

Jun 18, 2024

Author(s)

The Power of LLMs
Large Language Models (LLMs) have transformed AI, enabling machines to understand and generate human-like text. These models, trained on vast datasets, excel at tasks like answering questions, summarizing content, and providing customer support. Their versatility makes them valuable across healthcare, finance, education, entertainment, and nearly all other industries
However, achieving high accuracy with LLMs often comes with significant computational costs. Larger models require more resources to run, which leads to higher deployment expenses. Balancing performance and cost efficiency is crucial for organizations to leverage these powerful tools effectively.
Llama 3 addresses these challenges by offering improved accuracy and cost-effectiveness, making advanced AI accessible to more users. The following sections explore how Llama 3 builds on its predecessors to deliver these benefits and how you can utilize its superior performance for more accurate and cheaper deployments.
Breaking New Ground with Llama 3
Llama and the subsequent Llama 2 models were significant advancements in the realm of language models, particularly for open-source communities. However, they faced accuracy limitations compared to closed-source solutions, especially at smaller model sizes. These constraints hindered their usability for organizations with limited computational resources.
Llama 3 was developed to address these issues, incorporating several improvements over its predecessors. The core enhancement is a sevenfold increase in training data, covering over 15 trillion tokens from diverse text sources and languages. To put this into perspective, this is roughly equivalent to reading Wikipedia 3,000 times or reading "Pride and Prejudice" more than 100 million times. This extensive dataset, advanced data filtering techniques, and new scaling laws enhance performance prediction and resource allocation.
Additionally, Llama 3 improves chat interactions using OpenAI’s Tiktoken tokenizer, doubles the maximum context length, and employs optimization techniques like data parallelization and an advanced training stack that automates error detection, handling, and maintenance. These enhancements significantly boost training efficiency and reliability, making Llama 3 a robust choice for various applications.
Comparative results consistently show Llama 3 outperforming Llama 2 and other leading models on standard research benchmarks. The graph below highlights the accuracy for standard research benchmarks vs. model size, demonstrating Llama 3's superior efficiency.
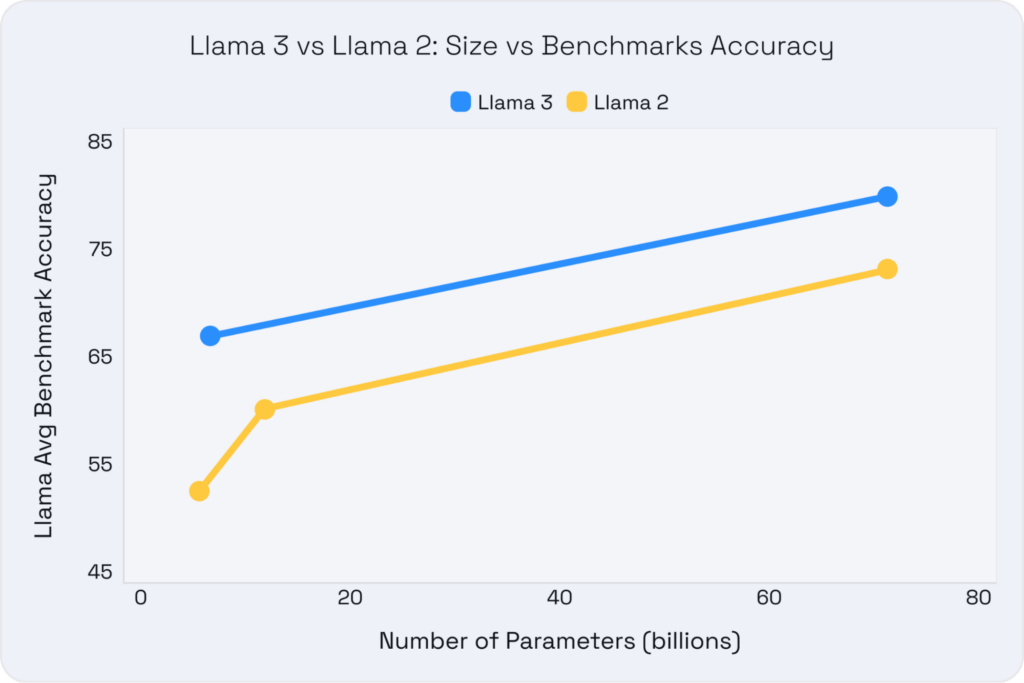
Llama 3 8B: Performance and Cost Efficiency Redefined
The 8 billion parameter version of Llama 3 (Llama 3 8B) perfectly balances performance and cost efficiency, making it an ideal choice for various real-world applications, as highlighted below.
