
Jun 08, 2023

Author(s)


Neural Magic has added support for large language models (LLMs) in DeepSparse, enabling inference speed-ups from compression techniques like SparseGPT on commodity CPUs.
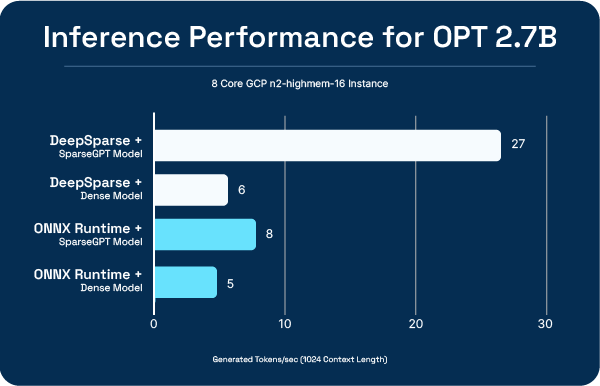
SparseGPT: Prune and Quantize LLMs Quickly With One-Shot
State-of-the art language models are very large with parameter counts in the billions. To deploy one is expensive and often requires multiple GPUs just to fit the parameters in memory.
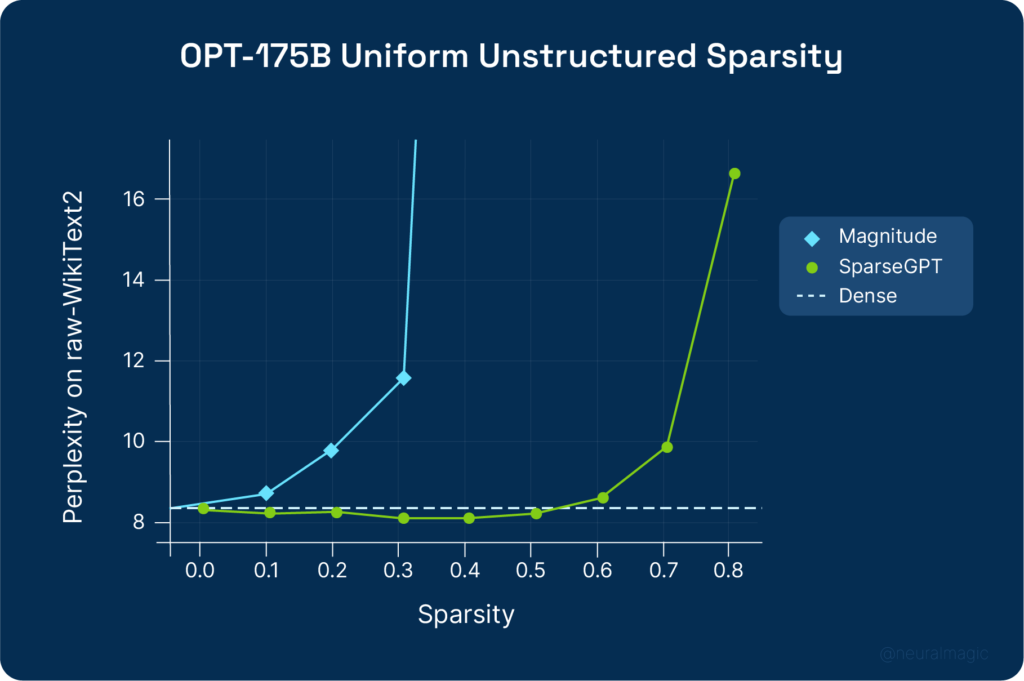
In a recent blog post, we highlighted SparseGPT, a pruning and quantization method for compressing large language models, such as OPT, efficiently and accurately. Unlike previous pruning methods, which require extensive retraining to recover lost accuracy, SparseGPT is a post-training technique which can be applied to a GPT-style model with 175B parameters in a couple of hours on a single GPU with minimal accuracy loss.
DeepSparse: Deploy Sparse LLMs at Scale on Commodity CPUs
While SparseGPT demonstrates how to compress a GPT-style model, a sparsity-aware inference runtime is needed to actually increase the speed of the model in production.
