
May 02, 2023

Author(s)



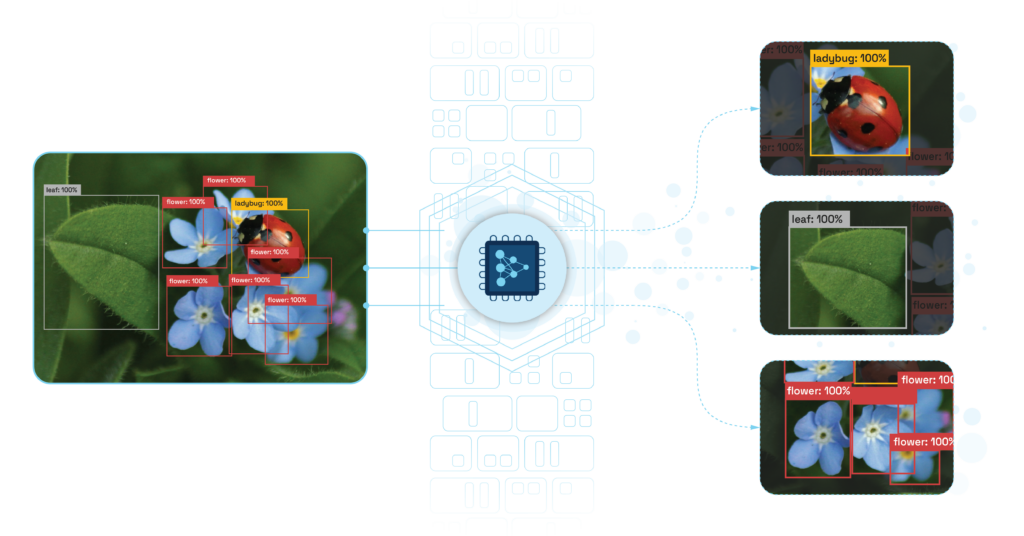
With conventional object detection models, it can be challenging to identify small objects due to the limited number of pixels they occupy in the overall image.
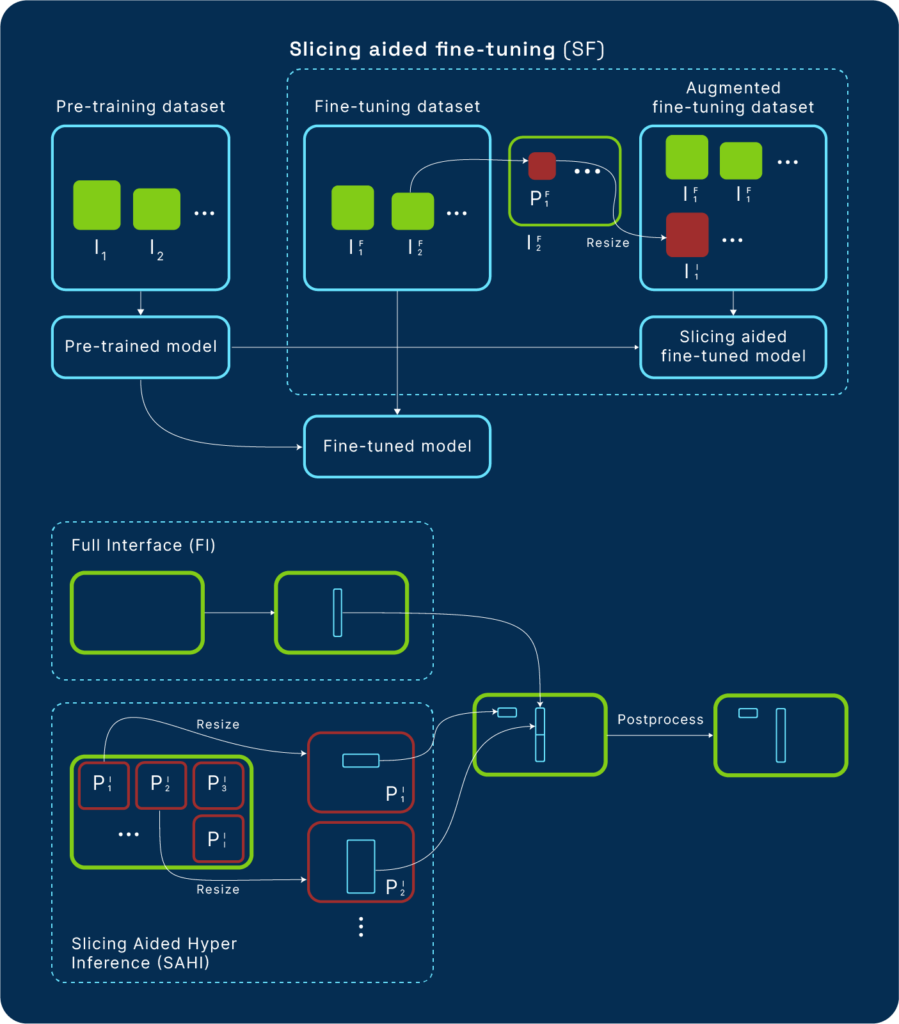
To help with this issue, you can use a technique like, Slicing Aided Hyper Inference (SAHI), which works on top of object detection models to discover small objects without the need to fine-tune. This method increases average precision by 6.8% on aerial object detection datasets, like Visdrone and xView, using the FCOS detector. Detection accuracy can be increased to 12.7% by slicing-aided fine-tuning. SAHI has been integrated with standard object detection models such as Detectron2, MMDetection, and YOLOv5.