Superior Accuracy
Llama 3 8B delivers impressive accuracy compared to previous generations of language models, including much larger ones. To ensure the model's performance scales beyond the research benchmarks listed above to real-world applications, we evaluated it alongside the 7B and 70B variants of Llama 2 using evaluation harnesses that closely correlate with everyday performance and usage. The quick summary: the 8B model is 28% better on average than Llama 2 70B and over a 200% improvement on top of Llama 2 7B!
Our evaluations focused on popular use cases, including chat for customer support, code generation to enhance software engineering, summarization for condensing product reviews and emails, and retrieval-augmented generation (RAG) for question answering and natural language search. Here are the evaluations used and the rationale behind them:
- Chat - AlpacaEval 2.0 Win Rate: Measures conversational AI performance to reflect real-world customer support interactions. The rationale is to ensure the model provides accurate and contextually relevant responses in chat scenarios.
- Code Generation* - HumanEval Pass@1: This evaluation assesses the model's ability to generate correct code on the first attempt. It is crucial for augmenting and speeding up software development workflows.
- Summarization - CNN/DailyMail Rouge-L-Sum: This metric assesses the model's ability to generate concise and accurate summaries, which is vital for efficiently processing product reviews and emails.
- RAG - MS Marco Rouge-L-Sum: This metric tests the model's performance in retrieval-augmented generation tasks to ensure it can accurately answer questions and summarize natural language searches.
The graph below illustrates the differences in accuracy and provides exact numbers for these evaluations.
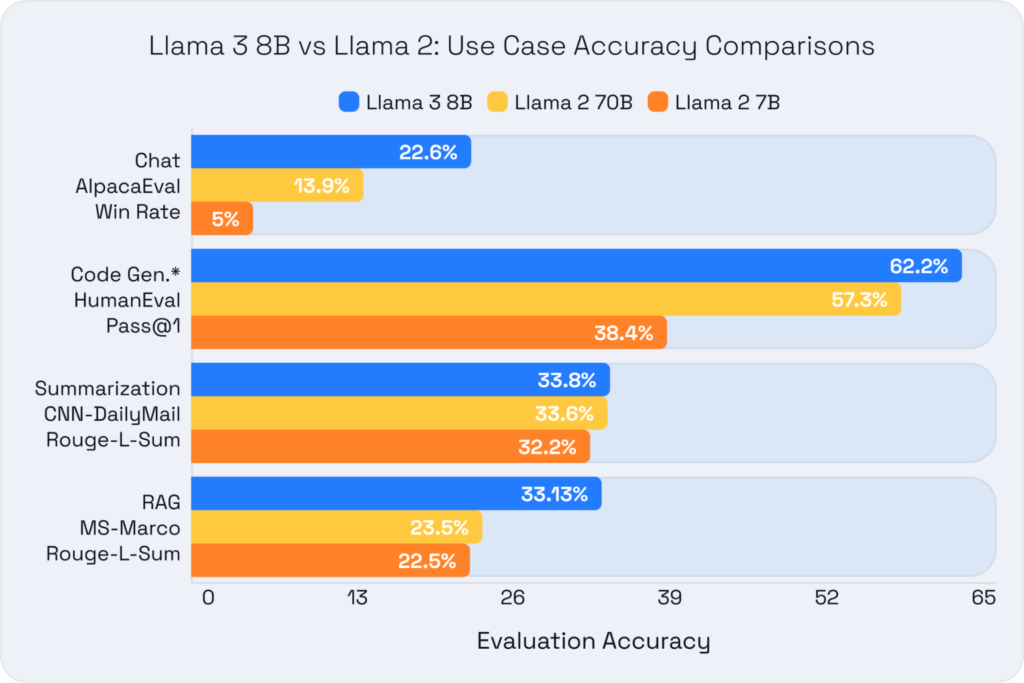
* CodeLlama models were used instead of Llama 2 due to the Llama 2 models' poor baseline performance on code generation tasks.
