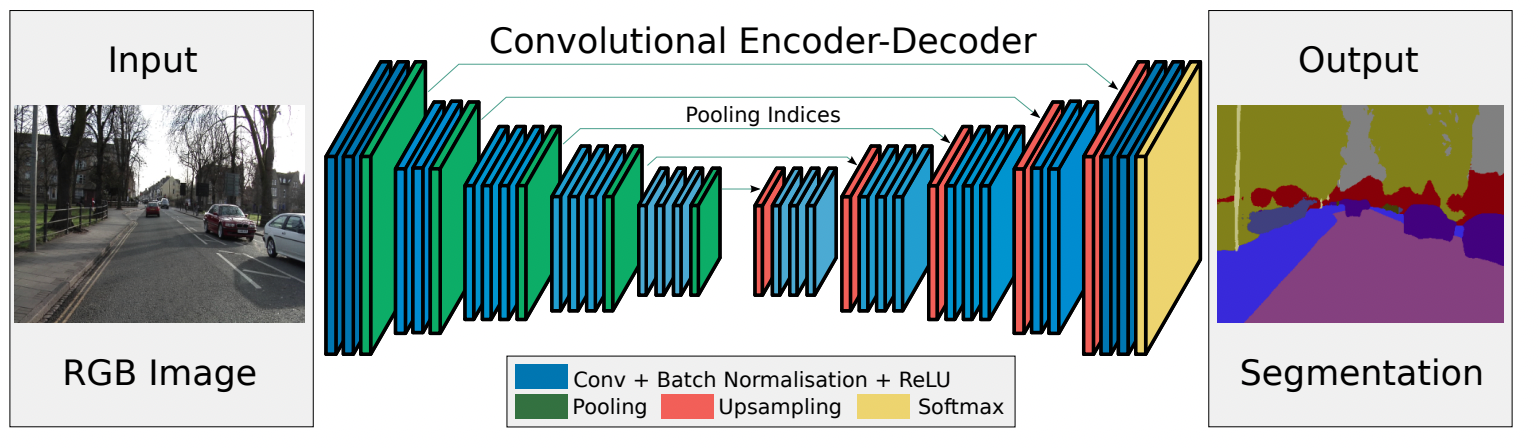
Low-resolution feature maps from the encoder are mapped to full input resolution feature maps by the decoder for pixel-wise classification. SegNet introduced a new way for the decoder to upsample the low-resolution feature maps. The decoder performs non-linear upsampling using pooling indices calculated in the max-pooling step of the corresponding encoder. The max-pooling indices represent the location of the maximum feature value in each pooling window. 2-bit operations are done for each 2-by-2 pooling window, resulting in lower memory storage at slightly less accuracy.
Reusing the max-pooling indices in the decoding process leads to:
- Improved boundary delineation.
- End-to-end training by reducing the number of parameters.
- An upsampling technique that can be included in any encoder-decoder architecture.
Passing the input feature maps to the decoder produces sparse feature maps. The sparse upsampled maps obtained from the decoder are convolved to generate dense feature maps. Each of these feature maps is then passed through a batch normalization step.
The decoder is followed by a multi-class soft-max classifier for pixel-wise classification. The classifier produces class probabilities for each pixel independently.
2018 - Mask R-CNN
Mask R-CNN is an extension of Faster R-CNN for instance segmentation by adding a branch to predict a segmentation mask for each region of interest (RoI). Segmentation masks are predicted pixel-to-pixel by an FCN—the mask branch. However, the addition of a mask branch adds computational overhead.
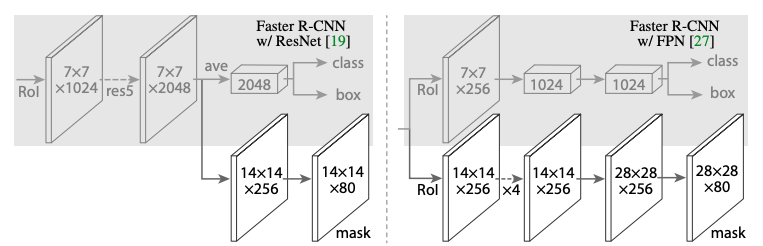
As an extension of Faster R-CNN, Mask R-CNN has three branches:
- Branch for predicting the class label for each object.
- Bounding-box offset branch.
- Object mask prediction branch.
To enable extraction of finer spatial object layout that enables mask prediction, Mask R-CNN incorporates pixel-to-pixel alignment.
