

Jan 25, 2023

Author(s)



Object detection is a crucial task in computer vision. With applications in fields such as image and video analysis, robotics, and autonomous vehicles, object detection involves identifying and locating objects within an image or video. Traditionally, it has been tackled using various techniques, including edge and corner detection, template matching, and machine learning-based approaches.
In recent years, deep learning has emerged as a powerful tool for object detection, leading to significant improvements in accuracy and efficiency. In this comprehensive guide, we explore the modern deep learning-based approaches used for object detection.
We begin by discussing the basics of object detection, including the different types of techniques and their relative strengths and weaknesses. We then delve into the most popular and effective methods, including YOLO, SSD, and R-CNN, to examine their underlying principles and see how they are applied in practice.
We also address common challenges and issues in object detection, and explore ways to overcome them. By the end of this guide, you will have a thorough understanding of object detection with the knowledge to apply these techniques in your projects.
Object Detection Models
Before diving into the models, let’s review some object detection basics.
Object detection models aim to localize objects in an image and draw a bounding box around them. Modern object detection models comprise three key components:
- The backbone for feature extraction
- The neck for feature aggregation
- The head for making the predictions
Object detection models are evaluated using intersection over union (IoU) and average precision (AP). The IoU is computed from the intersection of the ground truth bounding boxes and predicted boxes. The AP is the area under the precision-recall curve (AUC-PR). AP50, as seen in many papers, is the average precision calculated at a 50% IoU threshold.
With that brief introduction, let's dive into some object detection models and how they work. It is important to “look back” to understand how the current object detection systems work. So, we’ll start in 2014 (R-CNN) and make our way to the most recent models in 2023 (YOLOv8).
2014 – Region-based Convolutional Neural Network (R-CNN)
In 2014, researchers from UC Berkeley introduced the R-CNN model that would play a pivotal role in later models. Using region proposals with convolutional neural networks (CNNs), the model:
- Accepts an input image and extracts about 2000 category-independent region proposals––candidate object locations.
- Computes fixed-length CNN input using affine image wrapping.
- Passes the fixed-length CNN input to a large convolutional neural network to extract fixed-length feature vectors for each proposed region.
- Classifies each region using class-specific linear SVMs.
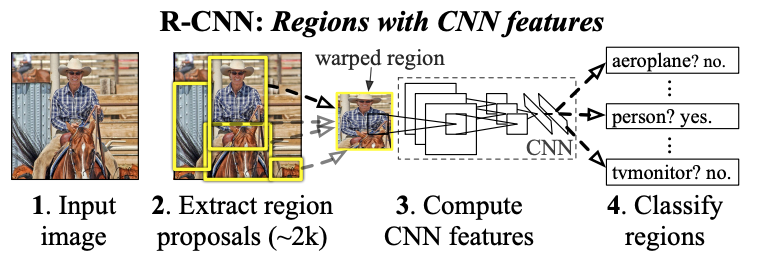
Region proposals are generated using selective search. A 4096-dimensional feature vector is then extracted from each regional proposal using a CNN. A mean-subtracted 227 × 227 RGB image is propagated through five convolutional layers and two fully connected layers to compute the features.
Bounding boxes are predicted after each selective search proposal. The model is then trained via supervised pre-training and adapted for the detection task through fine-tuning. At inference, the model applies non-maximum suppression to reject regions that don’t meet the set threshold.
As an early model in the object detection space, R-CNN came with a set of challenges:
- Training is a multi-stage process, including generating region proposals, computing CNN features, and classifying the regions.
- Training is expensive and time-consuming because of large convolutional neural networks.
- Object detection is slow because of the forward pass for each object proposal.
2015 – Fast R-CNN
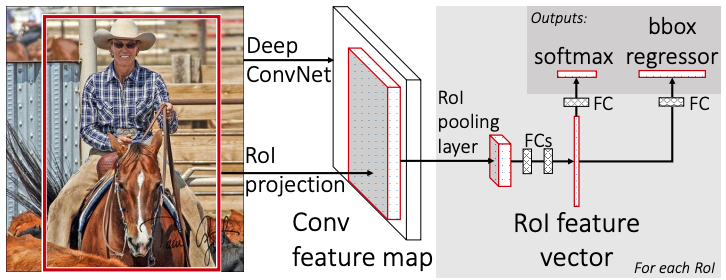
The Fast R-CNN model builds on R-CNN to––you guessed it––produce a faster object detection model. Unlike R-CNN, Fast R-CNN is a single-stage detector. It:
- Takes in an image and a set of object proposals––regions of interest (RoIs).
- Processes the image using convolutional and pooling layers to produce a feature map.
- Extracts a fixed-length feature vector for each object proposal from the feature map using an RoI pooling layer.
- Feeds the feature vector to fully connected layers.
- Generates two outputs per RoI. One is the softmax probability estimates over K object classes, and the second is the bounding boxes for the objects.
2016 – Faster R-CNN
Faster R-CNN introduced region proposal networks (RPNs) for generating high-quality region proposals. An RPN is a fully convolutional neural network that predicts object bounds and objectness score at each position. Fast R-CNN uses the generated region proposals for detection. Faster R-CNN applies the R-CNN convolutional feature maps to generate region proposals.
