

Apr 05, 2023

Author(s)


Six months ago, Neural Magic shared remarkable MLPerf results, with a 175X increase in CPU performance, attained using sparsity. This breakthrough was achieved exclusively with software, using sparsity-aware inferencing techniques. The impressive outcomes showcased the potential of network sparsity to enhance the performance of machine learning models on readily available CPUs. This advancement empowers individuals and businesses to deploy scalable, high-speed, and accurate machine learning (ML) models without investing in costly hardware accelerators. Building upon our previous submission, we are thrilled to reveal results that showcase a 6X improvement, elevating our overall CPU performance boost to an astounding 1,000X.
“We are so excited about our latest performance results, validated by MLPerf™ Inference v3.0,” said Brian Stevens, Chief Executive Officer, Neural Magic. “By applying our specialized compound sparsity algorithms with our patented DeepSparse inference runtime, we were able to achieve a boost in CPU performance by 1,000X while reducing power consumption by 92% over other inference solutions. The numbers prove users can have GPU speeds to support AI projects with just software and off-the-shelf processors.”
This year, Neural Magic used 4th Gen AMD EPYC™ processors for our benchmark testing. Neural Magic’s software stack takes advantage of continued innovations in the 4th Gen AMD EPYC™ processors, such as AVX-512 and VNNI instructions, as well as advanced features like highly performant DDR5 memory and a core count up to 96 cores, to unlock new possibilities for delivering better than GPU speeds on x86 CPUs.
“Neural Magic’s MLPerf™ Inference 3.0 results, benchmarked using our latest 4th Gen AMD EPYC™ processors, prove customers can achieve outstanding levels of AI inference performance for deep learning on x86 based CPUs,” said Kumaran Siva, Corporate Vice President, Strategic Business Development, AMD.
Our continued work with AMD illustrates the power of software-delivered AI. As generational processor improvements are made on CPUs, sparsified models automatically make the most of those enhancements without any change to the model itself. For example, during the launch of the latest 4th generation AMD EPYC™ processors, we were able to inference double the amount of video feeds without any subsequent changes to the computer vision models themselves. And with the extreme amount of compute power in these latest chips, you could power over 300 cameras on just one server. This “optimize once, run anywhere” mindset means you can focus on building innovative solutions rather than optimizing your ML models for specific hardware.
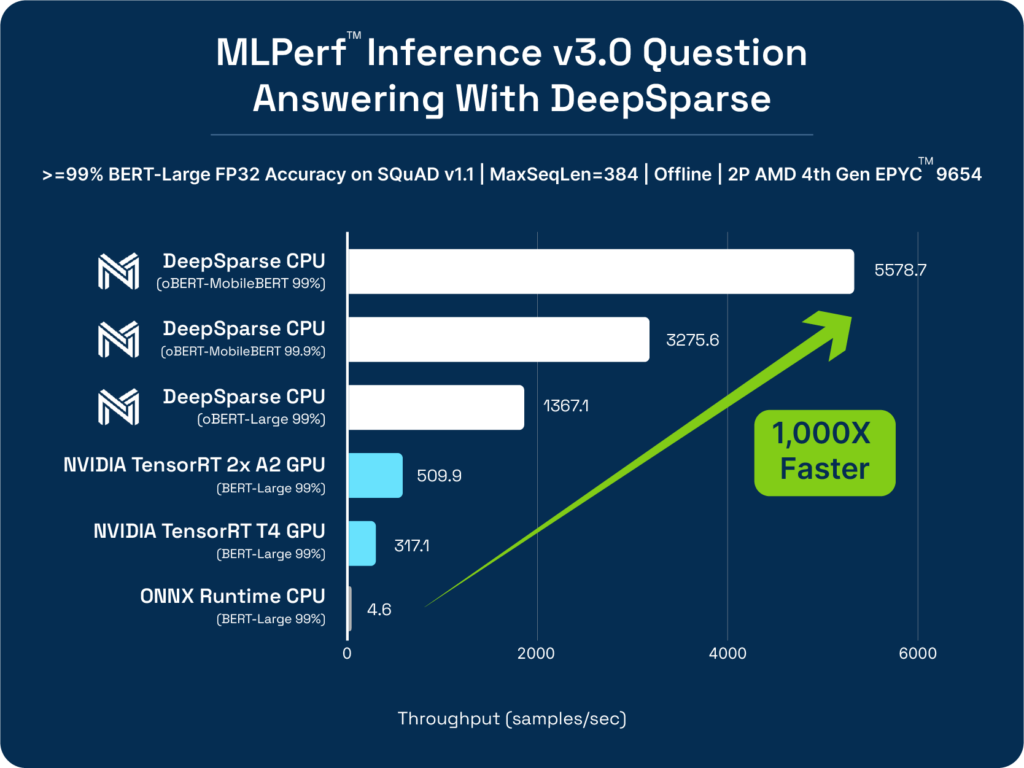
Compound Sparsity Paves Way for Efficient ML Execution
Neural Magic’s MLPerf Inference v3.0 submission offers exciting advancements in AI inference performance using only a CPU. These breakthroughs have far-reaching implications, as they enable high-performance AI which was previously only achievable using hardware accelerators. The results were achieved by applying compound sparsity, a model compression technique that combines various model optimization strategies such as unstructured pruning, quantization, and knowledge distillation. To better understand the significance of these results, let's delve into the details and explore their potential impact.
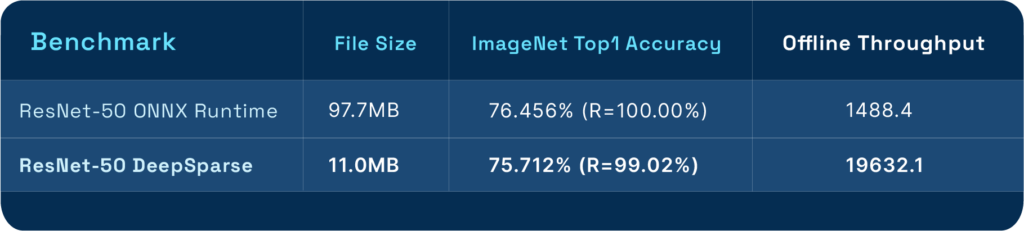
Our sparsified ResNet-50 image classification model achieved a remarkable processing speed of 19,632 images per second (FPS), compared to ONNX Runtime at 1,488 FPS and NVIDIA T4 at 4,888 FPS. ResNet, a popular deep learning architecture for image classification, is widely used across various industries as a backbone for tasks such as object detection, facial recognition, and autonomous vehicle perception systems.
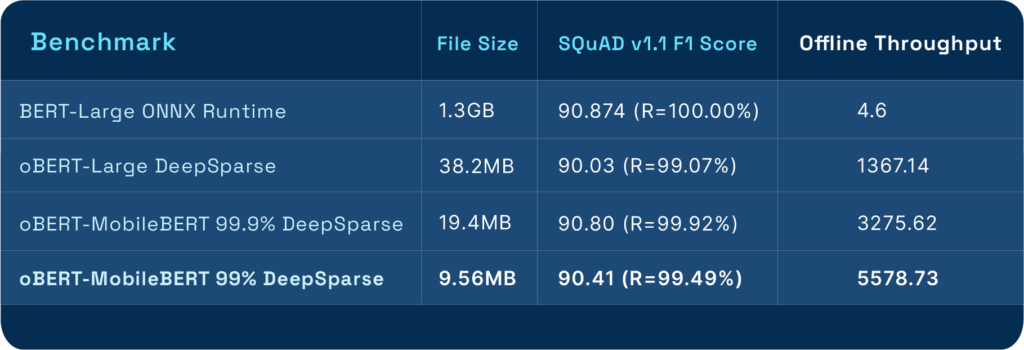
Our sparsified BERT, a powerful natural language processing model, attained a processing speed of 5,578 items per second, outperforming competitors like ONNX Runtime and NVIDIA T4. This improvement is essential for applications that rely on understanding and generating human-like text, such as chatbots, sentiment analysis, and language translation.
In addition to applying compound sparsity, we leveraged DeepSparse, our inference runtime, that is specifically engineered to accelerate the performance of sparse models on CPUs. Our submission shows the power of compound sparsity as a model compression technique. Overall, we were able to:
- Sparsify ResNet-50 to 11MB and BERT-Large to 10MB.
- Achieve a 19,632 samples/sec throughput on ResNet-50, a 13X improvement in performance.
- Boost the performance of BERT question answering to 5,578 samples/sec representing a 1,000X improvement.
Results below were obtained using a server with 2P 4th Gen EPYC™ 9654 96-Core CPUs.*

