

Sep 08, 2022

Author(s)

Neural Magic Announces MLPerf Inference Benchmarks, Delivered Purely in Software
Somerville, Massachusetts, September 8, 2022 - Neural Magic, the company leading a new software-delivered AI movement by bringing hyper-performant and scalable ML inferencing to commodity CPU infrastructure, announced today its benchmark results for three Natural Language Processing (NLP) models submitted to the MLPerf Inference Datacenter and Edge v2.1 Open division. The results demonstrate the power of neural network sparsity and sparsity-aware inferencing, marking an important milestone in faster, more-efficient machine learning execution using commodity CPU resources.
“We are excited to partner with MLCommons to introduce the power of sparsity and smarter network execution to the world of machine learning,” said Brian Stevens, CEO of Neural Magic. “Sparsity and sparsity-aware execution is paving the way for efficient machine learning where individuals and businesses alike are able to deliver big model accuracy with all the perks of smaller models, using commodity CPUs that are easier to access and scale.”
Compound Sparsity Paves Way for Efficient ML Execution
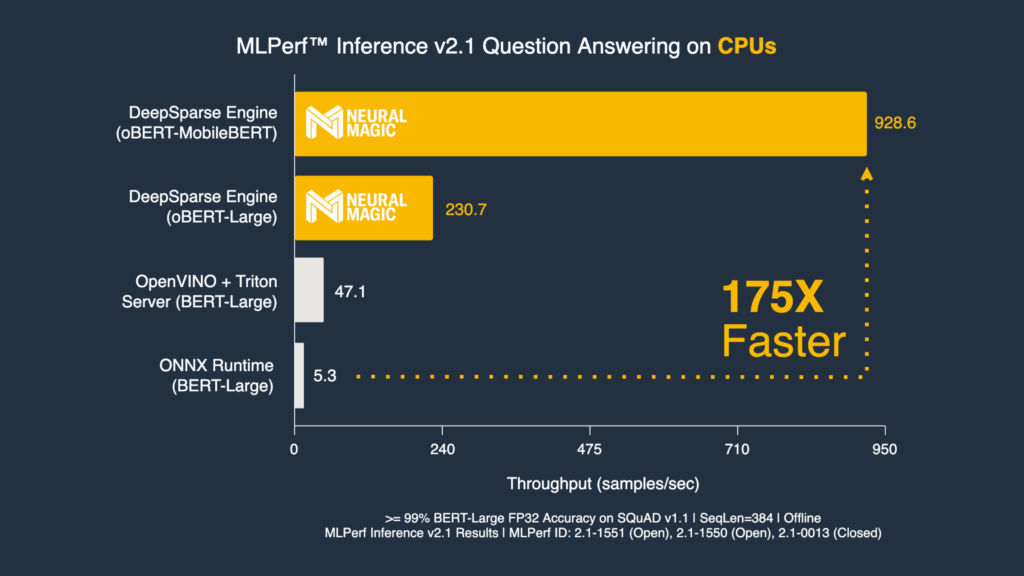
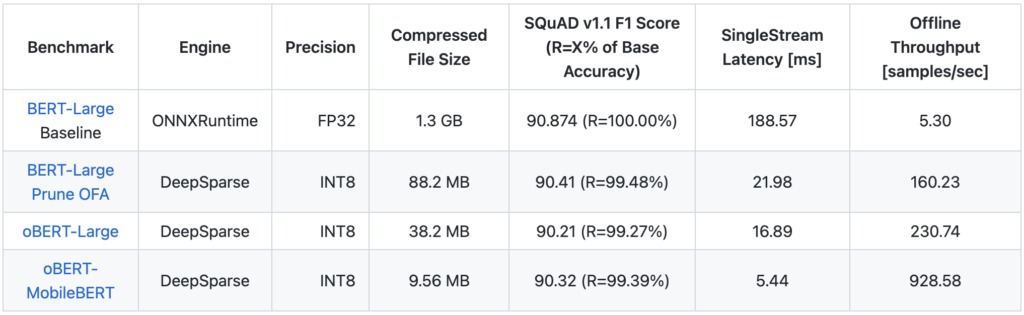
Neural Magic’s MLPerf Inference Datacenter and Edge v2.1 submission shows three different methods of optimizing BERT-Large, a very accurate NLP model that’s hard and often uneconomical to deploy due to its slow inferencing times and large disk space requirements.
Enter compound sparsity, a tactic of applying various compression methods to deep learning models, including unstructured gradual pruning, quantization-aware training, and structural distillation.
Neural Magic’s MLPerf Inference Datacenter and Edge v2.1 Open division benchmarks show the true power of compound sparsity when applied to the SQuAD v1.1 question answering task by:
- Maintaining >99% of its original F1 score (meaning <1% accuracy degradation!)
- Decreasing model size from 1.3 GB to ~10 MB
- Improving throughput performance by orders of magnitude from ~10 samples/second to up to 1,000 samples/second when executed in the sparsity-aware DeepSparse Engine
More details on each of the models and methods can be found on GitHub under Neural Magic's BERT-Large DeepSparse MLPerf Submission.
Detailed model methods:
- oBERT-MobileBERT: The Optimal BERT Surgeon Applied to the MobileBERT Model
- oBERT-Large: The Optimal BERT Surgeon Applied to the BERT-Large Model
- BERT-Large Prune OFA - Prune Once for All: Sparse Pre-Trained Language Models
Resources and Next Steps
Our research on compound sparsity is open-sourced and easily reproducible via SparseML. It’s applicable to NLP and computer vision models, including BERT, ResNet, YOLO, YOLACT, and more. With only a few lines of code, you can transfer learn our optimizations to numerous tasks including question answering, text classification, token classification, object detection, image classification, image segmentation, and more.
Our sparsity-aware DeepSparse Engine is freely available for community use. It delivers the best inference performance on commodity CPUs and it fits seamlessly into your existing deployment pipelines.
If you have any questions, get direct access to our engineering teams and the wider community in the Deep Sparse Community Slack.
To keep up with our mission of efficient software-delivered AI, please star our GitHub repos and subscribe to our monthly newsletter below.