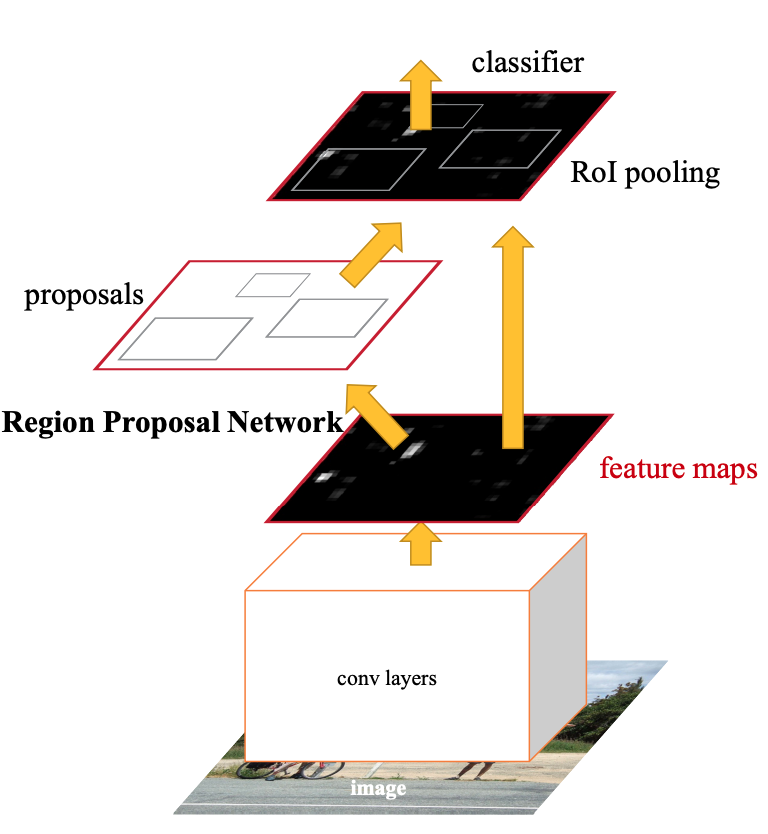
The Faster R-CNN architecture comprises:
- A deep fully convolutional network that proposes regions––a region proposal network (RPN)
- Fast R-CNN detector that uses the proposed regions
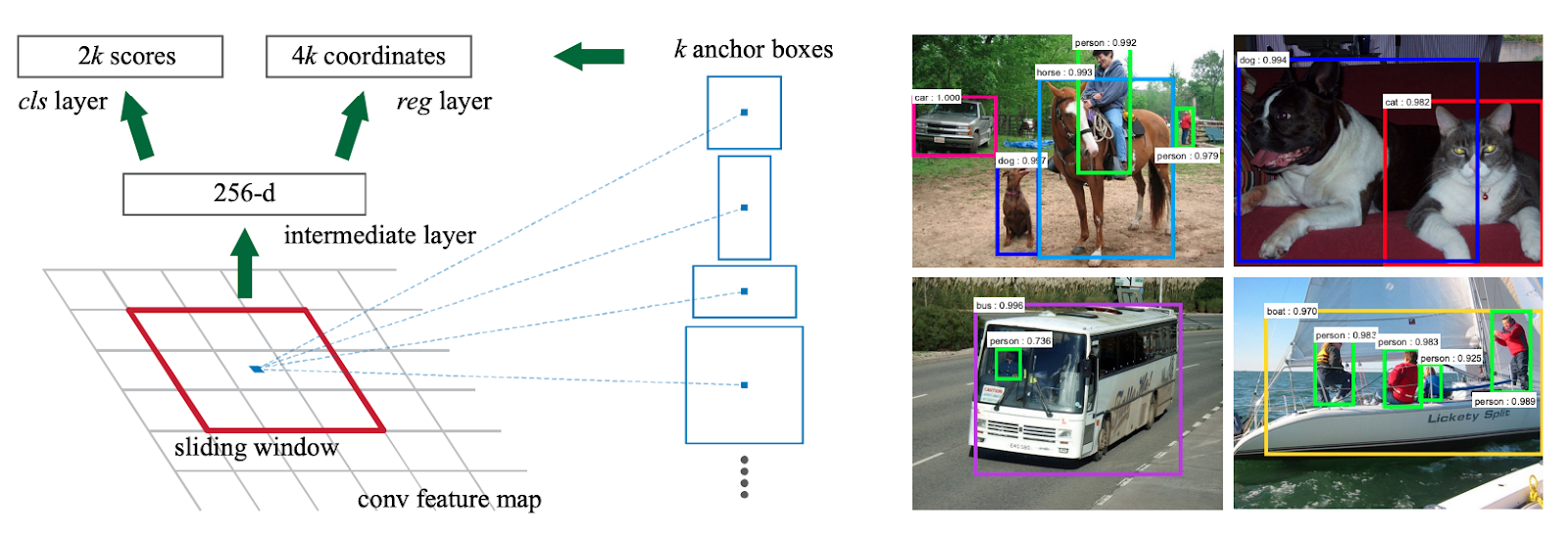
The RPN takes an image of any size and generates rectangular object proposals as well as the likelihood that they belong to a particular class. Region proposals are generated by sliding a network over the convolutional feature map. The sliding window is mapped to a lower-dimensional feature that is fed into a box regression and a box classification layer.
Unlike Fast R-CNN, Faster R-CNN is a two-stage detector.
2016 – You Only Look Once (YOLO)
YOLO is a single-shot object detector model that predicts class probabilities and bounding boxes given an image. With YOLO, you only look once to detect objects and their location; therefore, it doesn’t use sliding windows or region proposals. Since YOLO is a one-stage network, it’s faster than two-stage models, such as R-CNN.