Neural Magic's DeepSparse product is an inference runtime that supports various object detection models, such as YOLOv5 and YOLOv8. DeepSparse takes advantage of sparse models to offer GPU-class performance on CPUs. This blog will show you how to use SAHI and DeepSparse to deploy sparse YOLOv5 models for fast inference on commodity CPUs.
Slicing Aided Hyper Inference
Common object detection models offer excellent results on high-resolution images with large objects but perform poorly and yield lower accuracy on small object detection tasks with small and dense objects. Previous methods have tried to solve this problem, but require pre-training with large datasets, which can be costly. Other solutions are attached to specific detectors and are not generic. SAHI is a generic slicing-aided fine-tuning and inference pipeline that you can use on top of any object detector without the requirement to fine-tune the model or change its architecture.
Slicing-aided fine-tuning works by extracting patches from images and making them bigger. At inference, SAHI divides the image into smaller patches and makes predictions from the bigger versions of the patches. The predictions are then converted to the original image coordinates after non-maximum suppression (NMS).
Standard Inference With a YOLOv5 Model Using DeepSparse
Start by looking at the results from a standard sparse YOLOv5 model from SparseZoo without slicing-aided inferencing. Then compare these results with the ones obtained after using DeepSparse and SAHI. You can also follow along with this Google Colab notebook.
First, install SAHI and DeepSparse.
pip install sahi deepsparseNext, instantiate a sparse YOLOv5 model using SAHI.
from sahi import AutoDetectionModel
from sahi.utils.cv import read_image
from sahi.utils.file import download_from_url
from sahi.predict import get_prediction, get_sliced_prediction, predict
from IPython.display import Image
model_path = "zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned-aggressive_96"
detection_model = AutoDetectionModel.from_pretrained(
model_type='yolov5sparse',
confidence_threshold=0.3,
image_size = 640,
model_path = model_path ,
device="cpu", # or 'cuda:0'
)Define the model type as yolov5sparse to create a YOLOv5 pipeline using the model_path from SparseZoo.
from deepsparse import Pipeline
from sahi.models.yolov5sparse import Yolov5SparseDetectionModel
yolo_model = Pipeline.create(task="yolo", model_path=model_path)
yolov5_detection_model = Yolov5SparseDetectionModel(
model=yolo_model)Perform inference using the get_prediction function while passing a detection model.
download_from_url('https://raw.githubusercontent.com/obss/sahi/main/demo/demo_data/small-vehicles1.jpeg', 'demo_data/small-vehicles1.jpeg')
result = get_prediction("demo_data/small-vehicles1.jpeg", detection_model)
result.export_visuals(export_dir="demo_data/")
Image("demo_data/prediction_visual.png")
The small cars on the top right haven't been detected. Now try SAHI with the same sparse model and compare the results.
Sliced Inference With a YOLOv5 Model Using DeepSparse
First, perform sliced inference by defining the slice parameters. Then perform prediction over slices of 256x256 with an overlap ratio of 0.2.
result = get_sliced_prediction(
"demo_data/small-vehicles1.jpeg",
detection_model,
slice_height = 256,
slice_width = 256,
overlap_height_ratio = 0.2,
overlap_width_ratio = 0.2
)
result.export_visuals(export_dir="demo_data/")
Image("demo_data/prediction_visual.png")
With sliced inference, the smaller cars are now detected with standard inference.
Final Thoughts
Why would you use SAHI with the sparse YOLOv5 model and DeepSparse instead of the dense YOLOv5 model? First, the sparse YOLOv5 models are smaller and offer higher throughput and lower latency. Second, DeepSparse is built to leverage the model's sparsity to perform better than any other inference runtime.
Using a sparse-quantized YOLOv5 and DeepSparse on a 24-core C5 CPU instance on AWS achieves a throughput of 62.1 items/sec, which is 6.4X better than ONNX Runtime and almost at par with the best T4 implementation. Even with the dense YOLOv5 model, DeepSparse gets 18.9 items/sec, which is 2X better than the performance of 9.7 items/sec on ONNX Runtime.
DeepSparse is revolutionizing the deep learning space by offering better inference performance on commodity CPUs than GPUs. If this sounds interesting to you as it does to us, join other ML practitioners in the Neural Magic Community Slack as we continue to push the envelope in the computer vision space.
Reference: Slicing Aided Hyper Inference And Fine-Tuning for Small Object Detection