DeepSparse, Neural Magic’s inference runtime, is highly optimized to take advantage of pruning and quantization in order to improve performance on CPUs. In addition to encoder-only transformers architecture like BERT, DeepSparse now supports speedups from pruning and quantization with decoder-only generative models like OPT. This means that generative models can now run performantly on commodity CPU-hardware.
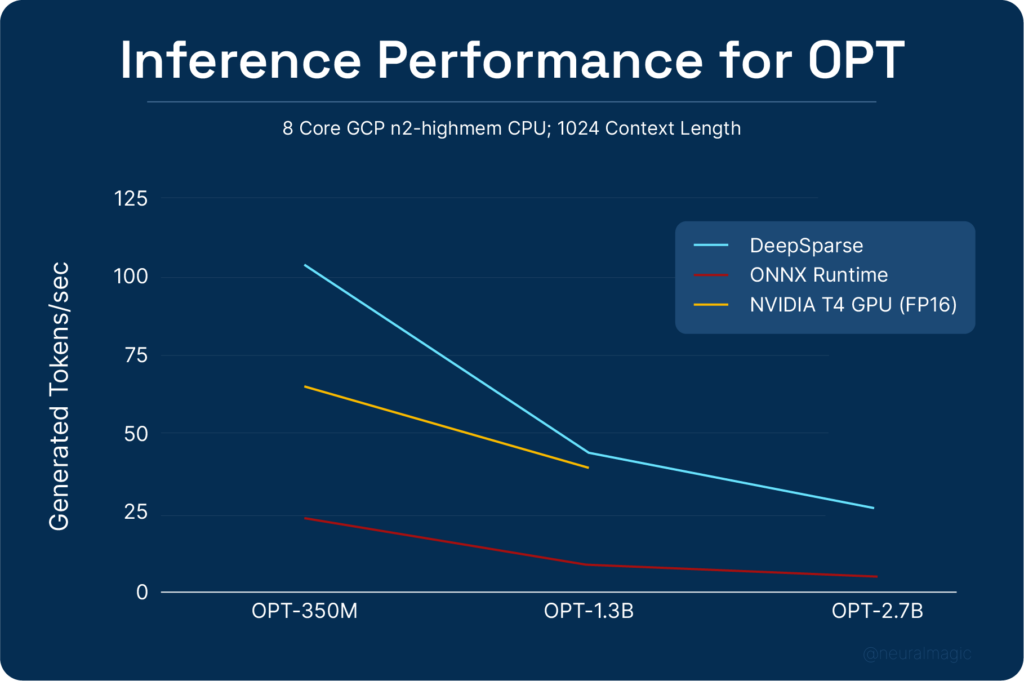
The result is strong performance on OPT models, on readily available CPUs. With the sparse-quantized OPT model, DeepSparse is ~5x faster than ONNX Runtime on an 8 core machine and exceeds the inference speed of a T4 GPU running an FP16 model.
Advantages of CPU Deployments
With DeepSparse, generative models can now run performantly on ubiquitous, commodity CPUs, simplifying the IT operations needed to deploy and manage LLMs in production.
- Extreme Flexibility - deploy anywhere you have compute capacity, including on existing hardware, in the cloud, and at the edge
- Built-in Scalability - scale up and down from 2 to 192 cores, scale out with standard orchestration tools like Kubernetes, and fully abstracted with serverless
- Simple Deployment - fully Dockerized to enable easy integration with industry standard “deploy-with-code” tools
- Faster Time To Market - quickly get into production with no dependency on hardware accelerators
Final Thoughts
At Neural Magic, we see an effort being made to democratize LLMs through open-source models and data. We believe that in order to truly democratize LLMs you need to be able to run them on commodity hardware, not just specific, required hardware. This is why we are fast at work to make our runtime, sparsification tools, and sparse models (including modern, chat-aligned LLMs) available for use by the community. We believe through better deployment infrastructure and community sharing that we can, together, further advance the large generative AI industry.
Sign up for the Sparsify Alpha to gain early access to our one-shot sparsification capabilities.
"SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot." arXiv, 19 January 2023, https://arxiv.org/pdf/2301.00774.pdf