As shown below, YOLO divides the entire image into a grid and predicts bounding boxes, their confidence, and class probabilities for each grid cell. If the confidence score is zero, no image exists in that cell.

YOLO’s architecture consists of:
- 24 convolutional layers followed by 2 fully connected layers
- Alternating 1-by-1 convolutional layers to reduce the feature space from previous layers
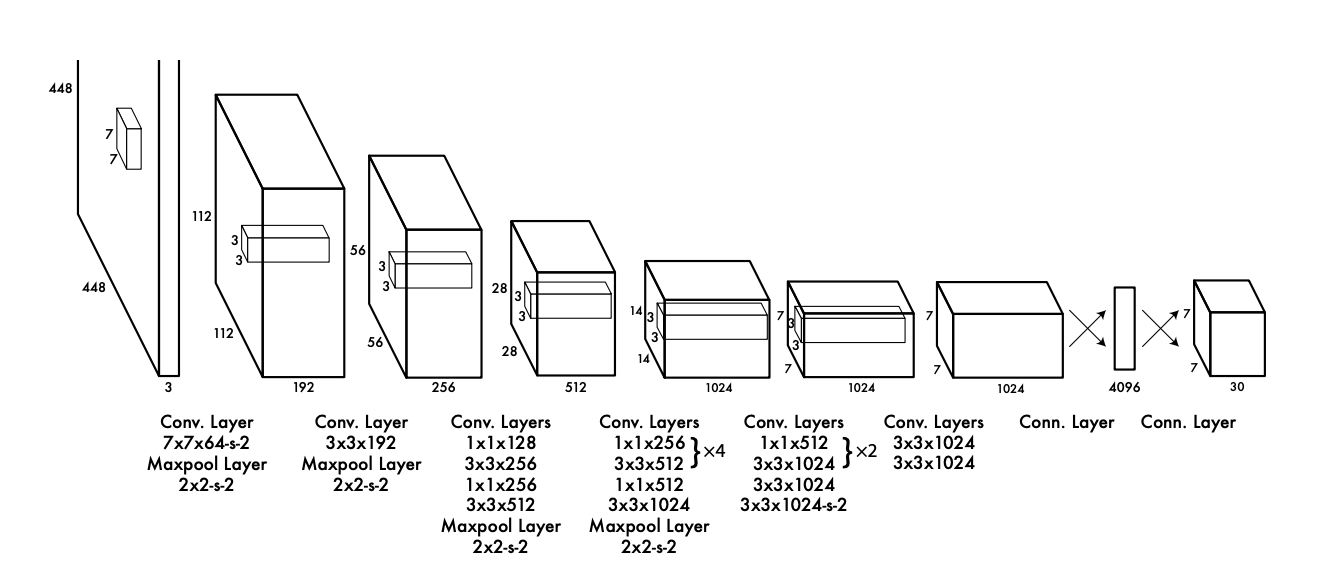
YOLO proposes only 98 boxes per image, compared to 2000 by R-CNN. Unlike R-CNN, which uses selective search, Fast and Faster R-CNN use neural networks to propose regions; but, they are still slower than YOLO.
2016 – Single Shot MultiBox Detector (SSD)
SSD detects objects in images using one deep neural network without generating object proposals. SSD:
- Accepts an image and ground truth bounding boxes.
- Uses convolutions to evaluate a set of boxes at each location.
- Predicts shape offsets and confidence of all object categories for each box.
- Matches the boxes with the ground truth bounding boxes at training.
- Treats matching boxes as positive and the rest as negative.
- Computes model loss as the weighted sum between softmax and localization loss.

The SSD model uses a convolutional neural network to generate a fixed-size set of bounding boxes while scoring for objects in the boxes. Final detections are done by non-maximum suppression. The model uses VGG-16 as the base network. Convolutional feature layers are added at the end of the base network to ensure that detection happens at multiple scales. The convolutional feature layers produce detection predictions using convolutional filters.

Unlike SSD, YOLO doesn’t have the extra feature layers at the end of the base network.

2016 – YOLOv2
YOLOv2 is an improvement of YOLO.
Here’s a comparison between YOLOV1 and YOLOv2:
- Like YOLOv1, YOLOv2 is also a single-shot detector, but YOLOv2 can process images of different resolutions.
- YOLOv2 uses batch normalization layers to make training more stable and act as a regularizer.
- YOLOv2 introduced a higher resolution classifier of 448-by-448 compared to 224-by-224 in YOLOv1.
- YOLOV1 makes predictions using fully connected layers while YOLOv2 removes fully connected layers; hence, YOLOv2 is a fully convolutional neural network.
- YOLOv1 has a downsampling factor of 64 and an output grid of 7-by-7, while YOLOv2 has a downsampling factor of 32 and an output grid of 13-by-13.
- YOLOv2 uses anchor boxes with predefined sizes for bounding box predictions, while YOLOV1 predicts the width and height of bounding boxes directly.
- YOLOv1 predicts conditional class probabilities for each cell, and each grid cell can only detect one object. YOLOv2 predicts conditional class probabilities for each anchor box, and one grid cell can detect multiple objects.
- In YOLOv2, the anchor box with the highest IoU with ground truth is the predicted box.
- YOLOv2 computes the dimension of the anchor boxes using K-means clustering with K as 5.
