

Oct 12, 2023

Author(s)



The arrival of capable open-source large language models (LLMs) like MosaicML’s MPT and Meta’s Llama 2 has made it easier for enterprises to explore generative AI to address their business challenges. Yet, adoption of open-source models for commercial applications is still hampered by two key problems:
- First, out-of-the-box LLMs often struggle with domain-specific tasks in business settings, especially if proprietary knowledge, that is not available on the Internet, is required.
- Second, LLMs are, well, large, which make production deployments cumbersome and expensive.
In our recent paper, Sparse Fine-Tuning for Inference Acceleration of Large Language Models, Neural Magic and the Institute of Science and Technology Austria (ISTA) collaborated to explore how fine-tuning and sparsity can come together to address these issues, to enable accurate models that can be deployed on CPUs.
8-Core AVX-512 VNNI System
Experimental Setup
In our experiment, we studied MPT-7B and the GSM8k dataset.
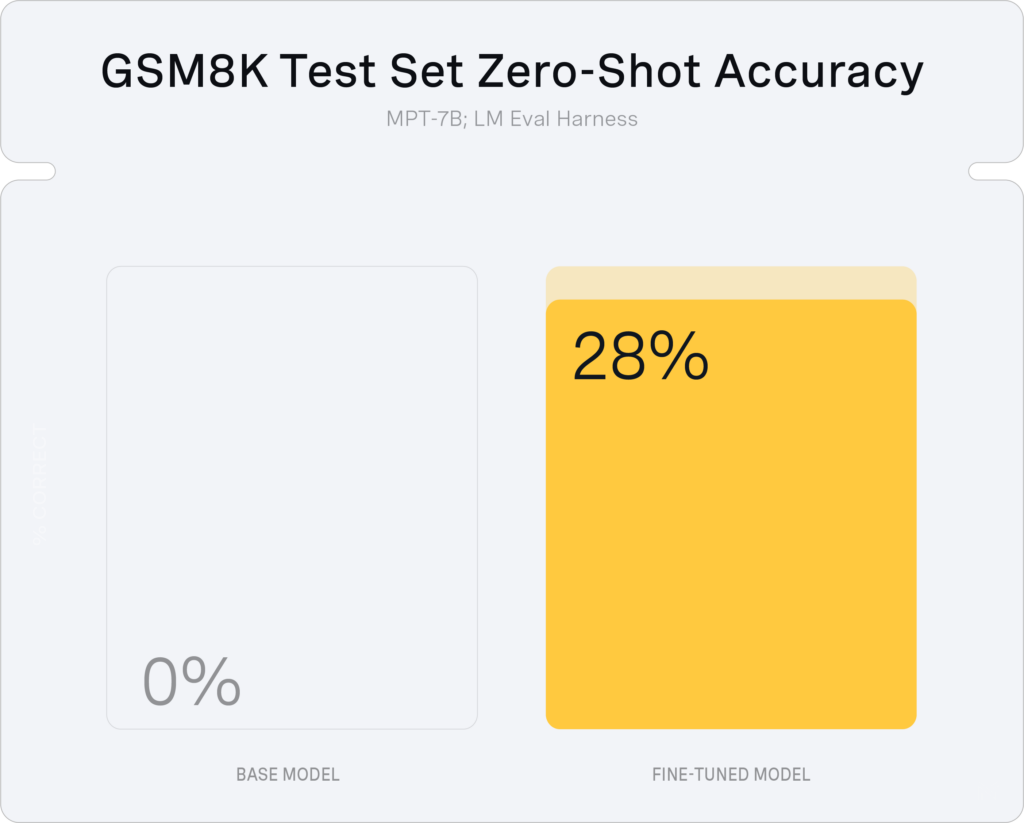
GSM8k is a dataset of high-quality and diverse grade school math problems that is extremely challenging for LLMs. For instance, in zero-shot mode, the base MPT-7B model completely fails with an accuracy of 0%. While accuracy on grade school math is not a particularly interesting application, GSM is an example of a common problem organizations encounter when they try to adopt LLMs for business applications: the base LLMs often do not know how to solve specialized tasks.