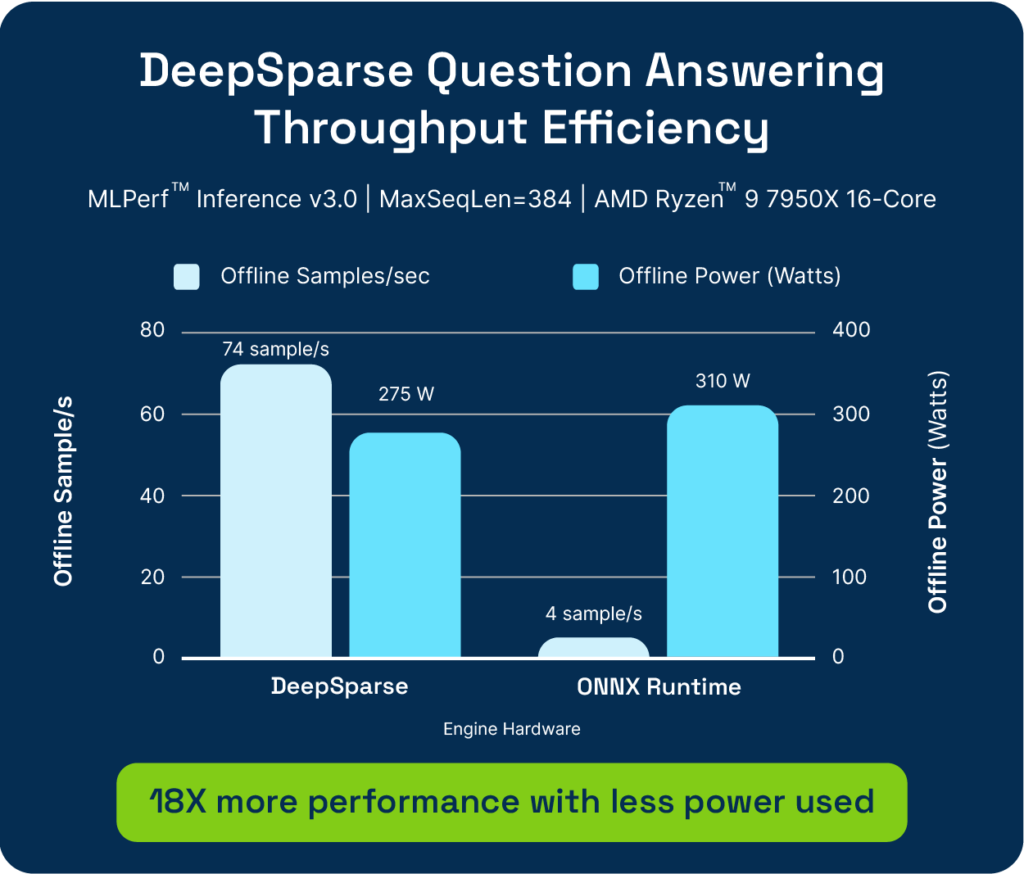
Leveraging Sparsity for Optimal Power Performance
For many organizations, optimizing power efficiency is a top priority, especially when it comes to inference deployment, as it competes for space and power resources. At Neural Magic, we recognize these challenges and are committed to delivering solutions that strike the right balance between performance and power efficiency. In this section, we show the significant enhancements in both performance and energy consumption that we have achieved, as evidenced by our results in the MLPerf Inference v3.0 benchmark.
Due to DeepSparse's strength in CPU inference optimization, our approach is remarkably power efficient and demonstrated a 92% efficiency improvement over ONNX Runtime for BERT on a desktop AMD Ryzen™ 9 7950X 16-Core CPU. This efficiency is crucial for businesses that need to manage large-scale AI deployments while keeping latency, energy consumption, and operational costs in check.