- Both models predict the confidence score as the IoU between the ground truth and the predicted box.
2017 – Feature Pyramid Network (FPN)
FPN is a general-purpose architecture that combines strong and weak semantic information. It accepts single-scale images and generates feature maps at multiple levels in a fully convolutional manner. For example, it can be part of the Faster R-CNN system.
The intuition behind FPNs is that a pyramid of the same image at different scales can be used in detecting objects. The problem is that training such a network is time and memory intensive. The alternative is to create a pyramid of features and use them for detection. The FPN can be used as a feature extractor for object detection networks such as the Faster R-CNN system.
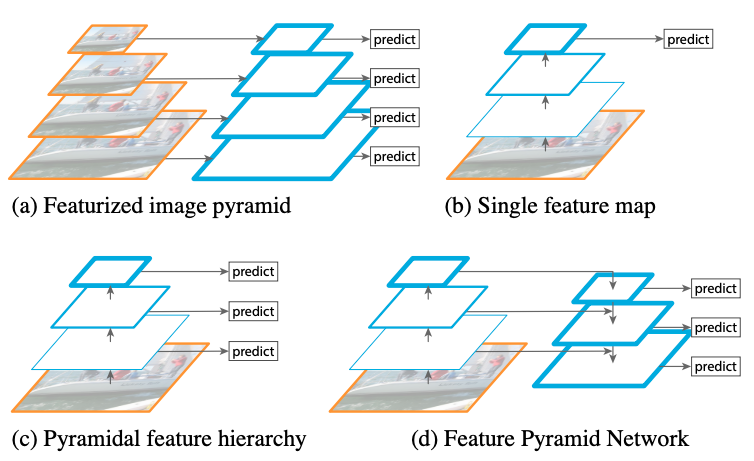
Construction of the pyramid involves a bottom-up pathway, a top-down pathway, and lateral connections. The bottom-up pathway is the convolutional neural network that computes a hierarchy of feature maps at various scales with a scaling step of 2. The top-down pathway creates higher-resolution features by upsampling the feature maps from higher pyramids. Features from higher pyramids are coarser but semantically stronger.
Lateral connections are created using the features obtained above and the ones from the bottom-up pathway. You can think of this as the skip connections in ResNet. That operation is illustrated below.

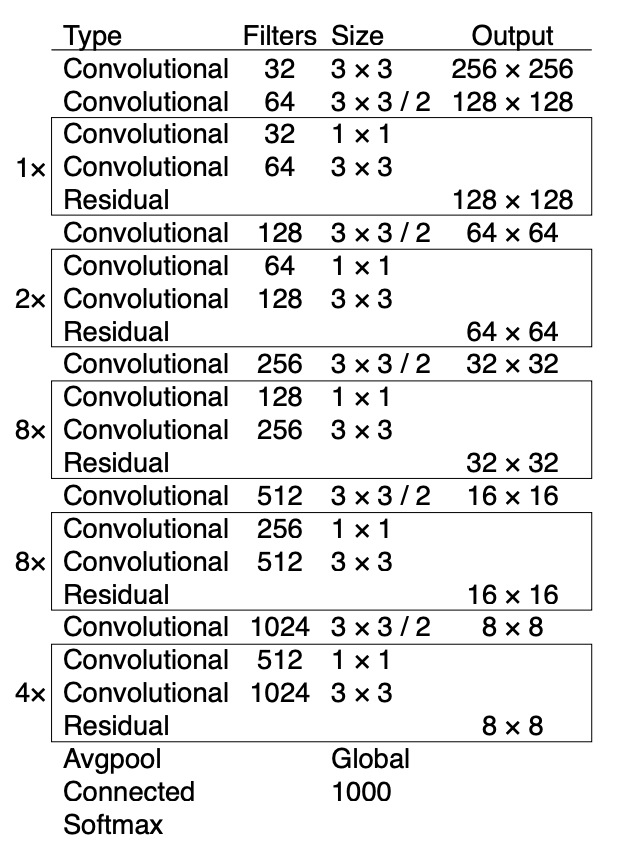
2018 – YOLOv3
YOLOv3 is an improved version of YOLOv2.
Here is a comparison between YOLOv2 and YOLOv3:
- Both use anchor boxes as prior information to predict bounding boxes.
- YOLOv3 uses logistic regression to predict an objectness score for each bounding box.
- Like YOLOv2, YOLOv3 uses K-means clustering to determine bounding box priors.
- YOLOv3 has 53 convolutional layers, hence the name Darknet-53.
- The feature extractor in YOLOv3 is similar to the one in YOLOv2 but with some adjustments, such as using 3-by-3 and 1-by-1 convolution layers with skip connections.
2019 – CenterNet
CenterNet is an anchor-free one-stage keypoint-based detector that identifies objects by detecting their centers. It is based on the CornerNet network.