Briefly, Faster R-CNN works in two stages. It:
- Uses a region proposal network (RPN) to propose object bounding boxes.
- Extracts features from the boxes and performs bounding box regression and classification using Fast R-CNN.
In Mask R-CNN, a binary mask for each RoI is generated in parallel to the prediction of the class and bounding box offset.
2019 - YOLACT
Real-time instance segmentation has applications in areas such as manufacturing, where detecting defective items in the processing line is critical. Real-time instance segmentation requires accuracy and speed. YOLACT was introduced to achieve this.
YOLACT is a one-stage instance segmentation model like YOLO and SSD for object detection. This means that, unlike Mask R-CNN, YOLACT doesn’t start by creating Regions of Interest (RoI) and then segmenting them. Re-pooling features for each ROI in two-stage networks makes them slower. Hence, one-stage detectors such as YOLACT are faster.
YOLACT works in two parallel steps that make it fast:
- Generating a set of prototype masks.
- Predicting per-instance mask coefficients.
YOLACT produces instance masks by linearly combining the prototypes with the mask coefficients.

YOLACT is similar to Mask R-CNN in that it uses an existing one-stage object detector and adds a mask branch. The YOLACT architecture comprises the following components:
- Feature backbone, a ResNet-101 with a feature pyramid network (FPN), for generating high-quality features.
- Feature pyramid for creating pyramids of high-resolution image feature maps.
- Protonet for generating mask prototypes using the FCN backbone.
- Prediction head, an FCN that predicts the class score and bounding box.
- Non-maximum suppression (NMS) to ensure that overlapping bounding boxes are ignored.
- Mask coefficient head for predicting mask prototype coefficients.
- Mask assembly where final instance masks are linearly combined with the coefficients from the prediction head and mask coefficient branch. The result is passed to a sigmoid function to generate the final mask.
- Crop and threshold that crops the final masks and passes them through a threshold—intersection over union (IoU) thresholding.
2019 - FastFCN
FastFCN proposes a new way of generating high-resolution feature maps for semantic segmentation. Unlike other models that use dilated convolutions, FastFCN introduces a joint upsampling module named Joint Pyramid Upsampling (JPU). The JPU method reduces computation complexity and memory footprint.
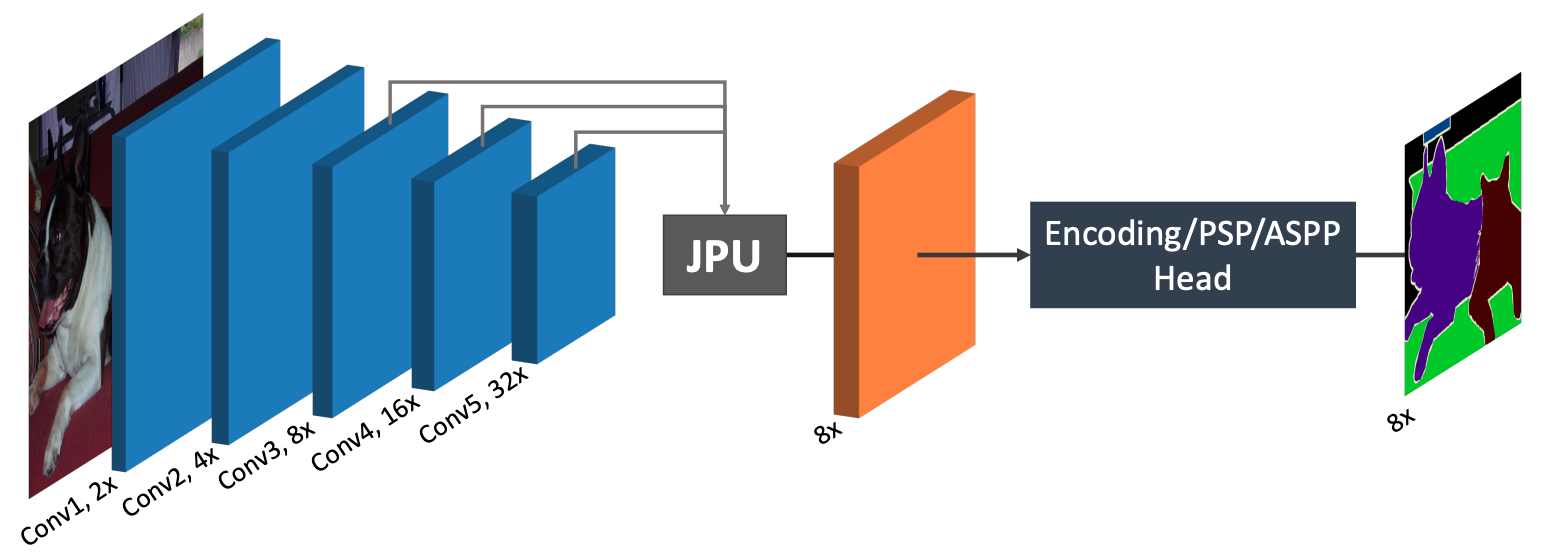
FastFCN uses the original FCN as the backbone, and uses the JPU to upsample the low-resolution final feature map and generate a high-resolution feature map. Joint upsampling works by transferring structures from a guidance image to generate a high-resolution image. The JPU takes the last feature maps—conv3, conv4, and conv5—as input. After that, a global context module generates the final predictions.
