

Nov 10, 2022

Author(s)


As machine learning models grow larger and larger, the demands for hardware to run those models also continue to grow. At Neural Magic we are helping to alleviate these hardware pressures with a truly software-delivered AI solution that allows organizations to get extreme machine learning performance with commodity hardware only. Today, we are excited to share that we are extending our state-of-the-art machine learning to 4th Gen AMD EPYC™ CPUs, which efficiently deliver impressive performance and help pay real dividends when running AI workloads. In collaboration with AMD, Neural Magic is helping customers run even more machine learning within their hardware budgets.
“Our close collaboration with Neural Magic has driven outstanding optimizations for 4th Gen AMD EPYC™ processors,” said Kumaran Siva, Corporate Vice President, Software & Systems Business Development, AMD. “Their DeepSparse Platform takes advantage of our new AVX-512 and VNNI ISA extensions, enabling outstanding levels of AI inference performance for the world of AI-powered applications and services”
It Starts With Better Software
In a previous blog post, we dove into the technical aspects of how combining the Neural Magic DeepSparse Engine and SparseML libraries speeds up machine learning execution with 3rd Gen AMD EPYC CPUs with 3D V-Cache™. The ability to leverage the large and fast caches of existing CPU architectures via our Deep Tensor Column technology, combined with the optimization of the machine learning models themselves through a process called Sparsification, has been shown to result in machine learning models that are smaller in size, equally as accurate, and many times more performant than even expensive hardware-accelerated compute platforms.
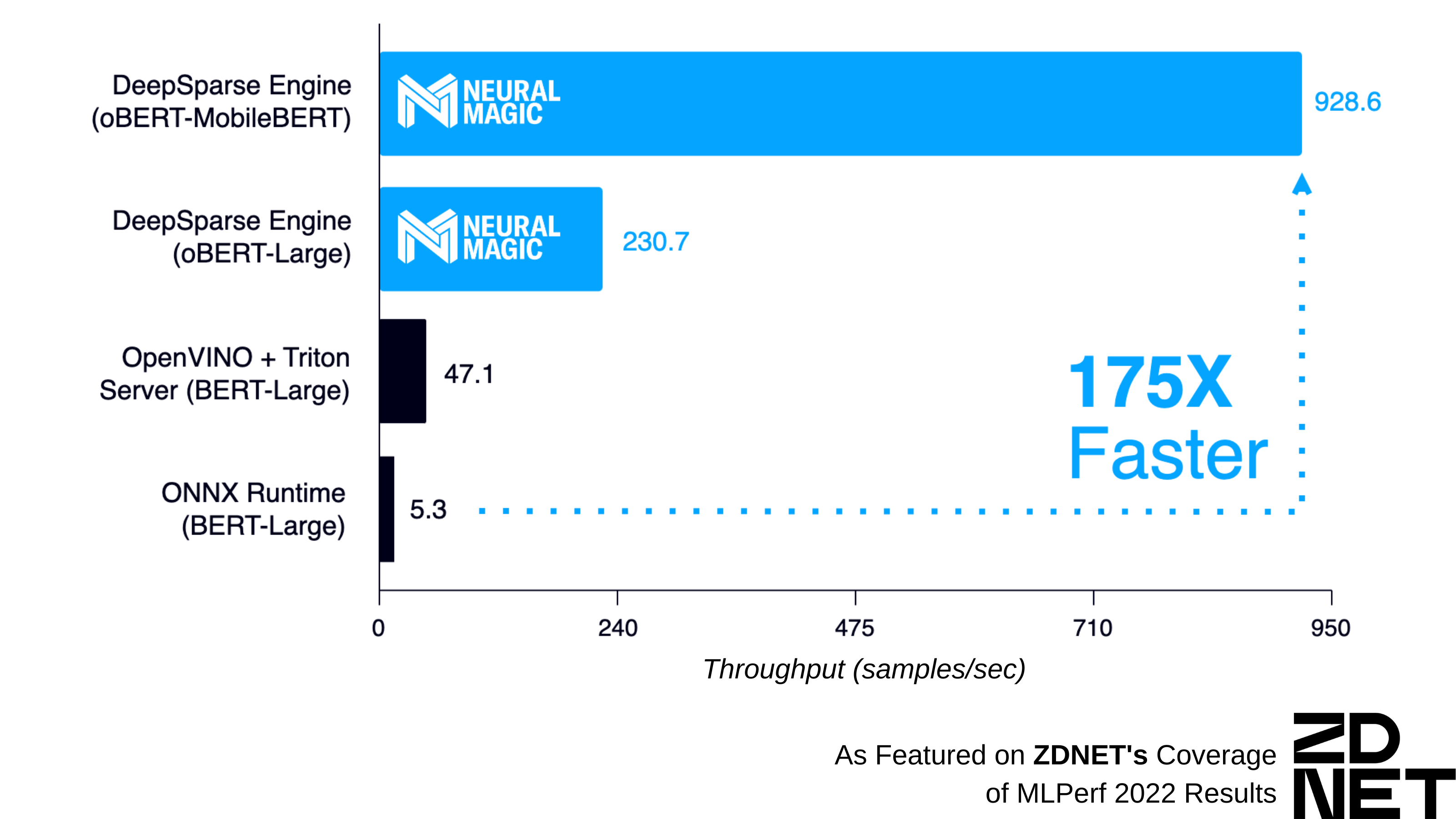
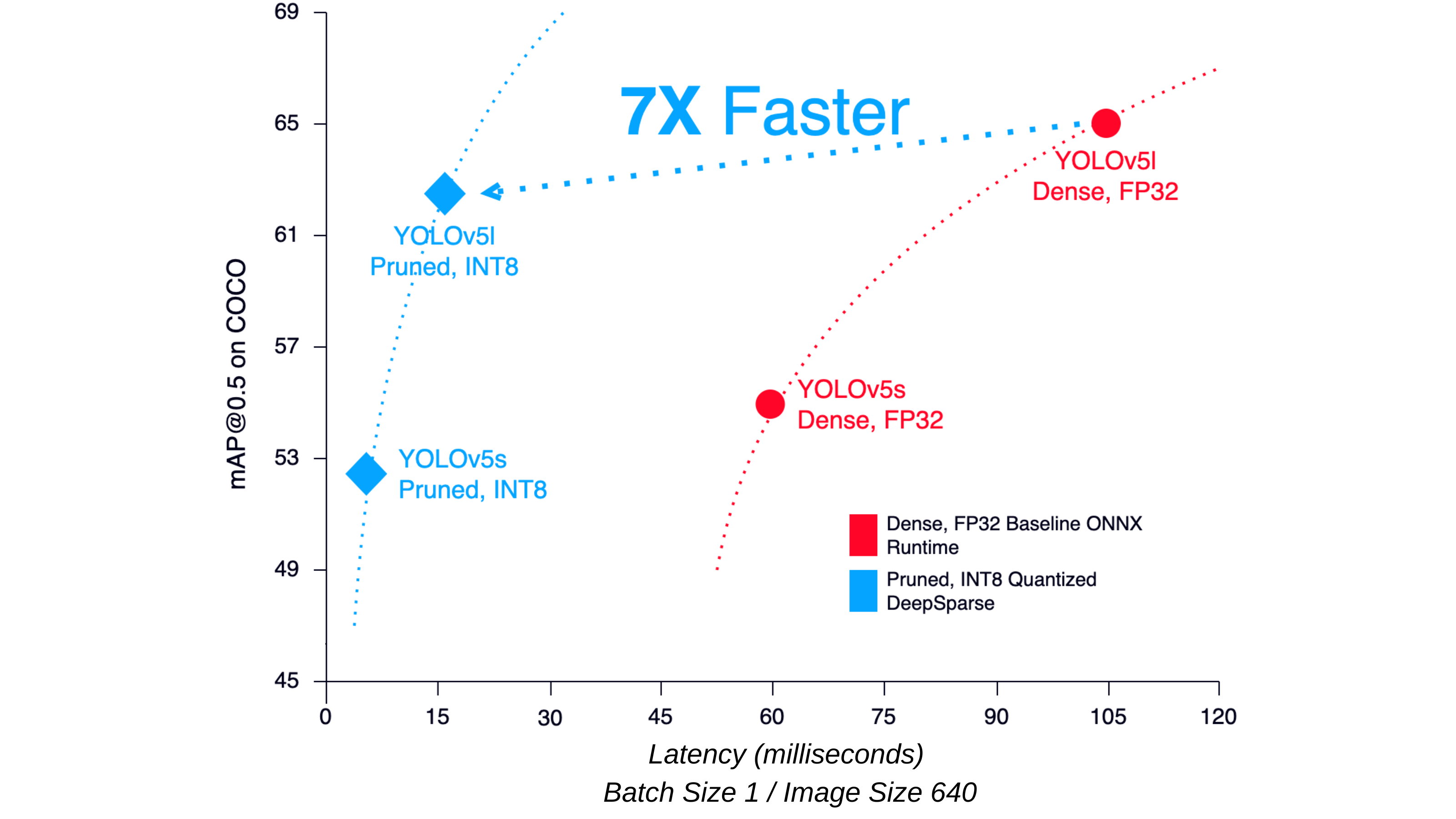
Figure 1: BERT, a popular Natural Language Processing model (left) and YOLOv5, a popular Object Detection (right) performance comparison between Neural Magic DeepSparse Engine and ONNX Runtime. Results recorded on a 4th Gen AMD EPYC CPU with 24 cores.