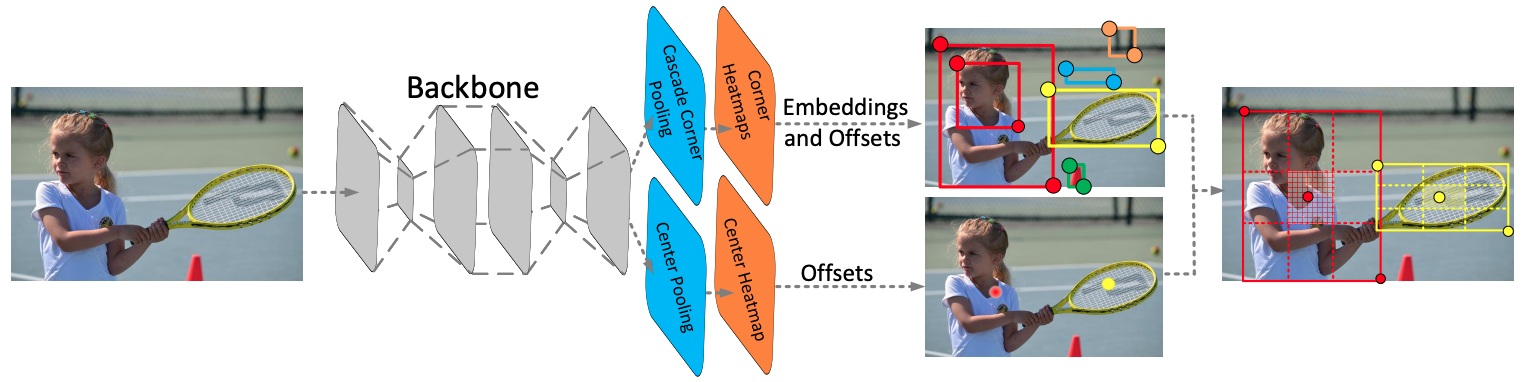
CenterNet has two main modules:
- Cascade corner pooling for predicting corners using maximum values in boundary and internal directions of objects
- Center pooling for predicting center key points using the maximum values in the horizontal and vertical directions
2020 – YOLOv4
YOLOv4 is an improved version of YOLOv3 with new techniques such as “bag of freebies” (BoF) and “bag of specials” (BoS). The architecture of YOLOV3 comprises CSPDarknet53 as the backbone, SPP + PANet as the neck, and YOLOV3 as the head. The SPP block helps increase the receptive field and PANet for parameter aggregation. CSPDarknet53 is responsible for feature extraction. YOLOV3 is used to predict classes and bounding boxes.
BoF are methods that only increase or change the training cost (for example, data augmentation). Mosaic data augmentation is one such proposal that combines four training images.
Self-adversarial training is a BoS data augmentation technique that operates in two forward-backward stages. In the first stage, it changes the original image and not the network weights. In the second stage, the network detects an object in the altered image.
BoSs are methods and plugin modules that improve accuracy while increasing inference costs by a small margin. For example, as mentioned earlier, the SPP module enhances the receptive fields.
2020 – YOLOv5
YOLOv5 by Ultralytics translated the model from Darknet to PyTorch. YOLOv5 uses data augmentation strategies, such as mosaic augmentation, that help in accurately detecting small objects. Porting the model to PyTorch also enabled training and inference in lower precision, speeding up inference and training.
YOLOv5 uses cross stage partial networks (CSPs) bottleneck to generate image features and a PA-Net neck for feature aggregation.
2020 – DEtection TRansformer (DETR)
DETR is an object detection model based on transformers. DETR works without non-maximum suppression and anchor generation.
DETR uses a global loss to make predictions via bipartite matching. It makes predictions by creating features using a CNN and passing them to an encoder-decoder architecture. Final bounding boxes are generated by comparing the predicted boxes with ground truth boxes.
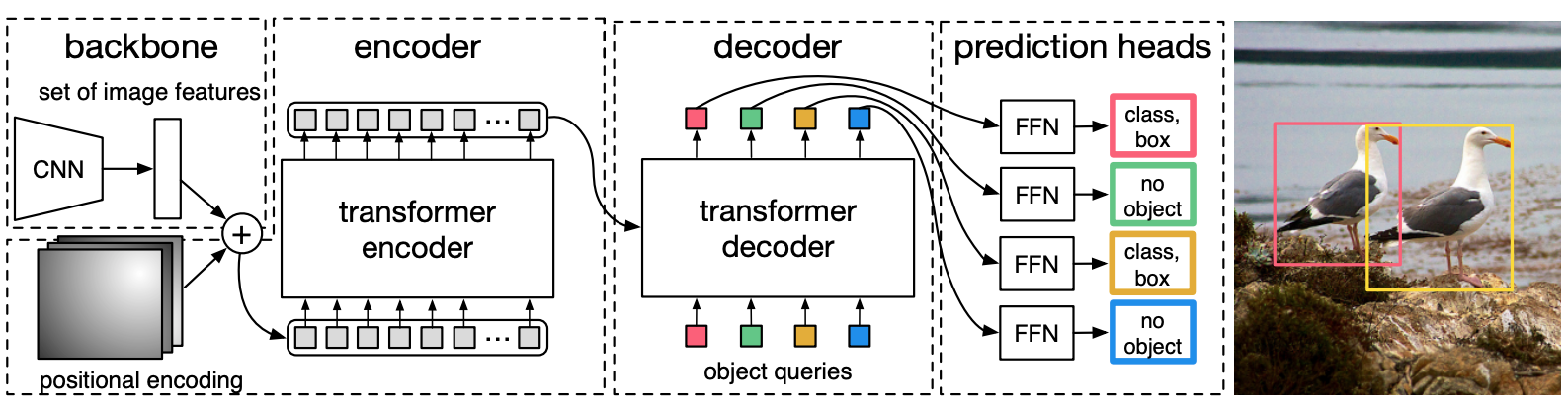
In a nutshell, the architecture of DETR comprises:
- A CNN backbone for feature representation
- Positional encoding of the representation before passing to the transformer
- An encoder-decoder transformer that accepts the learned positional embeddings
- A feed-forward network for making the final detection prediction
2020 – EfficientDet
EfficientDet is an object detection network based on EfficientNet. The EfficientDet architecture consists of:
- EfficientNet as the backbone network
- A weighted bi-directional feature pyramid network (BiFPN) as the feature network

EfficientDet tackles two major problems in object detection:
- Efficient multi-scale feature fusion is solved by the weighted BiFPN. Unlike FPN networks, BiFPN applies a learnable weight matrix to learn the importance of different input features. BiFPN also allows information to flow top-down and button-up.