Question: Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
Answer: Natalia sold 48/2 = <<48/2=24>>24 clips in May. Natalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May. #### 72A training example in GSM8k. The task requires multi-step reasoning.
Fine-Tuning
Training LLMs consists of two steps. First, the model is pre-trained on a very large corpus of text (typically >1T tokens). Then, the model is adapted for downstream use by continuing training with a much smaller high quality, curated dataset. This second step is called fine-tuning.
Fine-tuning is useful for two main reasons:
- It can teach the model how to respond to input (often called instruction tuning).
- It can teach the model new information (often called domain adaptation).
In the case of GSM (as well as for many business use cases), domain adaptation is valuable as the baseline model does not know how to solve the problem. By fine-tuning MPT-7B for two epochs on GSM, which contains just ~7k examples, we can dramatically improve the test set accuracy:
Sparse Fine-Tuning
While fine-tuning helps to solve the issue of poor accuracy with a base model on GSM8K, the resulting dense model is still cumbersome to deploy, requiring GPUs to reach acceptable performance.
To address this problem, quantization techniques (like GPTQ from ISTA) have been developed to compress weights to 4 bits almost without loss. However, these methods, reach a limit at around 2-3 bits per weight, at which point it is harder to recover accuracy.
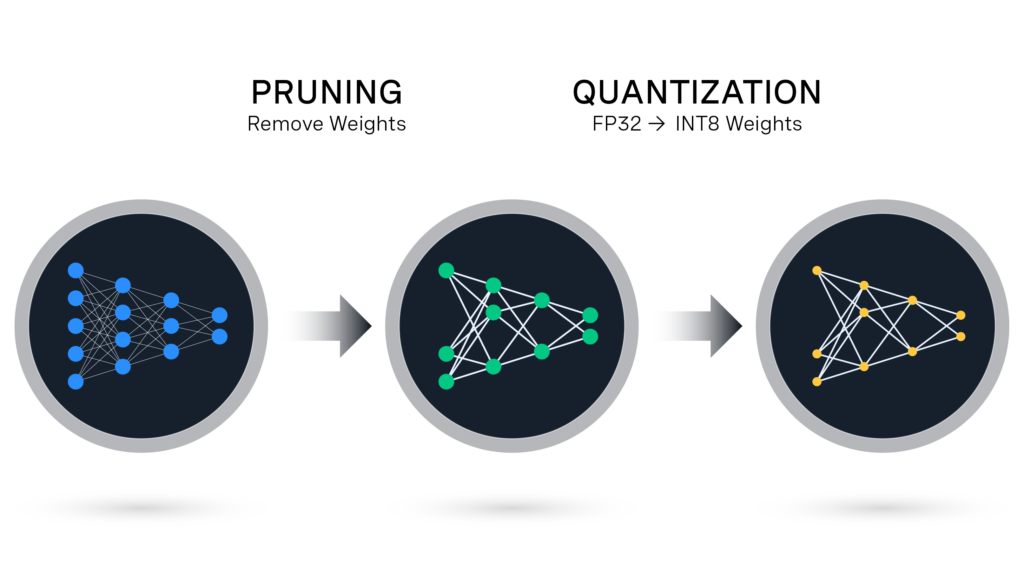
Weight sparsity, which consists of pruning individual weights from a neural network by setting them to zero, can be combined with quantization to compress models even more. In the past, Neural Magic has pruned smaller models like BERT to >90% sparsity, but it had not been confirmed whether these techniques can be applied to the scale of LLMs.