2020 - PointRend
PointRend (Point-based Rendering) performs point-based segmentation predictions. The network can be used for both instance and semantic segmentation tasks. PointRend can be applied as a mask head in Mask R-CNN and other segmentation methods.
PointRend receives one or more CNN feature maps from regular grids and outputs high-resolution predictions over a finer grid. As shown below, PointRend performs better on boundaries than other methods, such as Mask R-CNN.
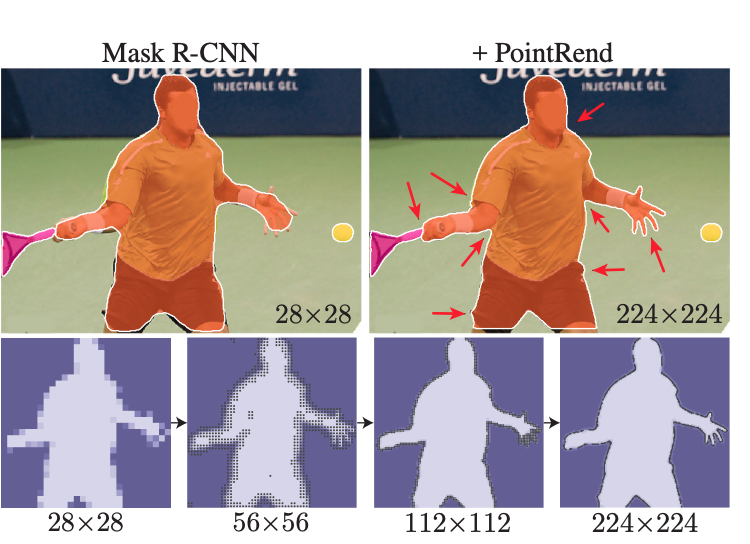
The PointRend architecture comprises:
- A CNN backbone such as ResNet.
- Coarse prediction model that generates a k-dimensional vector for each sampled point in the region. This represents a bounding box for each instance.
- Fine-grained features obtained from layers of the backbone that provide rich feature information.
- Concatenation of fine-grained and coarse prediction vectors.
- Multi-layer perceptron with three hidden layers and 256 channels.

PointRend works in the following way:
- A point selection strategy is used to make predictions after selecting a small number of points, avoiding expensive computation.
- A point-wise feature representation is extracted for each point.
- A point head network predicts a label for each point from the point-wise feature representation.
PointRend is less computationally expensive because it uses a sample of the points in the image. It can also generate higher-quality masks compared to Mask R-CNN.
2020 - YOLOv5
YOLOv5 is an object detection model in the You Only Look Once (YOLO) family by Ultralytics. YOLOv5 translated the model from Darknet to PyTorch. YOLOv5 uses data augmentation strategies, such as mosaic augmentation, that help in accurately detecting small objects. Porting the model to PyTorch also enabled training and inference in lower precision, speeding up inference and training.
YOLOv5 uses a cross stage partial networks bottleneck to generate image features and a PA-Net neck for feature aggregation. In its latest version, YOLOv5 v7.0, YOLOV5 now supports instance segmentation.
2020 - YOLACT++
YOLACT++ is a fully-convolutional real-time instance segmentation model that uses deformable convolutions (DCNs) in the backbone network.
YOLACT++ replaces 3-by-3 convolution layers in each ResNet block with a 3-by-3 deformable convolution layer. A DCN interval of 3 is chosen to strike a balance between speed and performance. The introduction of deformable convolutions leads to:
- More flexible feature sampling.
