

Jan 18, 2023

Author(s)



Introducing YOLOv8—the latest object detection, segmentation, and classification architecture to hit the computer vision scene! Developed by Ultralytics, the authors behind the wildly popular YOLOv3 and YOLOv5 models, YOLOv8 takes object detection to the next level with its anchor-free design. But it's not just about cutting-edge accuracy. YOLOv8 is designed for real-world deployment, with a focus on speed, latency, and affordability.
In this article, you will learn about the latest installment of YOLO and how to deploy it with DeepSparse for the best performance on CPUs. We illustrate this by deploying the model on AWS, achieving 209 FPS on YOLOv8s (small version) and 525 FPS on YOLOv8n (nano version)—a 10x speedup over PyTorch and ONNX Runtime!
In the coming weeks, Neural Magic will continue to optimize YOLOv8 for inference via pruning and quantization and will offer a native integration within the DeepSparse package. Join the Neural Magic community for updates.
For a detailed guide on how DeepSparse achieves speed-up with sparsity, check out YOLOv5 with Neural Magic's DeepSparse.
What’s New in YOLOv8?
Apart from improvements to the architecture driving better accuracy for a given level of performance, YOLOv8 ships with a Python package called ultralytics for simple fine-tuning, validation, annotation, and exporting. Let’s dive in and take a look!
The improvements to model architecture made by Ultralytics have pushed YOLOv8 to the top of the performance-accuracy curves, leapfrogging YOLOv7. With these updates, YOLOv8 offers both the friendliest library for training models and the best accuracy at a given performance threshold!
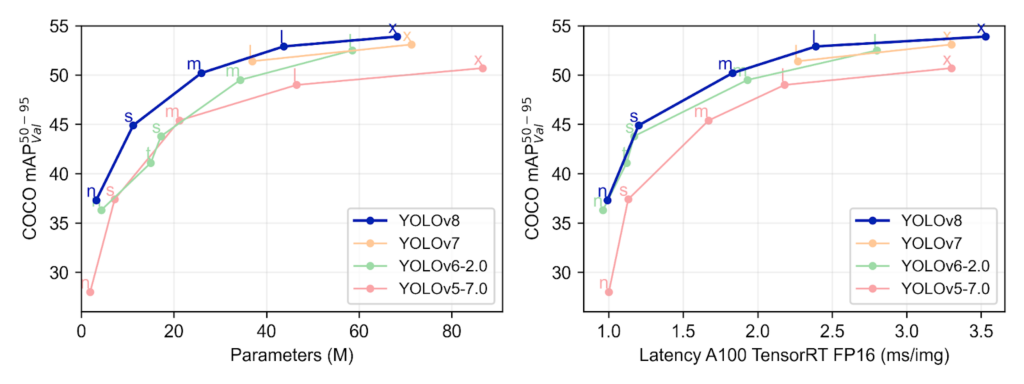
The new ultralytics repository also improves on the usability of YOLOv5, with simplified installation via PyPI and cleaner CLI-based and Python-based APIs for training and predicting across object detection, segmentation, and classification tasks.
YOLOv8 Usage
The new ultralytics package makes it easy to train a YOLO model with custom data and convert it to the ONNX format for deployment.
Here’s an example of the Python API:
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.yaml") # build a new model from scratch
model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Use the model
results = model.train(data="coco128.yaml", epochs=3) # train the model
results = model.val() # evaluate model performance on the validation set
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
success = YOLO("yolov8n.pt").export(format="onnx") # export a model to ONNX formatHere’s an example via the CLI:
yolo task=detect mode=predict model=yolov8n.pt
source="https://ultralytics.com/images/bus.jpg"Deploy YOLOv8 with DeepSparse
For production deployments in real-world applications, inference speed is crucial in determining the overall cost and responsiveness of the system. DeepSparse is an inference runtime focused on making deep learning models like YOLOv8 run fast on CPUs. While DeepSparse achieves its best performance with inference-optimized sparse models, it can also run standard, off-the-shelf models efficiently.
Let’s export the standard YOLOv8 model to ONNX and run some benchmarks on an AWS c6i.16xlarge instance.
# Install packages for DeepSparse and YOLOv8
pip install deepsparse[yolov8] ultralytics
