
How it Works
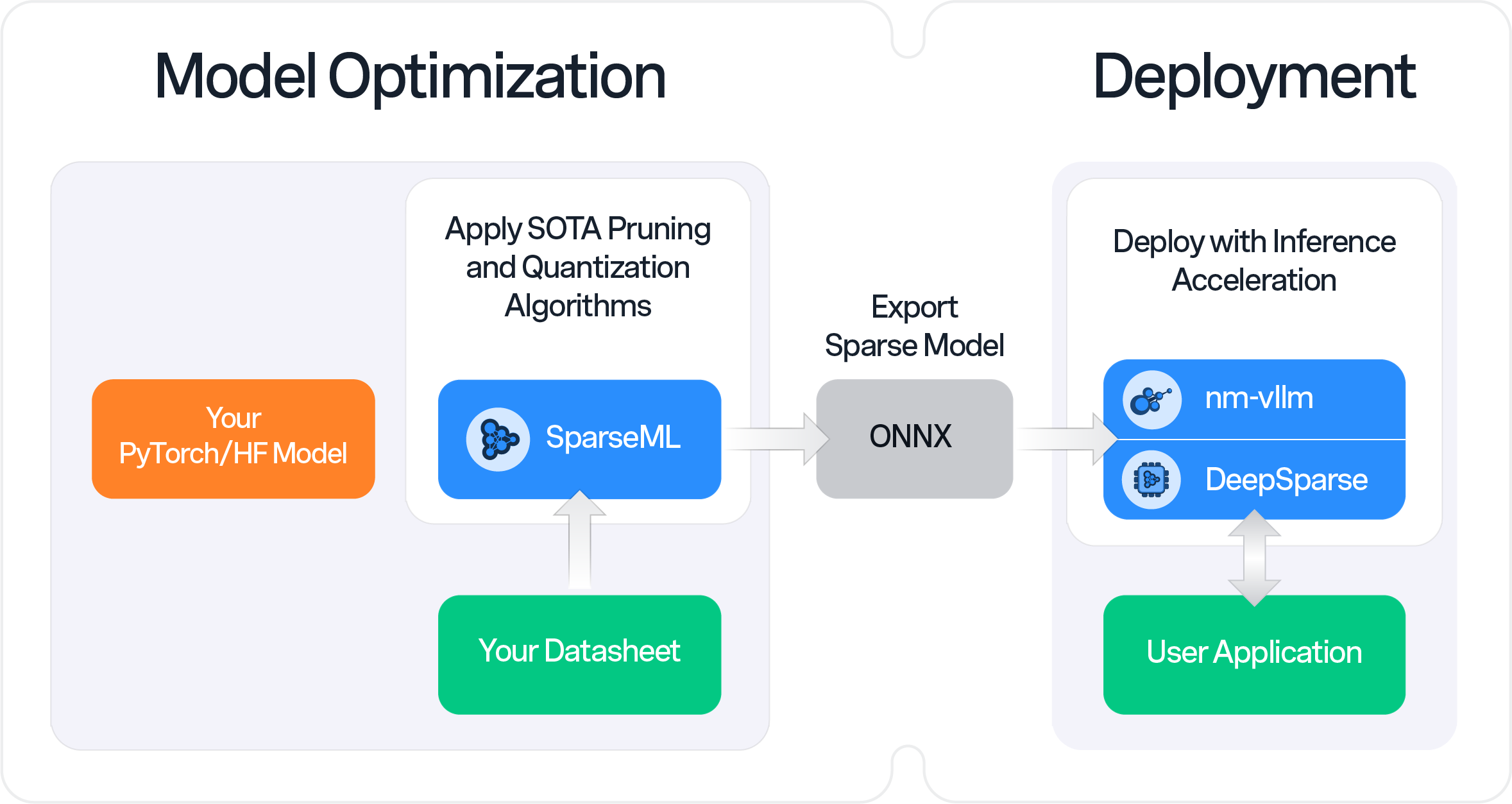
Optimize Your Models for Inference
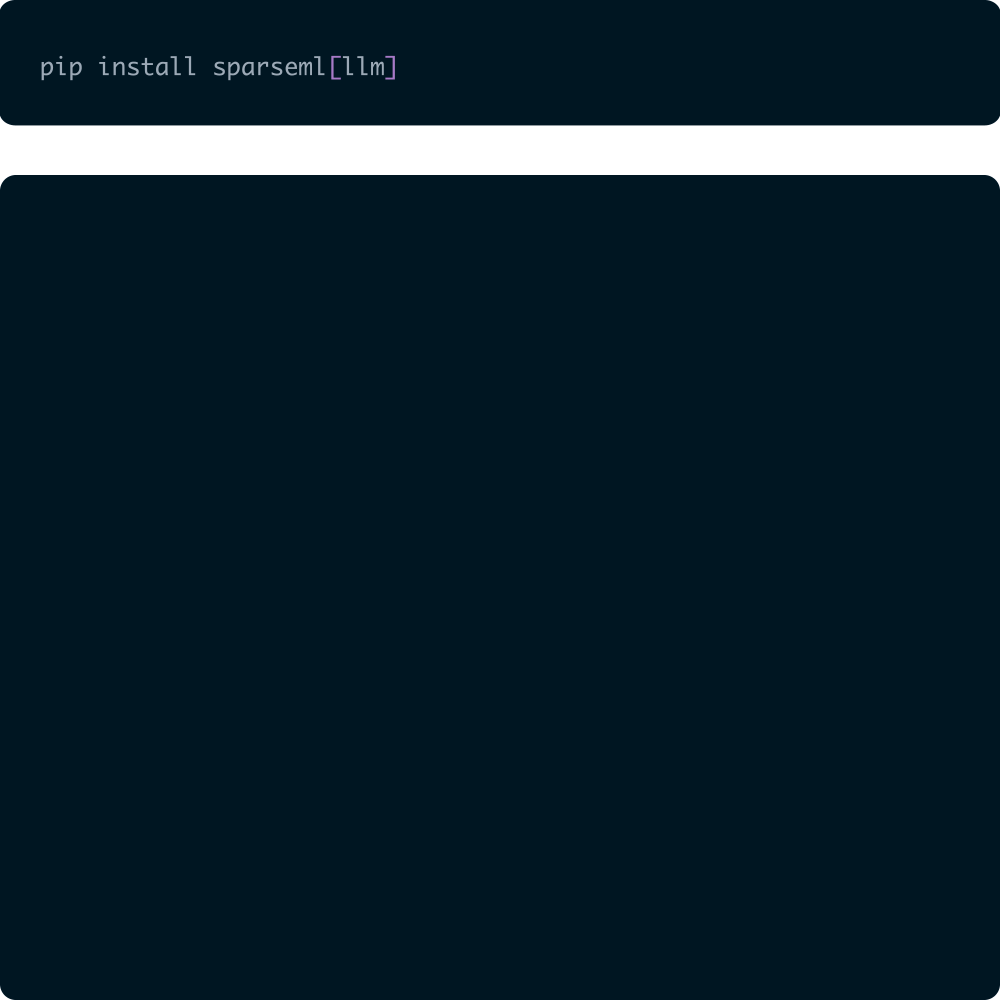