

May 09, 2024

Author(s)


70% Sparsity, Full Accuracy Recovery—Unlock the power of smaller, faster LLMs with our latest foundational research, enabling up to 8.6X faster and cheaper deployments
AI at a Cost: The Efficiency Challenge
Large language models (LLMs) drive unprecedented innovation across content creation, customer support, content summarization, and more. Yet this powerful technology comes with significant costs—even smaller LLMs are far larger and more energy-intensive than previous deep learning models. LLMs translate to incredible applications that equate to hefty deployment expenses and require power-hungry hardware such as A100 GPUs or large CPU servers. Companies commit thousands of dollars a month to keep them running for even the smallest workloads.
Given these size issues, quantization – which reduces a model's precision and, therefore, size – seemed like the holy grail. Researchers and practitioners embraced this technique to achieve significant savings of 3X on average. However, research innovations have stalled around 4-bit quantization, after which accuracy suffers significantly. This puts organizations in a position where they have to make a difficult choice: deploy inaccurate models that offer little value or continue scaling the expensive, energy-intensive infrastructure, which is a costly and ultimately unsustainable path.
Sparsity: The Next Frontier
Fortunately, a promising path through pruning exists, which removes unimportant connections within a network, resulting in sparsity. After initial training, many weights, once essential for exploring the optimization space, become unused as the model converges to a stable solution. Recent research breakthroughs allow us to remove them for significant compression, especially when combined with quantization, without affecting accuracy. This ability to prune LLMs opens a new dimension for model optimization, for potentially exponential gains in performance when paired with the proper hardware and software.
We removed nearly 5 billion parameters from the 7 billion available ones, with full accuracy recovery."
In collaboration with Cerebras and IST Austria, Neural Magic’s latest paper, Enabling High-Sparsity Foundational Llama Models with Efficient Pretraining and Deployment, introduces the first technique to achieve high sparsity levels in foundational LLMs, specifically 50% and 70%, across diverse, challenging, and actively deployed tasks. We removed nearly 5 billion parameters from the 7 billion available ones, with full accuracy recovery. This research translates into direct cost savings for open-source users and enterprises, making model deployment up to 8X cheaper and saving thousands of dollars monthly for customers, even for limited implementations.
Our Breakthrough Results
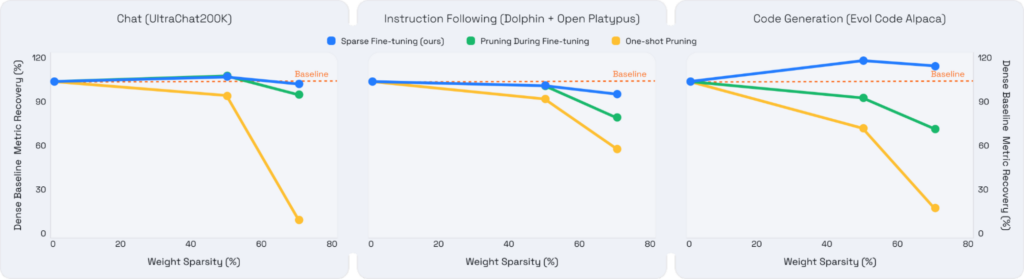
In our breakthrough research, we successfully created highly efficient sparse and sparse-quantized Llama 2 7B models. These models demonstrate unprecedented accuracy recovery, matching their dense counterparts, even at higher sparsity levels. We further optimized our software and hardware platforms for training and serving these sparse models to deliver exceptional speedups on various hardware platforms.
Our key achievements include:
- Sparse foundational models with full recovery - We developed sparse, foundational models that recover full accuracy at sparsity levels ranging from 50% to 70% for the most popular and actively deployed LLM tasks, including Chat, Instruction Following, Code Generation, and Summarization.
- Practical speedups for training and inference - We accelerated training with close to theoretical gains utilizing Cerebras's CS-3 AI accelerator, significantly reducing research experimentation and training times.
- Compounding gains with quantization - We proved the effectiveness of combining sparsity and quantization. That allowed for independent scaling of both techniques for further improvements and compounding their gains, resulting in better performance of up to 8.6X.
- We achieved up to 3X better inference performance on CPUs from sparsity alone with Neural Magic's inference server, DeepSparse,
- We demonstrated up to 1.7X inference speedups on GPUs from sparsity alone with Neural Magic's enterprise inference server, nm-vllm.
