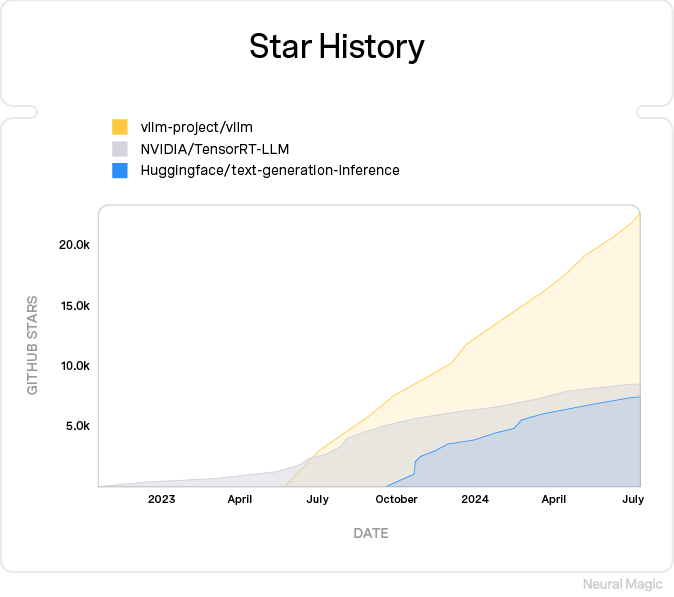




vLLM is the leading open-source LLM inference server.
Strategy
Why vLLM
vLLM is the leading community-developed open-source LLM inference server started by UC Berkeley in June of 2023.
The base of developers continues to expand and includes a broad set of commercial companies, of which Neural Magic has become a top contributor and maintainer.
It’s performance and ease-of-use has attracted a growing base of users globally.