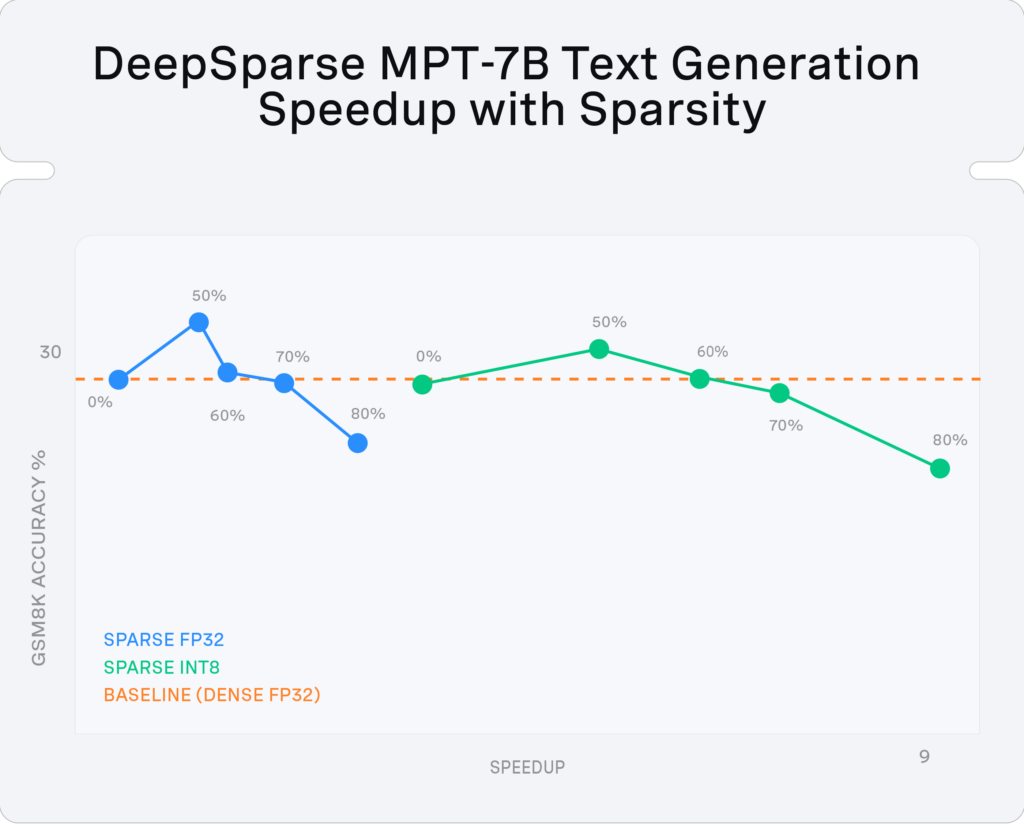
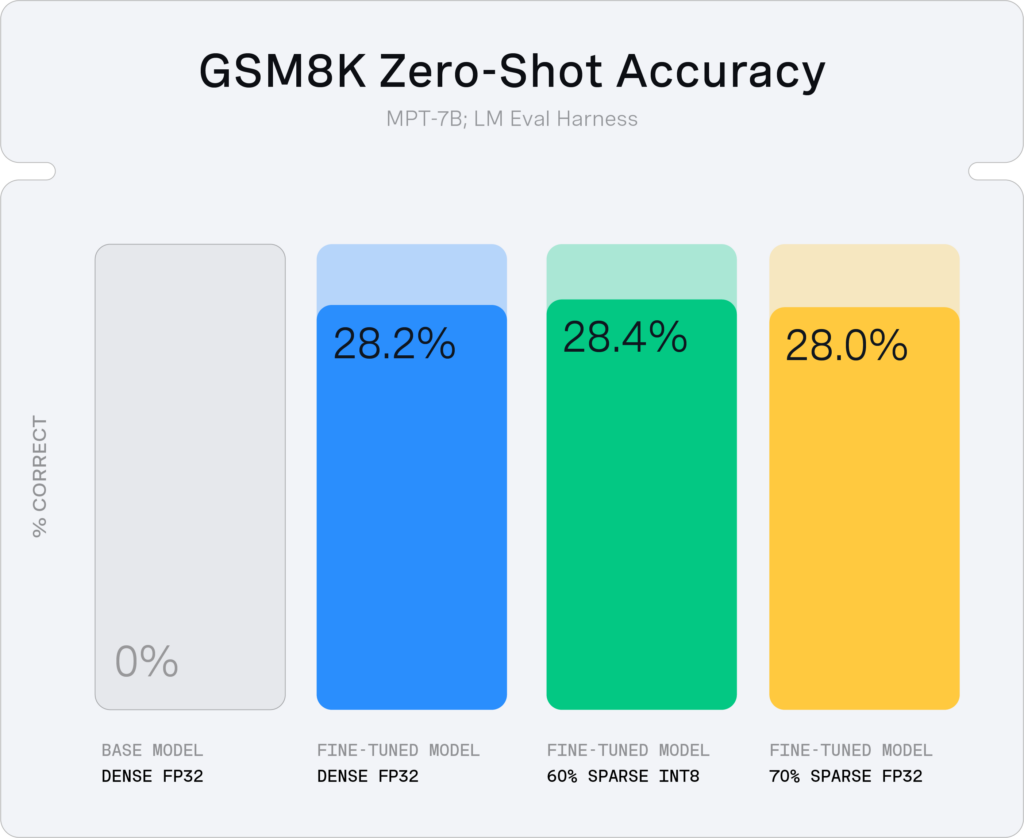
Our result demonstrates that we can prune MPT-7B during fine-tuning on GSM8k to ~60% sparsity with quantization and 70% sparsity without quantization with no accuracy drop:
DeepSparse: Accelerating Sparse-Quantized LLMs on CPUs
Neural Magic DeepSparse is a CPU inference runtime that implements optimizations to take advantage of sparsity and quantization to accelerate inference performance. DeepSparse supports a large variety of model architectures including CNNs like YOLO and encoder-only transformers like BERT. Over the past several months we have adapted DeepSparse to support the decoder-only architecture used by popular models like Llama 2 and MPT with specialized infrastructure to handle KV-caching and new sparse math kernels targeted at the key operations underlying decoder models.