- Model scaling is solved by introducing a compound scaling method that jointly scales up the resolution, depth, or width of the backbone, feature network, and box and class prediction network.
2021 – YOLOX
YOLOX is an anchor-free version of YOLO. The feature extractor in YOLOX is based on YOLOv3. Unlike YOLOV3, the head in YOLOX is decoupled, which increases the model convergence speed. BCE loss is used to train the class branch, and IoU loss is used for training the regression branch. Mosaic augmentation data augmentation is also applied in YOLOX.
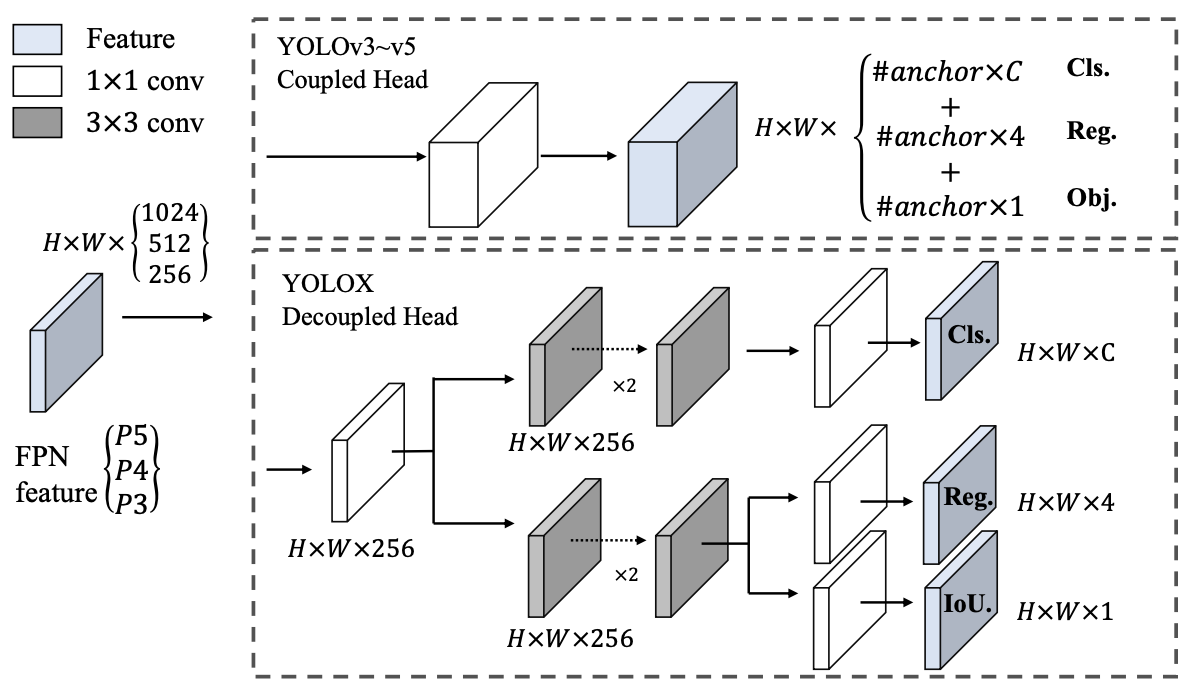
YOLOX introduces an anchor-free mechanism to tackle the known problems of anchor-based methods, which include:
- There is a need to perform cluster analysis to obtain optimal anchors.
- Clustered anchors are less generalizable because they are domain specific.
- Anchor-based methods make detection heads more complex.
YOLOX creates an anchor-free network by:
- Making one instead of three predictions per location
- Predicting four values directly (that is, the two offsets for the left top corner, and the height and width of the predicted box)
2021 – You Only Look at One Sequence (YOLOS)
YOLOS is a vision transformer-based (ViT) object detection series of models. YOLOS is not an extension of the YOLO family of models.