Performance and Cost Efficiency
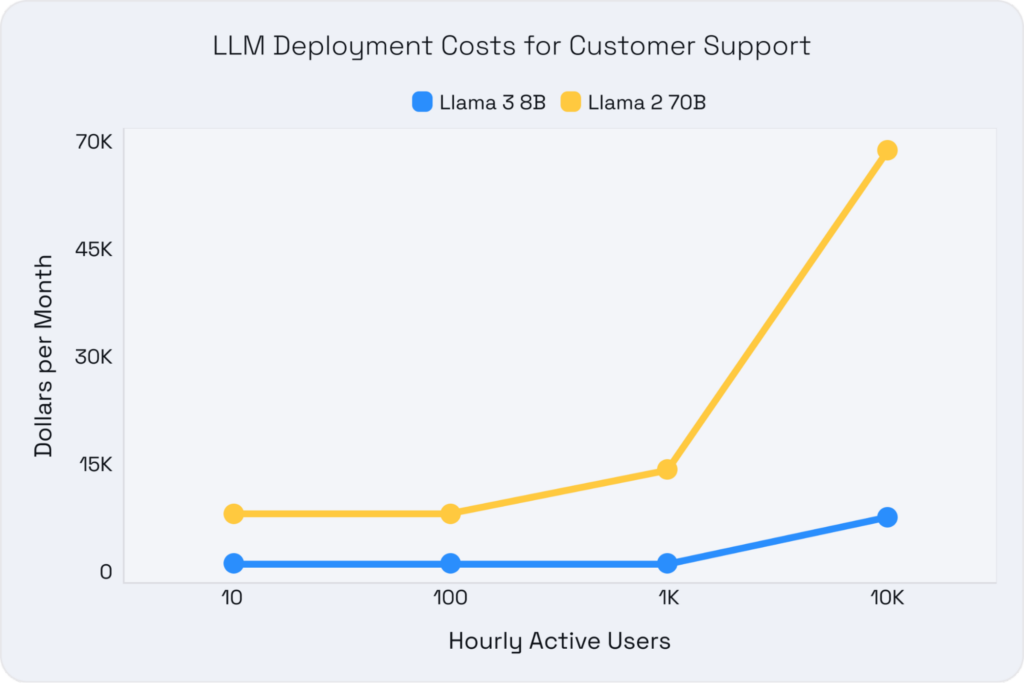
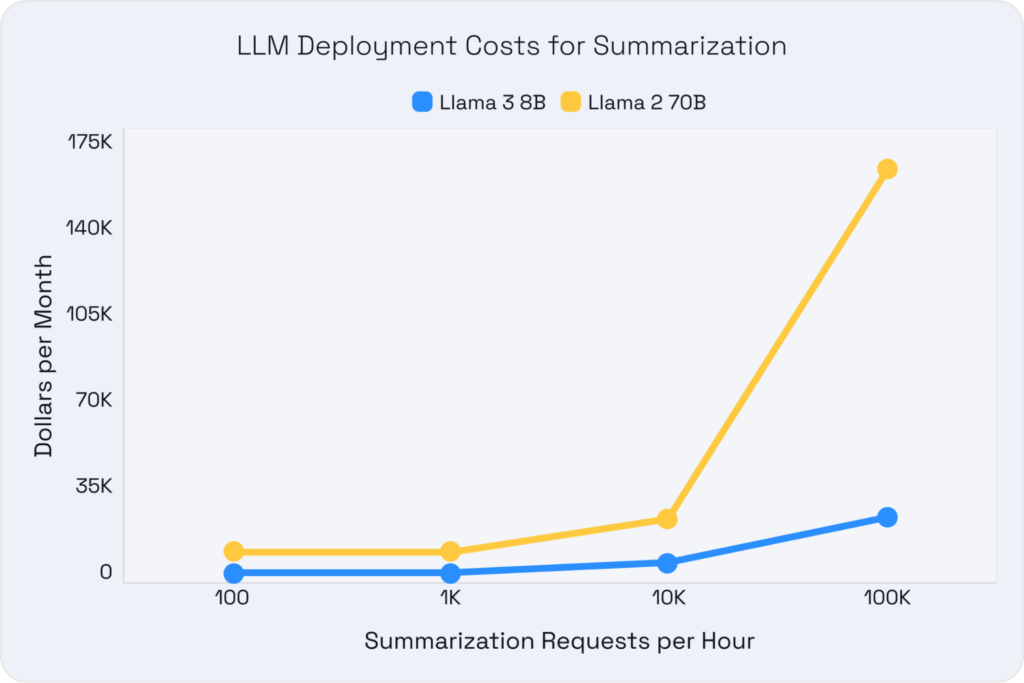
Llama 3 8B stands out for its superior accuracy and impressive cost efficiency. The advantages are clear when comparing the total cost of ownership (TCO) between it and previous generations at a given accuracy budget, such as Llama 2 70B. Llama 3 8B can run on a single, more affordable GPU like the A10, while the baseline 70B parameter models require two A100 GPUs due to their size. All of this while still meeting the same performance requirements. This reduction in hardware requirements leads to significant cost savings of up to 16x, making advanced AI more accessible.