Accelerated Training with Cerebras: A Game-Changer for Research and Development
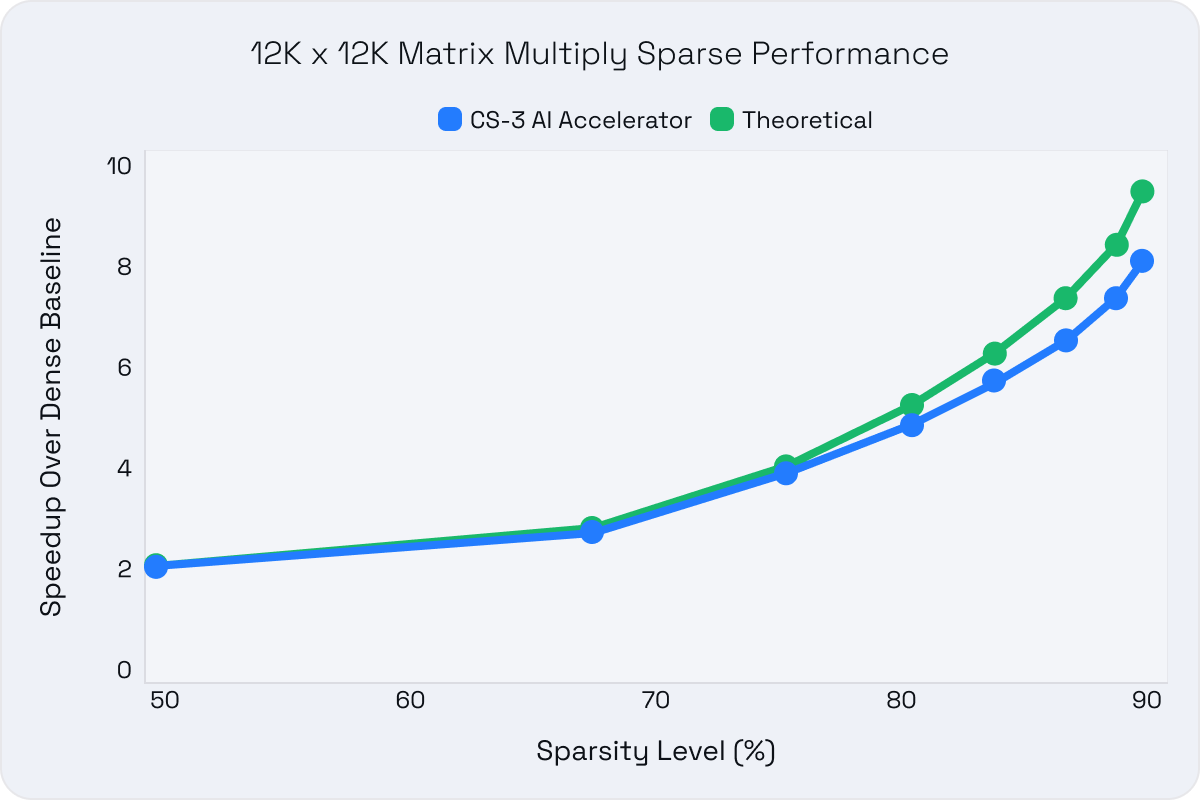
To fully explore the possibilities of sparse LLMs, we performed our work on 8x Cerebras CS-3 AI accelerators. Unlike GPUs, which only provide a fixed 2:4 sparsity pattern, Cerebras hardware is fully programmable for any sparsity pattern at an arbitrary sparsity level, making it the ideal platform for ML research and training. The CS-3’s 44GB of on-chip memory and over 1 Petabyte of external memory significantly reduces training time and training code complexity, allowing researchers to iterate faster, experiment more freely, and uncover novel techniques impossible on GPUs. These benefits are especially valuable for enterprises who want to customize models for specific use cases, as they drastically reduce the time-to-market for new AI applications and are core for us when we create our sparse, foundational models.