Resources and Next Step
Neural Magic continues to push boundaries to make it possible to achieve GPU-class performance on commodity CPUs by providing developers with the tools they need to introduce compound sparsity in their ML models.
SparseML enables you to quickly sparsify models, while DeepSparse boosts performance at inference by reducing latency and increasing throughput without negatively impacting accuracy.
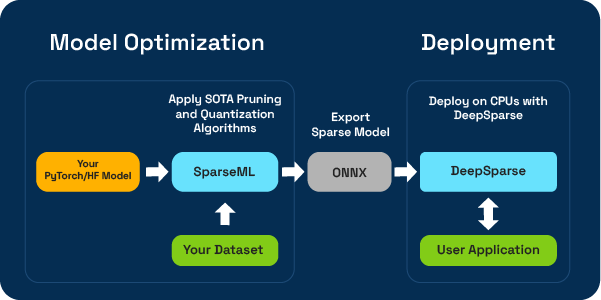
Neural Magic also provides sparsified models for common ML models such as YOLO, YOLACT, BERT, ResNet, and more. This means that you can pick a sparse model and quickly transfer it to your dataset.
If you have questions, get direct access to our engineering teams and the wider community in the Neural Magic Community Slack.
To keep up with our mission of efficient software-delivered AI, please star our GitHub repos and subscribe to our monthly newsletter below.
*Neural Magic measured results on AMD reference systems as of 2/3/2023. Configuration: 2P EPYC 9654 96 core “Titanite” running on Ubuntu 22.04 LTS, Python 3.9.13, deepsparse==1.4.0