Vision transformers:
- Split the images into fixed-size patches
- Flattened the image patches and linearly embed them
- Add position embeddings to retain positional information
- Pass the embeddings to the standard transformer encoder
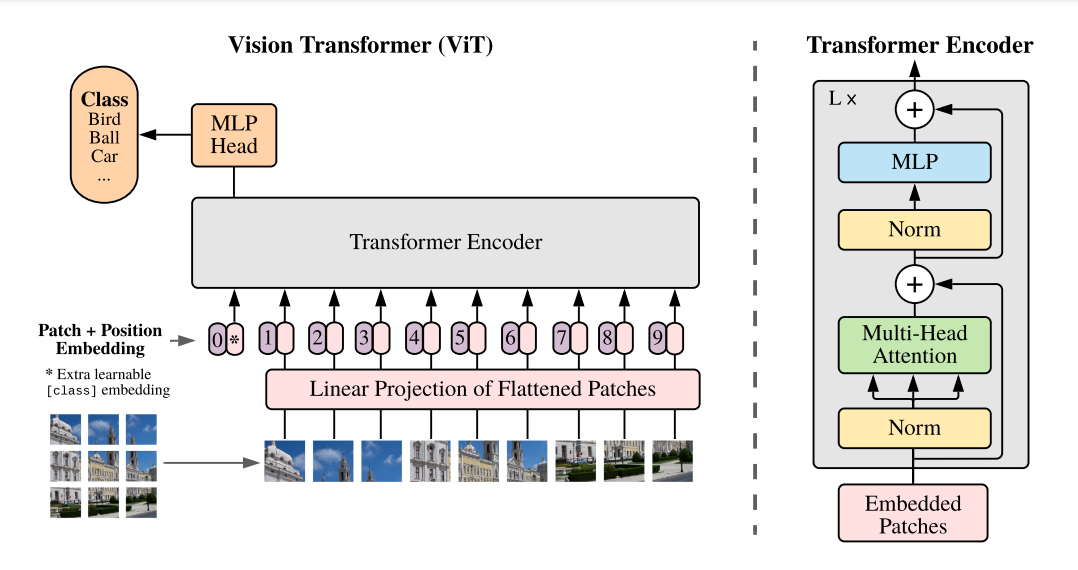
Changing a pre-trained ViT to a YOLOS detector is done by:
- Replacing one [CLS] token for image classification with 100 [DET] tokens for object detection
- Replacing the image classification loss in ViT with the bipartite matching loss for object detection

The design of YOLOS is inspired by DETR. The difference between the two is that DETR uses an encoder-decoder transformer while YOLOS applies an encoder-only transformer. While DETR uses a CNN for the backbone, YOLOS uses the ViT.
In the above architecture:
- Pat-Tok ([PATCH]) token refers to the embedding of the flattened image patch.
- PE is the positional embedding.
- Det-Tok ([DET] token) is a learnable embedding for object binding.
At inference, YOLOS generates the final prediction in parallel.
2022 – YOLOv6
YOLOv6 is an anchor-free object detection model with a decoupled head like YOLOX.
The architecture of YOLOv6 is made up of:
- EfficientRep, built for the efficient utilization of computing hardware, as the backbone. For small models, RepVGG, a modified VGG with skip connections, is used as the backbone.
- Reparameterized Path Aggregation Network (Rep-PAN) for the neck. It is also built for better hardware utilization while balancing the trade-off between accuracy and speed.

YOLOv6 uses the following losses:
YOLOv6 also utilizes quantization and knowledge distillation. Self-distillation is done on the classification and regression tasks.
2022 – YOLOv7
YOLOv7 is a real-time object detection model that optimizes the training process through a trainable bag of freebies (optimized modules and optimization methods that improve object detection accuracy without increasing the cost of inference). Like YOLOv6, YOLOv7 applies re-parameterization techniques. It also introduces a new model scaling method.
YOLOv7 uses extended efficient layer aggregation networks (E-ELAN) for model re-parameterization, which involves combining multiple models at inference to improve inference time.
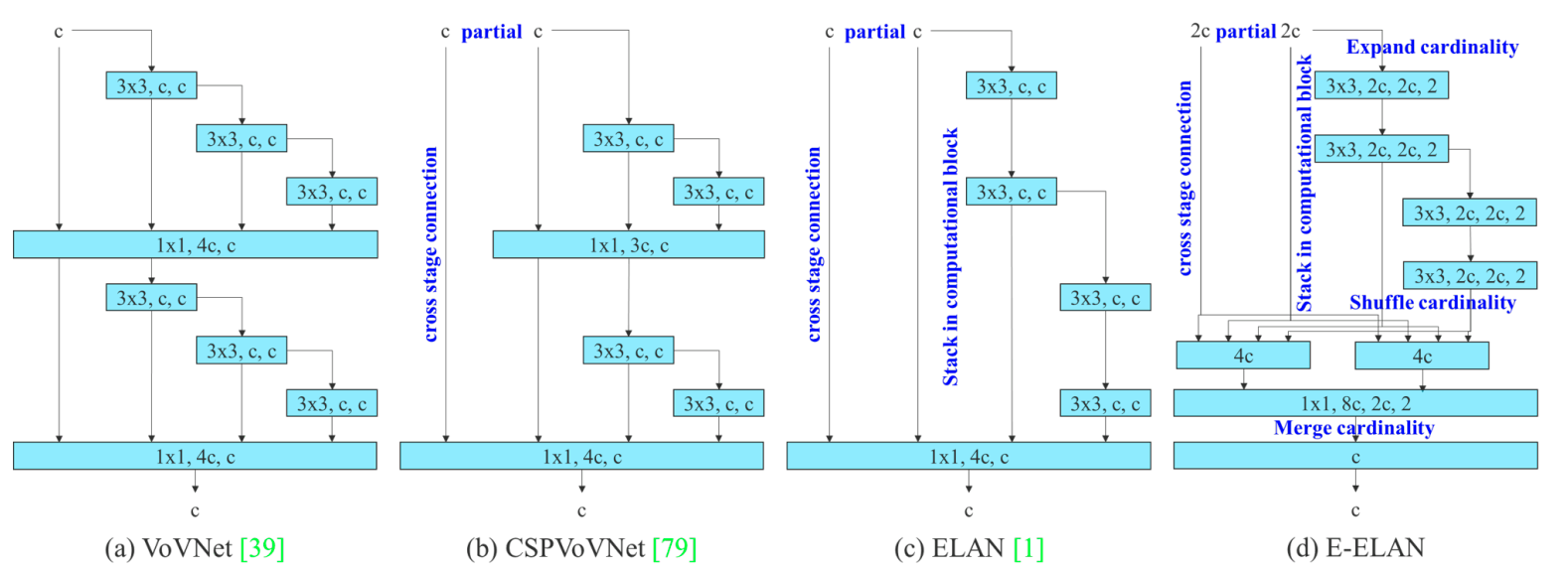
YOLOv7 scales the network depth and width while concatenating layers.