Performant Deployments with Neural Magic: Democratizing Access to LLMs
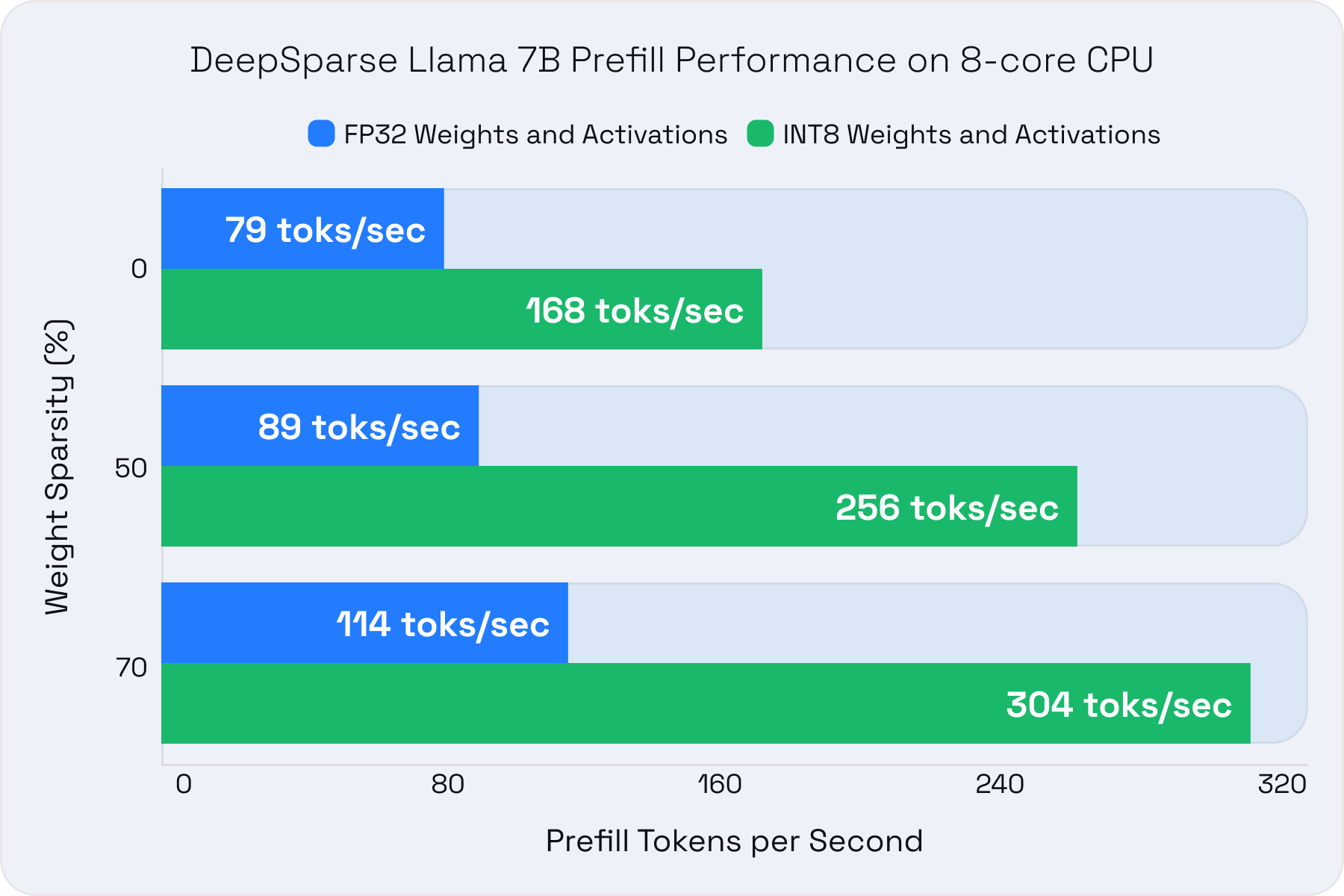
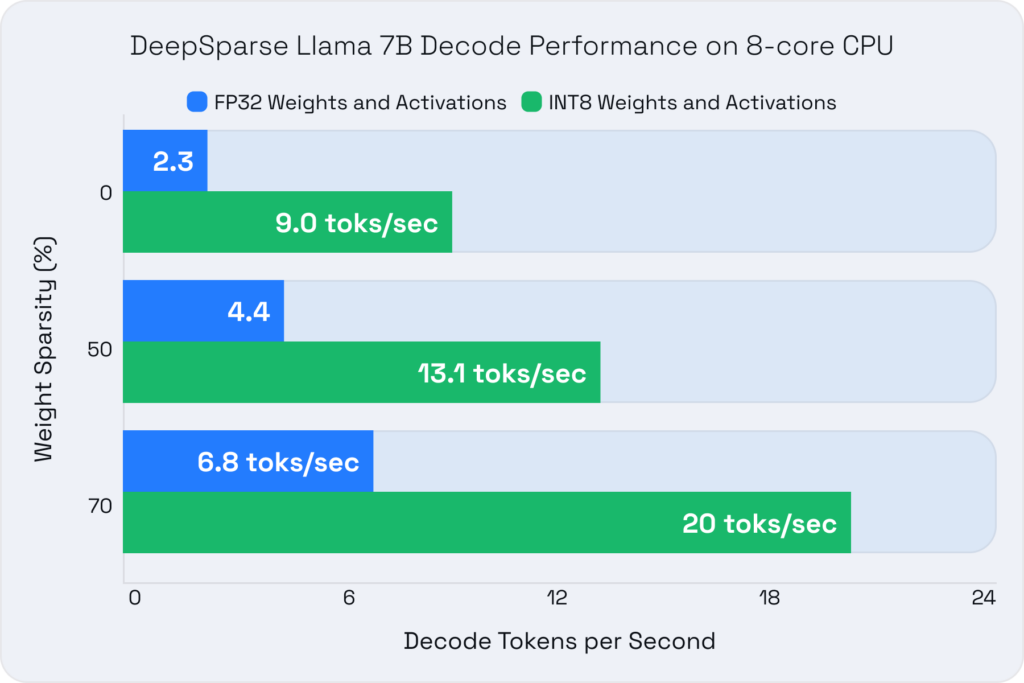
Our inference optimizations within DeepSparse and nm-vllm are equally transformative. Both inference servers are engineered for the fastest performance across generally available hardware for sparse and dense models alike. The increase in performance translates to cost savings through smaller deployments at the same accuracy or larger models on your current deployment infrastructure at higher accuracy. This flexibility reduces costs and expands the potential applications of LLMs, making them more accessible to businesses and individuals with limited resources. As mentioned above, Neural Magic’s software stack can save organizations thousands of dollars monthly, even for small deployments.
Overcoming Past Challenges
Previous attempts to create sparse LLMs faced significant challenges, particularly when maintaining accuracy at high sparsity levels and for complex tasks like chat and code generation. While promising, one-shot pruning and pruning during fine-tuning often fell short in these areas.
To address these limitations, we developed a novel approach that combines targeted pruning with sparse pretraining. We first employed the SparseGPT algorithm to identify and remove less impactful weights to reduce the Llama 2 7B model to 50% and 70% sparsity while preserving essential information.
Crucially, we retrained these sparse models on a carefully selected subset of pretraining data. This step allowed the sparse models to "relearn" critical patterns and relationships to recover the accuracy lost during pruning. The sparse, pretrained models, combined with state-of-the-art distillation techniques during fine-tuning, enabled the impressive results we highlighted above. This combined approach resulted in sparse foundational Llama 2 7B highly accurate and efficient models to open up new avenues for developing and deploying powerful LLMs.
Conclusion
This research signifies a paradigm shift in the development and deployment of LLMs. We're unlocking a new era of affordable and sustainable AI by overcoming previous limitations in sparsity and accuracy. Our sparse and sparse-quantized Llama 2 7B models deliver unparalleled accuracy recovery at high sparsity levels, proving that powerful language models don't have to come at a premium cost or excessive energy consumption.
The acceleration achieved through sparse training on Cerebras CS-3 systems, combined with efficient inference using Neural Magic's DeepSparse and nm-vllm, will drive rapid innovation and expand the accessibility of LLMs. This research opens doors for groundbreaking applications, from resource-constrained environments to large-scale enterprise deployments. We envision a future where powerful language models are more affordable and environmentally sustainable.
Our journey doesn't end here. Our team is committed to pushing the boundaries of sparse LLM research further. We are actively exploring the application of our techniques to larger and newer models, investigating new sparsity structures and pruning algorithms, and refining quantization methods to achieve even more significant compression and performance.
Access Our Research and Models
We invite you to join us on this exciting journey. Explore our open-sourced models on the Hugging Face Model Hub, dive into our comprehensive documentation, and leverage our research to build the next generation of AI solutions. Together, we can shape a future where AI is not only powerful but also accessible, efficient, and sustainable.