- Enabling the network to handle instances with different scales, aspect ratios, and rotations.
Like YOLACT, YOLACT++ works by:
- Generating a set of prototype masks.
- Predicting per-instance mask coefficients.
- Creating instance masks by linearly combining the prototypes with the mask coefficients.
YOLACT++ also introduces a new Fast Mask Rescoring Network that leads to better performance by re-ranking the mask predictions according to their mask quality. Rescoring the predicted masks is done based on their IoU with ground truth.
The Fast Mask Rescoring Network comprises a 6-layer FCN with ReLU per convolution layer and a global pooling layer. The network accepts YOLACT's cropped mask prediction and generates the mask IoU for each class object. Rescoring is done by calculating the product of the predicted mask IoU and the classification confidence.
2022 - SparseInst
Sparse Instance Activation for Real-time Instance Segmentation (SparseInst) is a fully convolutional network that uses sparse instance activation maps (IAMs) to identify informative regions of objects for recognition. Unlike other networks, such as YOLACT, it doesn’t apply non-maximum suppression (NMS).
The architecture of SparseInst is made up of:
- A backbone (for example, ResNet) for extracting image features.
- An encoder that uses a pyramid pooling module (PPM) to enhance the multi-scale representation for single-level features.
- An IAM-based decoder for computing instance activation maps and performing recognition and segmentation.
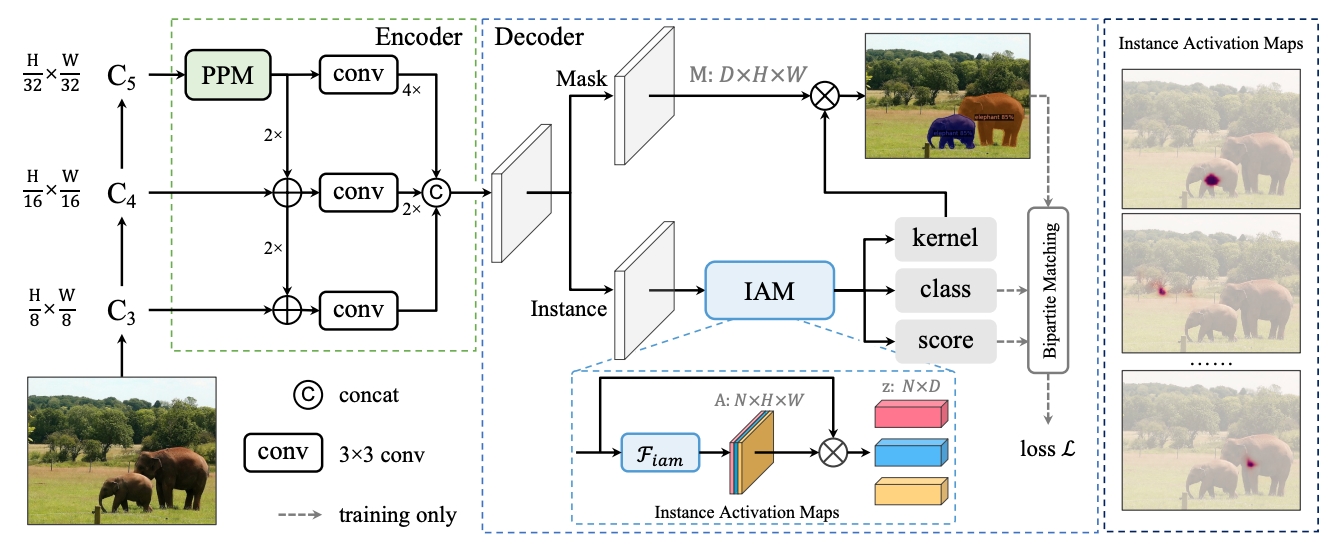
The IAM-based decoder has an instance branch and a mask branch. The instance branch generates instance activation maps while the mask branch encodes instance-aware mask features.
