
Dec 28, 2022

Author(s)


Accurately detecting and segmenting objects during sorting and packaging helps improve the process quality and significantly lower inspection costs of outbound packages. Fruit detection is an example of such a task. The objective is to identify the presence of fruit, classify it, and accurately locate it.
Detailed information about the object's location can be obtained using instance segmentation. This can enable the building of autonomous pick-and-place systems in which robots are deployed to manipulate––sort, or pack––the object of interest. The detailed information about the object's geometry, captured by instance segmentation, enables a machine to figure out how to grasp a fruit with its robotic fingers and then successfully place it in a bin.
This post shows how to effectively deploy an instance segmentation model using a standard quad-core laptop CPU. We chose the fruit segmentation task to showcase our solution's effectiveness and speed, and potentially convince sorting facility owners that automation through artificial intelligence (AI) brings massive value.
Deploying an Instance Segmentation Model Using a 4-core Laptop
Automating a facility using machine learning may be messy and challenging. Deploying a network that delivers high-quality detection is not enough. Many engineers would be surprised by the possible constraints in a facility, such as:
- The need for high latency
- Limited available computing resources
- Limited connectivity
What do most decision-makers do when they want to deploy AI solutions? They procure a lot of computing resources, so they either invest in a colossal GPU cluster or rent one from a cloud provider. This approach is only feasible for some businesses.
For a sorting task, we require a reliable system that can rapidly and continuously run inference: 24 hours a day, 7 days a week. This means there is a significant risk that using a cloud provider may not fulfill these requirements—especially given that we might often encounter areas of limited connectivity in our sorting facility.
So let us buy a GPU cluster! Well, procuring and maintaining the cluster is a significant financial investment. Why go down that path when practically every sorting facility is already equipped with dozens of computers using good old commodity CPUs? The CPUs are already set up (no need for financial commitment), wired to the facility system (widely available), and already interfacing with all the machinery (the required latency is most likely secured).
Neural Magic delivers the right solution for situations where high throughput and latency are required on commodity CPUs. We provide a neural network inference engine that delivers GPU-class performance on commodity CPUs! DeepSparse takes advantage of sparsified neural networks to deliver state-of-the-art inference speed. The engine is particularly effective when running a network sparsified using methods such as pruning and quantization. These techniques result in significantly more performant and smaller models with limited to no effect on the baseline metrics.
What is YOLACT?
The model we will use in this post is YOLACT (Boyla et al., 2019). YOLACT stands for "You Only Look At Coefficients." YOLACT was one of the first methods to do instance segmentation in real-time. YOLACT is an extension of the popular YOLO (“You Only Look Once”) algorithm. Check out the YOLOV5 on CPUs tutorial to learn more.
YOLO is one of the first deep learning algorithms for real-time object detection. It achieves its speed by forgoing the conventional and slow two-stage detection process, generating regions of proposals, and then classifying those regions. Many conventional detection networks, such as Mask R-CNN, use the two-stage process. On the other hand, YOLO directly predicts a fixed number of bounding boxes on the image. This is done in a single step and is, therefore, fast!
YOLACT is an improvement of YOLO for instance segmentation. Like its predecessor, YOLACT also forgoes explicitly localizing regions of proposals. Instead, it breaks up instance segmentation into two parallel tasks:
- Generating a dictionary of prototype masks over the entire image and
- Predicting a set of linear combination coefficients per detection.
This not only produces a full-image instance segmentation mask from these two components, but it also works very fast!
In the context of this post, speed is the most critical feature of YOLACT. Since our fruit sorting task needs to work in real time, YOLACT is a good choice.
Running Instance Segmentation Using DeepSparse
The model we are deploying comes from the Sparsezoo––the Neural Magic repository for sparsified and pre-trained neural networks. The particular model used in this post is a Pruned82 Quant model. This means 82 percent of the model's weights are removed, and the rest of the parameters are quantized.
You can use the DeepSparse annotate command to have the engine save an annotated photo on disk.
deepsparse.instance_segmentation.annotate --source fruits.jpg