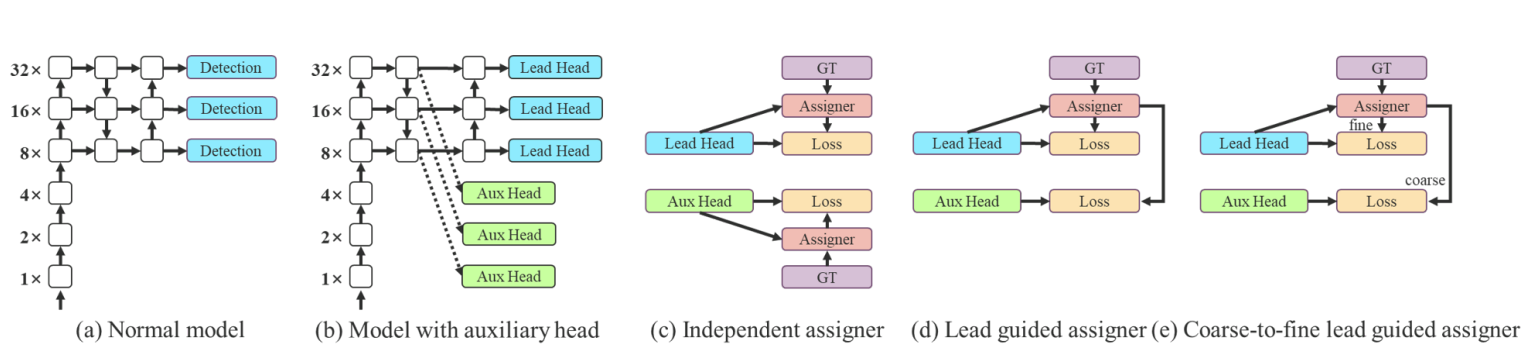
YOLOv7 has two heads:
- An auxiliary head that helps in model training
- A lead head for making predictions
The lead head is used as a guide to predict coarse-to-fine hierarchical labels. These labels are used for learning by the lead and auxiliary head.
2023 – YOLOv8
YOLOv8 is the latest object detection, segmentation, and classification architecture to hit the computer vision scene. Developed by Ultralytics, the authors behind the popular YOLOv3 and YOLOv5 models, YOLOv8 takes object detection to the next level with its anchor-free design. But it's not just about cutting-edge accuracy. YOLOv8 is designed for real-world deployment with a focus on speed, latency, and affordability.
Current Challenges in Implementing Object Detection Models
Despite these recent advances in object detection, deploying objection models is still a challenge. These challenges result from:
- The size of object detection models
- Requirement for expensive GPU resources
- Difficulty of deploying the object detection models
Model Size
Large computer vision models offer high detection accuracy. However, model size and computation costs prevent their use in real world hardware, where model latency and size are constrained. Therefore, reducing model size is crucial to making object detection models widely available.
Expense of GPU Compute
Object detection models should be able to run in real-time, especially for applications such as autonomous vehicles or security systems. To achieve this, it is necessary to make the models smaller, which allows them to be run on commodity CPUs with performance similar to that of GPUs. This not only avoids the cost of using expensive GPU hardware, but also makes it practical to use computer vision models in the real world because CPUs, which are both inexpensive and widely available, can be used for deployment.
Deployment Difficulty
The size of object detection models makes it difficult to deploy them, especially on edge devices such as mobile phones. Reducing the size of the computer vision models can be done by removing some connections from the over-parameterized and over-precise model. This can be achieved through quantization and sparsification.
Object Detection Deployment Options
You have already learned that reducing the size of object detection models makes it easier to deploy them. But, how do you make them smaller? Enter SparseML, an open-source framework for sparsifying neural networks in a few lines of code. Even more interesting is that you can use models that have already been sparsified. These models are available on SparseZoo. For example, let’s use a pruned and quantized YOLOv5 model for object detection.
First, let’s install DeepSparse, which is a sparsity-aware inference runtime that offers GPU-class performance on CPUs and APIs to integrate ML into your application.
pip install deepsparseCalling the object_detection.annotate command performs object detection and stores the resulting image in a folder.
deepsparse.object_detection.annotate --source basilica.jpg --model_filepath zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65_quant-none
Final Thoughts
Object detection is a crucial task in computer vision with numerous real-world applications. By understanding the various techniques and algorithms available, you can make informed decisions on which approach to use for a given problem. While deep learning has proven to be a powerful tool for object detection, it is also important to consider factors such as model size and deployment when choosing a model. Sparsification and quantization can help reduce a model's size without sacrificing accuracy, with tools like SparseZoo making it simple to find and use sparsified models.
To start deploying sparse object detection models, head over to SparseZoo and choose a state-of-the-art model.