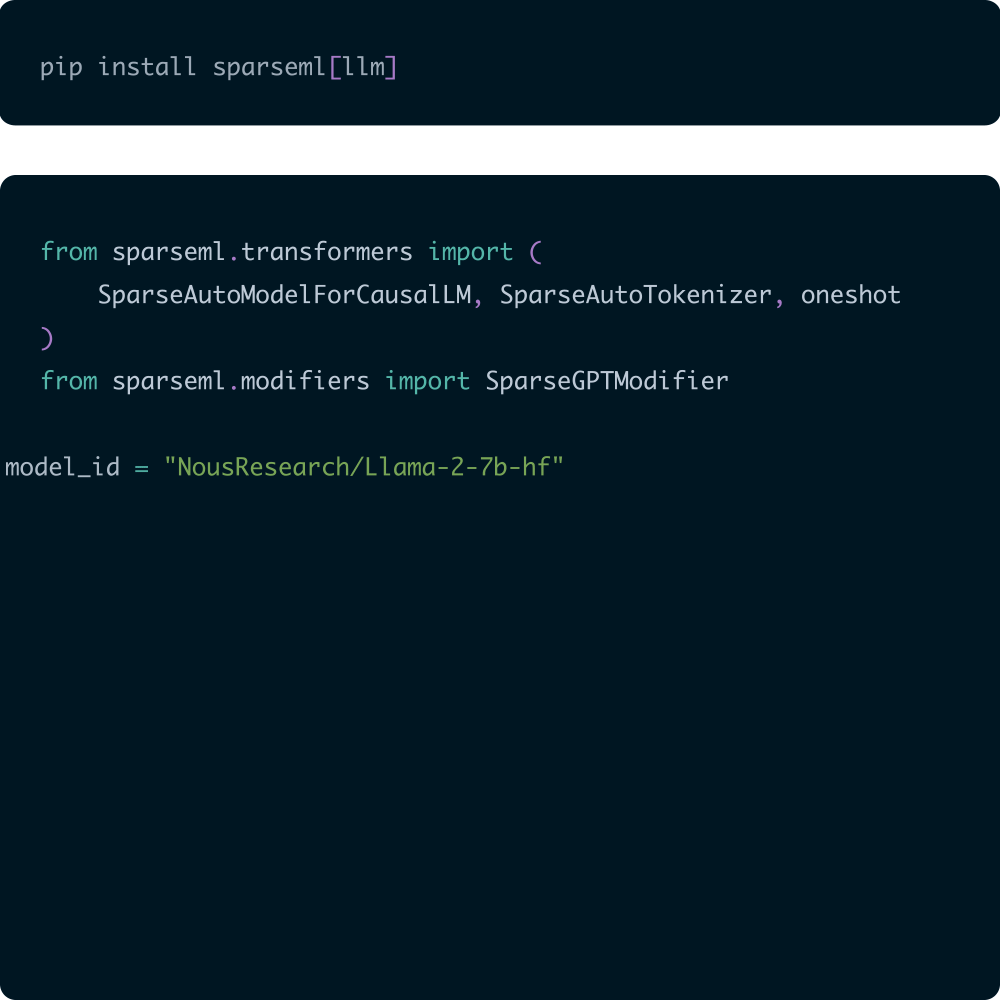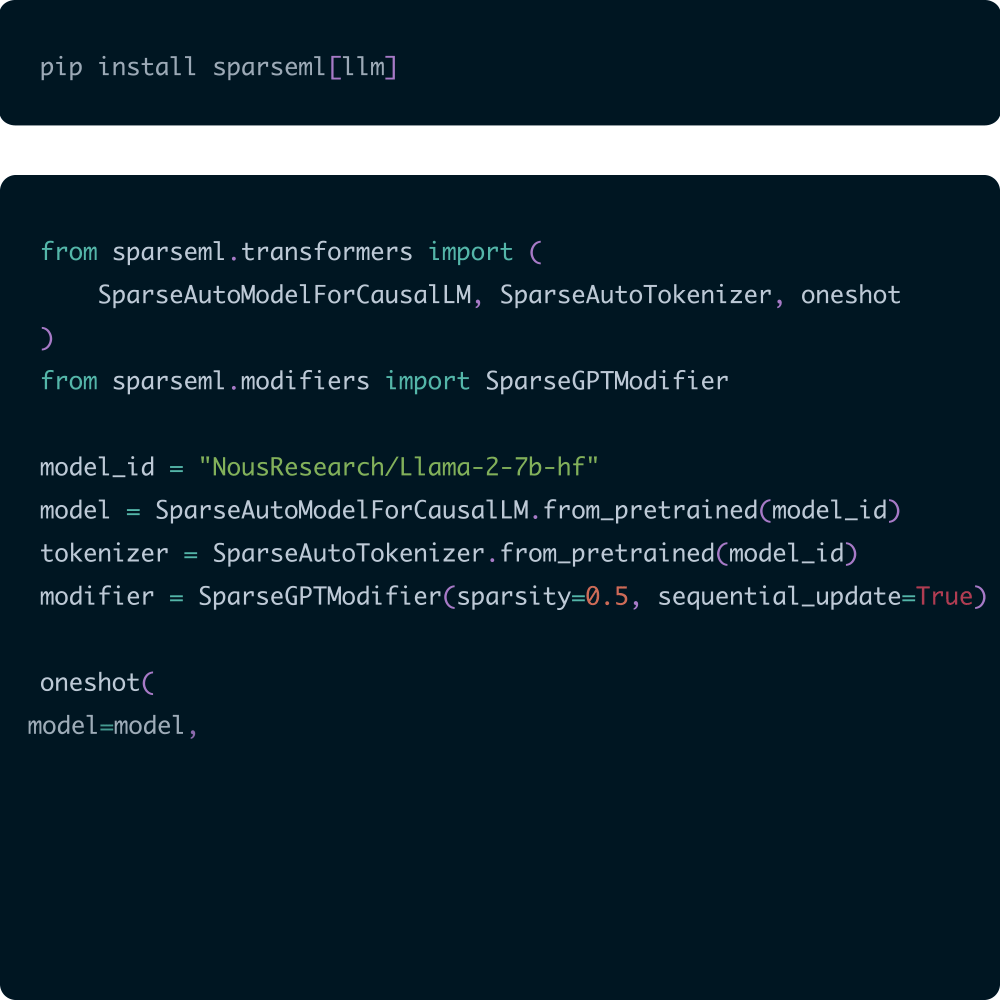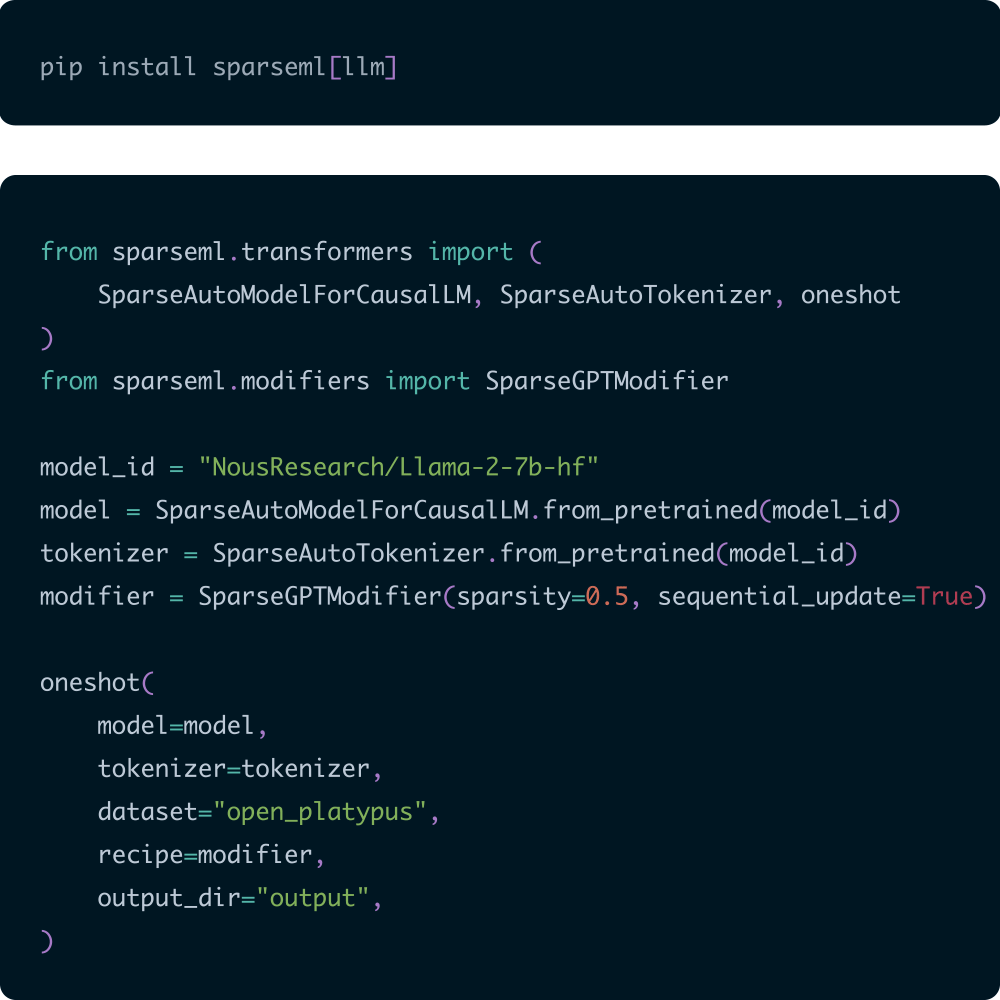
SparseML enables you to create inference-optimized models using state-of-the-art pruning and quantization algorithms.
Models trained with SparseML in PyTorch can then be exported and deployed with nm-vllm and DeepSparse.