Benchmarking the Sparse Instance Segmentation Model
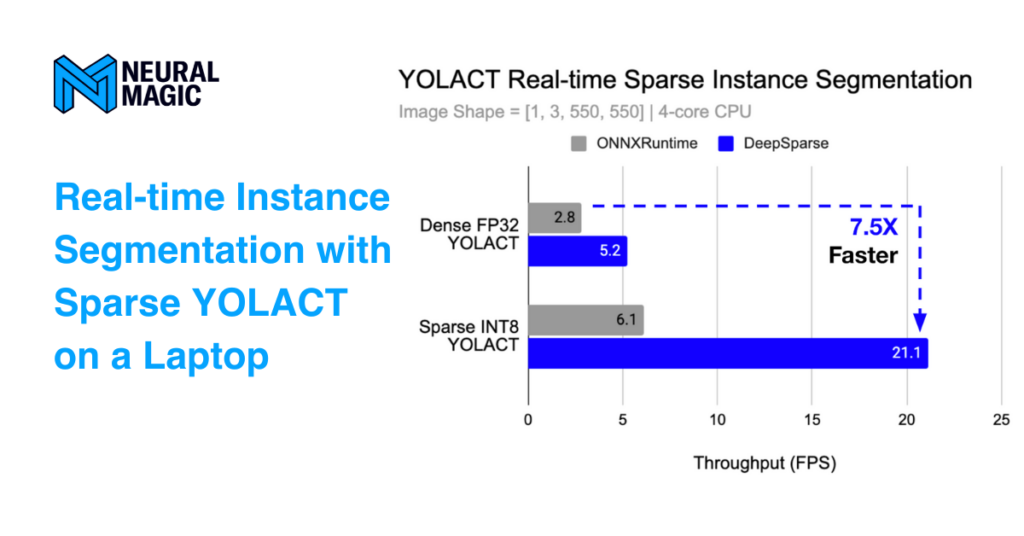
Let’s benchmark the sparsified instance segmentation model against its dense counterpart. Both models are pre-trained on the COCO dataset. While the original, dense model is deployed in the ONNX Runtime engine, the sparse model runs in DeepSparse to take advantage of the model's sparsity.

The table below shows a short comparison of two models used for this post. This benchmark is done on a Lenovo Yoga 9 14ITL5 4-core CPU laptop.
| Model Type | Pruned [%] | Precision | mAP@All mask | Size [mb] | Dataset | ONNXRuntime Throughput [fps] | DeepSparse Throughput [fps] |
| Dense | 0 | FP32 | 28.8 | 170.0 | COCO | 2.82 | 5.21 |
| Sparsified | 82 | INT8 | 28.2 | 9.7 | COCO | 6.10 | 21.12 |
Notice the difference in the size of those two models. The sparsified model is 17 times smaller than the dense model. However, this does not impact the quality of the model––expressed in terms of the mAP (mean Average Precision) metric.
Deploying the sparsified model in DeepSparse achieves significant speed gains. Inference is up to 7 times faster than its dense counterpart on ONNX Runtime. YOLACT is now fast enough to support real-time inference at batch size 1. This is great––a real-time instance segmentation model that runs exclusively on an edge CPU! Removing redundant information from the over-precise and over-parameterized network resulted in a faster and smaller model while retaining the original quality.
Final Thoughts
From the above benchmark, we see that the accuracy of the sparsified model is indeed at par with the dense model. That's remarkable. Even though we are keeping only two out of ten original neurons of the network plus quantizing them, there is no noticeable drop in inference quality. However, it’s important to note that models trained on the COCO dataset may not perform well for all image segmentation tasks due to the difference in the distribution of the dataset and data used for real-world inference. We recommend transferring the sparsified pre-trained instance segmentation network to your dataset in such cases.