We analyzed a subset of the specific use cases to determine acceptable performance criteria across customer support to represent a latency-sensitive use case and summarization to represent a throughput use case. By benchmarking across various GPU setups and utilizing a representative dataset, we accounted for differences in prompts and generated token lengths across tasks. This approach helped us identify the most cost-effective setups that met our service level objectives (SLOs). Here are the SLOs (targeting mean performance) and rough dataset distributions we used:
- Customer Support (Chat): This requires a fast time to the first token (<1 second) and a minimum of 10 tokens per second thereafter for responsive performance. Typical setups involve medium prefill lengths (~768 tokens) and medium generation lengths (~256 tokens).
- Summarization: This focuses on maximizing total throughput for bulk processing. It involves long prefill lengths (~1024 tokens) and short generation lengths (~128 tokens).
The graphs below highlight the TCO comparisons across these use cases for various deployment scales, illustrating how Llama 3 8B offers significant cost savings and performance improvements.
Seamless Deployments using vLLM
Deploying Llama 3 8B with vLLM is straightforward and cost-effective. We've explored how Llama 3 8B is a standout choice for various applications due to its exceptional accuracy and cost efficiency. Now, let’s look at how you can realize these gains with your own deployment. By following a few simple steps, you can integrate Llama 3 8B into your systems and start leveraging its powerful capabilities immediately.
Get Started with Llama 3 8B and vLLM:
- Install vLLM: Set up the vLLM environment on your server. Detailed instructions are available in the vLLM documentation.
- Load the Model: Load the Llama 3 8B model into vLLM:
from vllm import LLM
model = LLM("meta-llama/Meta-Llama-3-8B-Instruct")
- Run Inference: Use the model for inference:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")
messages = [{"role": "user", "content": "What is the capital of France?"}]
formatted_prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
output = model.generate(formatted_prompt)
print(output)
This simple process demonstrates the ease and efficiency of deploying Llama 3 8B with vLLM, enabling rapid integration into your applications.
Conclusion
Llama 3 8B sets a new standard for balancing large language models' performance and cost efficiency. With impressive accuracy improvements over previous generations, including the much larger Llama 2 70B and significant cost reductions, Llama 3 8B makes advanced AI more accessible to a broader range of applications and organizations. Its ability to run on more affordable hardware, such as a single A10 GPU, while still delivering high performance highlights its potential to revolutionize various industries.
We encourage you to try Llama 3 8B on vLLM and experience its benefits firsthand. The comprehensive vLLM documentation provides detailed setup instructions. If your organization needs enterprise support with vLLM, Neural Magic offers enterprise-grade software alongside a world-class team of ML researchers, ML engineers, and HPC engineers to act as an extension of your team for AI production deployments. Let us know how we can help!
Explore our other blogs to learn more, and stay tuned for additional blogs on topics like how to easily deploy Llama 3 70B, quantizing models for decreased costs while maintaining accuracy, and how to further reduce infrastructure spend with sparsity.