# Export YOLOv8n and YOLOv8s ONNX models
yolo task=detect mode=export model=yolov8n.pt format=onnx opset=13
yolo task=detect mode=export model=yolov8s.pt format=onnx opset=13
# Benchmark with DeepSparse!
deepsparse.benchmark yolov8n.onnx --scenario=sync --input_shapes="[1,3,640,640]"
> Throughput (items/sec): 198.3282
> Latency Mean (ms/batch): 5.0366
deepsparse.benchmark yolov8s.onnx --scenario=sync --input_shapes="[1,3,640,640]"
> Throughput (items/sec): 68.3909
> Latency Mean (ms/batch): 14.6101DeepSparse also offers some convenient utilities for integrating a model into your application. For instance, you can annotate images or video using YOLOv8. The annotated file is saved in an annotation-results folder:
deepsparse.yolov8.annotate --source basilica.jpg --model_filepath "yolov8n.onnx # or "yolov8n_quant.onnx"
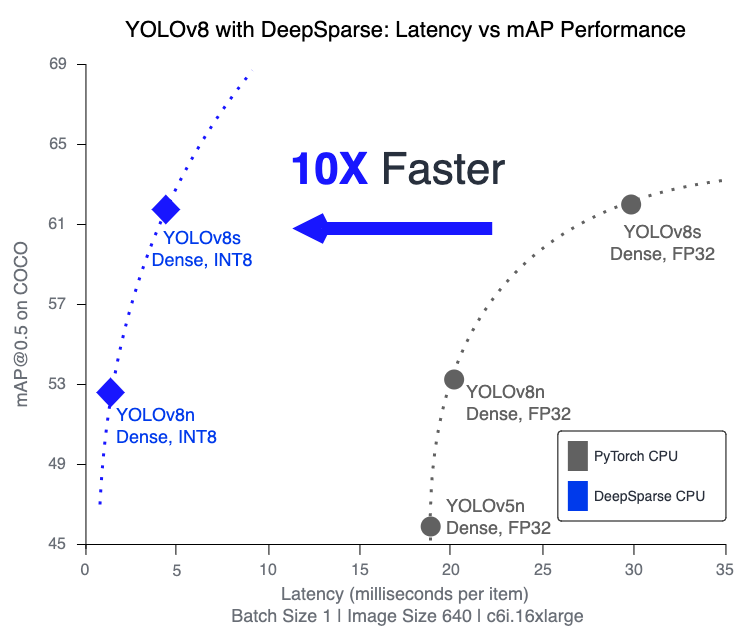
DeepSparse’s performance can be pushed even further by optimizing the model for inference. DeepSparse is built to take advantage of models that have been optimized with weight pruning and quantization—techniques that dramatically shrink the required compute without dropping accuracy. Through our One-Shot optimization methods, which will be made available in an upcoming product called Sparsify, we have produced YOLOv8s and YOLOv8n ONNX models that have been quantized to INT8 while maintaining at least 99% of the original FP32 [email protected]. This was achieved with just 1024 samples and no back-propagation. You can download the quantized models here.
Run the following to benchmark performance:
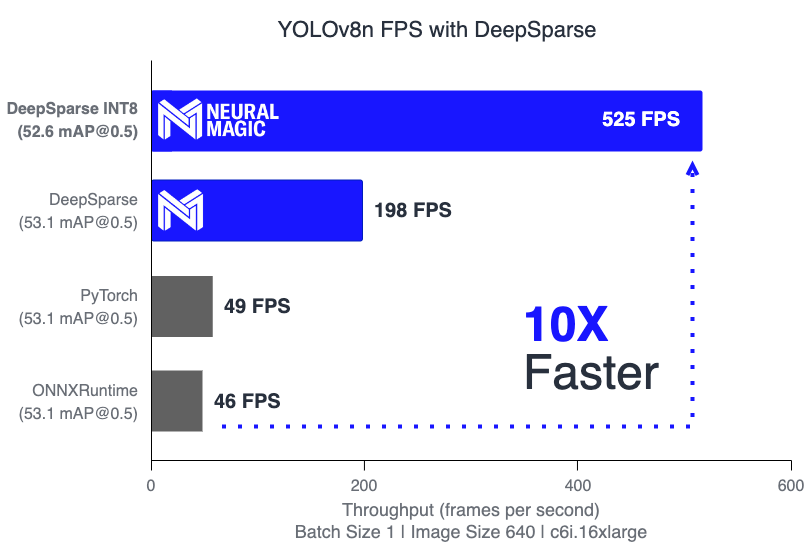
deepsparse.benchmark yolov8n_quant.onnx --scenario=sync --input_shapes="[1,3,640,640]"
> Throughput (items/sec): 525.0226
> Latency Mean (ms/batch): 1.9047
deepsparse.benchmark yolov8s_quant.onnx --scenario=sync --input_shapes="[1,3,640,640]"
> Throughput (items/sec): 209.9472
> Latency Mean (ms/batch): 4.7631DeepSparse places commodity CPUs right next to the A100 GPU, which achieves ~1ms latency. Check out our performance benchmarks for YOLOv8 on Amazon EC2 C6i Instances. DeepSparse is 4X faster at FP32 and 10X faster at INT8 than all other CPU alternatives.
| Model | Size (pixels) | mAPval 50-95 | mAPval 50 | Precision | Engine | Speed CPU b1(ms) | FPS CPU |
| YOLOv8n | 640 | 37.2 | 53.1 | FP32 | PyTorch | 20.5 | 48.78 |
| YOLOv8n | 640 | 37.2 | 53.1 | FP32 | ONNXRuntime | 21.74 | 46.00 |
| YOLOv8n | 640 | 37.2 | 53.1 | FP32 | DeepSparse | 5.74 | 198.33 |
| YOLOv8n INT8 | 640 | 36.7 | 52.6 | INT8 | DeepSparse | 1.90 | 525.02 |
| YOLOv8s | 640 | 44.6 | 62.0 | FP32 | PyTorch | 31.30 | 31.95 |
| YOLOv8s | 640 | 44.6 | 62.0 | FP32 | ONNXRuntime | 32.43 | 30.83 |
| YOLOv8s | 640 | 44.6 | 62.0 | FP32 | DeepSparse | 14.66 | 68.23 |
| YOLOv8s INT8 | 640 | 44.2 | 61.6 | INT8 | DeepSparse | 4.76 | 209.95 |
Final Thoughts
The cost and speed of inference are critical factors to consider when deploying YOLOv8 models for real-world application. DeepSparse is a deployment solution that will save you money while delivering GPU-class performance on commodity CPUs. This performance will be pushed further, as Neural Magic sparsifies YOLOv8 models to make them smaller and faster.
Stay tuned for our sparsified versions of YOLOv8 coming soon by joining the community Slack for updates! In the meantime, check out the most optimized YOLO models on SparseZoo.