2023 - YOLOv8
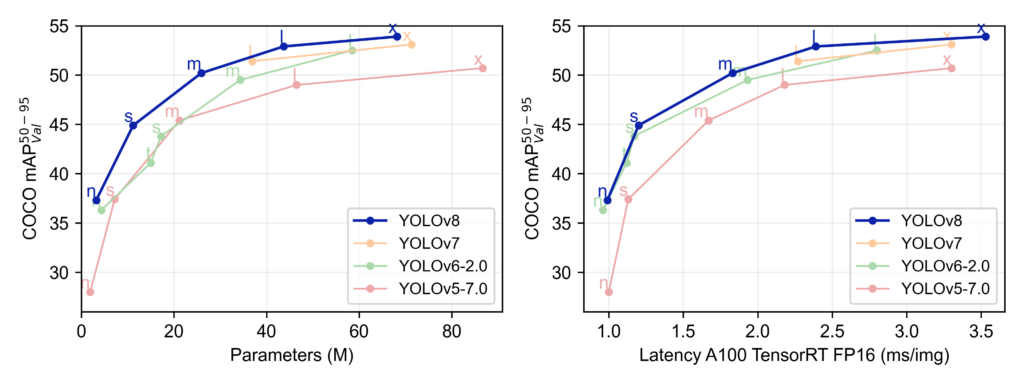
YOLOv8 is the latest edition in the YOLO family by Ultralytics and is an upgrade to YOLOv5. Support for image segmentation as well as object detection and image classification continues. New capabilities have been released to improve performance, versatility, packaging, and the overall developer experience. For example, while the previous version depended on scripts for installation, the latest version can be installed via a PIP package (and from source). The YOLOv8 repository has the comprehensive documentation to get you started. And great news, DeepSparse and YOLOv8 deployment is a winning combination! You will see that YOLOv8 is an excellent alternative because of its ability to scale.
Current Challenges in Implementing Image Segmentation Models
Applying the models mentioned above in practice is still challenging despite these image segmentation advances. Particularly, these models:
- Have to be smaller to enable deployment even on edge devices.
- Offer fast real-time inference.
- Have to be affordable to deploy.
Let’s look at these challenges in more detail.
Model Size
Computer vision models are usually large and give decent results in real-world applications. However, the model size makes it challenging to deploy the models. For example, you can’t deploy a model that is several gigabytes on mobile—it will take longer to download the model on the device, and mobile devices have little storage. You could decide to deploy the model via an API endpoint at the expense of lower latency.
Deployment Difficulty
What if there was another way? You can make the model smaller to make it easy to deploy. This can be achieved by sparsifying the model. Neural networks are usually over-precise and over-parameterized. You can make the model smaller by removing redundant weight connections and reducing the model's precision.
Model sparsification can be achieved using SparseML, which decreases the model size without affecting its accuracy. Reducing the model's size also speeds up inference, which is crucial for implementing real-time image segmentation and deployment on the edge. Fortunately, you don’t need to sparsify these models. You can pick an already sparsified model from SparseZoo.
GPU Compute Expense
Large computer vision models usually require expensive GPU hardware to train and deploy. GPUs are fast and powerful but also are specialized, have short lifespans, and consume a lot of electricity. CPUs are cheap and readily available. What if you could achieve GPU-class performance on commodity CPUs? Enter DeepSparse.
DeepSparse enables fast inference of models on CPUs by utilizing the CPUs' fast and large caches. It uses sparsity to reduce the need for flops, leading to low latency and high throughput. Furthermore, DeepSparse is environment agnostic, enabling deployment on-premise, in the cloud, or at the edge. DeepSparse also enables you to reduce compute costs by deploying to CPUs instead of GPUs.
Image Segmentation Deployment Options
Using DeepSparse is the fastest way to deploy image segmentation models. DeepSparse leverages its tensor column infrastructure and sparse models to achieve faster inference and higher throughput.
For example, you can deploy the YOLACT Pruned Quant model from SparseZoo. This model has 82.8% of its weights removed, after which it has been quantized. The model size is 9.7MB compared to 170MB for the original. The model has a 28.2 mAP compared to 28.8 for the original model; hence sparsifying and quantizing the model does not affect its performance.
You can use the DeepSparse annotate command to save an annotated photo on disk.
deepsparse.instance_segmentation.annotate --source fruits.jpg

Final Thoughts
There are numerous image segmentation models from which to choose. The choice will depend on your use case. That notwithstanding, you will always want a model that is easy to deploy and faster at inference. For instance, you will need a model that can make inferences in real time for applications such as people counting and autonomous cars.
For real-time applications, you will also be concerned with FPS and the compute required to run inference. This article showed that you can deploy image segmentation models for rmeal-time inference on CPUs using DeepSparse while achieving GPU-class performance.
Give it a shot now, and let us know how it goes. Create a PR or send us a message in our community Slack if you need any help along the way. We can’t wait to see all the cool applications you deploy using DeepSparse.