With DeepSparse, we accelerated the 60% sparse-quantized MPT-7B by ~7x relative to the dense baseline, to reach 26 tokens/second with just 8 CPU cores and 4GB of memory.
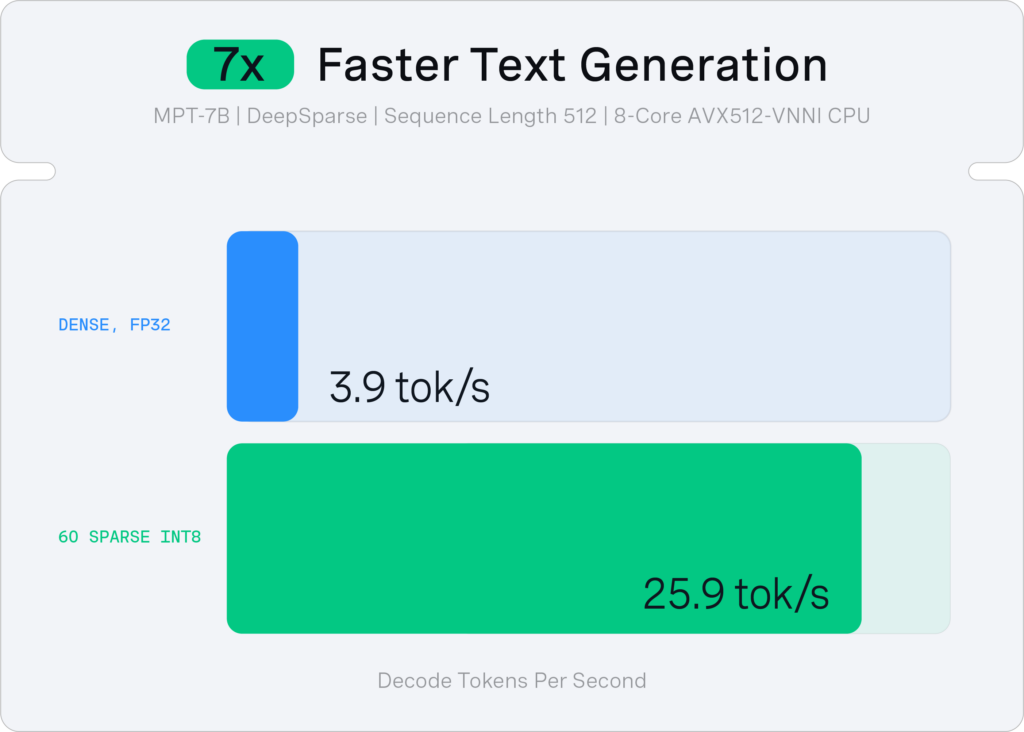
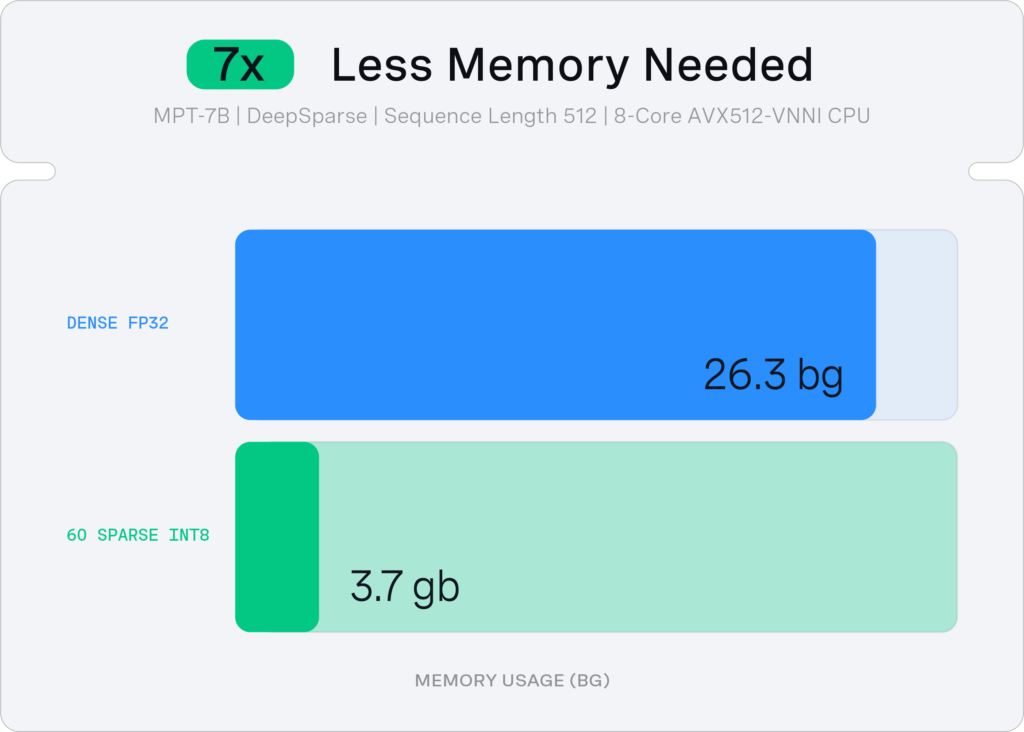
Conclusion
In summary, Sparse Fine-Tuning in combination with sparsity-aware inference software, like DeepSparse, unlocks ubiquitous CPU hardware as a deployment target for LLM inference. Using these techniques, businesses can adapt open-source models to their specific in-domain tasks and deploy models using hardware they already own and know how to operate.
What’s Next?
This research is an example of our continued commitment and focus on industry-leading LLM optimization. We will continue to expand this research and deliver value to customers and the community through fast CPU inferencing of LLMs run on DeepSparse.
We will launch production support for LLMs across the Neural Magic stack in the coming weeks, along with published benchmarks, example usage, and new models in SparseZoo. Three primary focus areas include:
- Productizing Sparse Fine-Tuning: We are adapting our research code into SparseML to enable external users to apply Sparse Fine-Tuning to their business datasets.
- Expanding model support (to Llama 2): We will apply Sparse Fine-Tuning to other model architectures such as the popular Llama 2.
- Pushing to higher sparsity: We continue to improve our pruning algorithms to reach higher levels of sparsity (and therefore achieve more inference acceleration).
Want to learn more?
- Check out DeepSparse running GSM8k live on Hugging Face Spaces.
- Visit our GitHub to try running LLM inference with DeepSparse.