In collaboration with AMD, and now with the release of the 4th Gen AMD EPYC CPUs, we are pushing this performance even further.
Better Hardware, Even Better Results
Neural Magic’s software takes advantage of the latest enhancements in the new 4th Gen AMD EPYC processors such as the high performant DDR5 DIMMs, fast PCIe® Gen 5 I/O and CXL™1.1+ memory expansion, the increase in core count up to 96 cores, and the inclusion of AVX-512 and VNNI instructions so that customers can realize an almost 4x performance boost over the prior generation processors. This means more machine learning processing power for your compute dollar than previously possible. For the results shown in this blog, the following configurations were used: 2P 4th Gen EPYC 9654 96 core CPUs and 2P 3rd Gen EPYC 7763 64 core CPUs1.
“We are very excited about the commitment AMD has to continuously improving x86 architecture,” said John O’Hara, VP of Engineering at Neural Magic. “Together with Neural Magic, the bar is being raised for those who want to run AI at the intersection of performance and efficiency.”
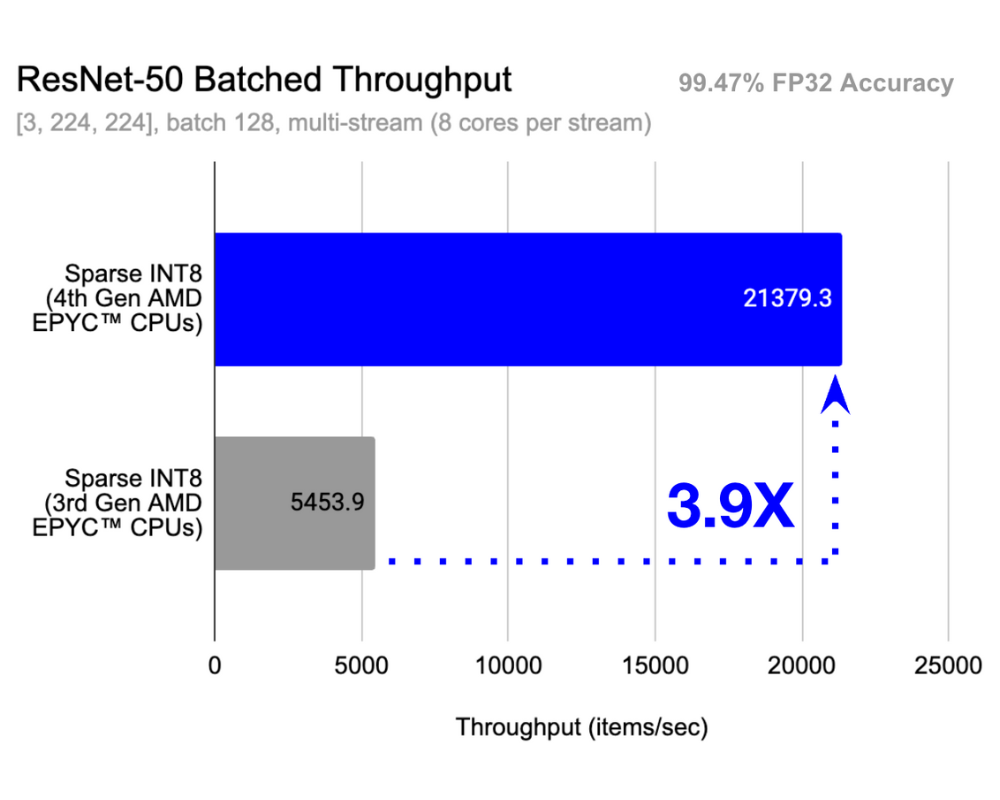
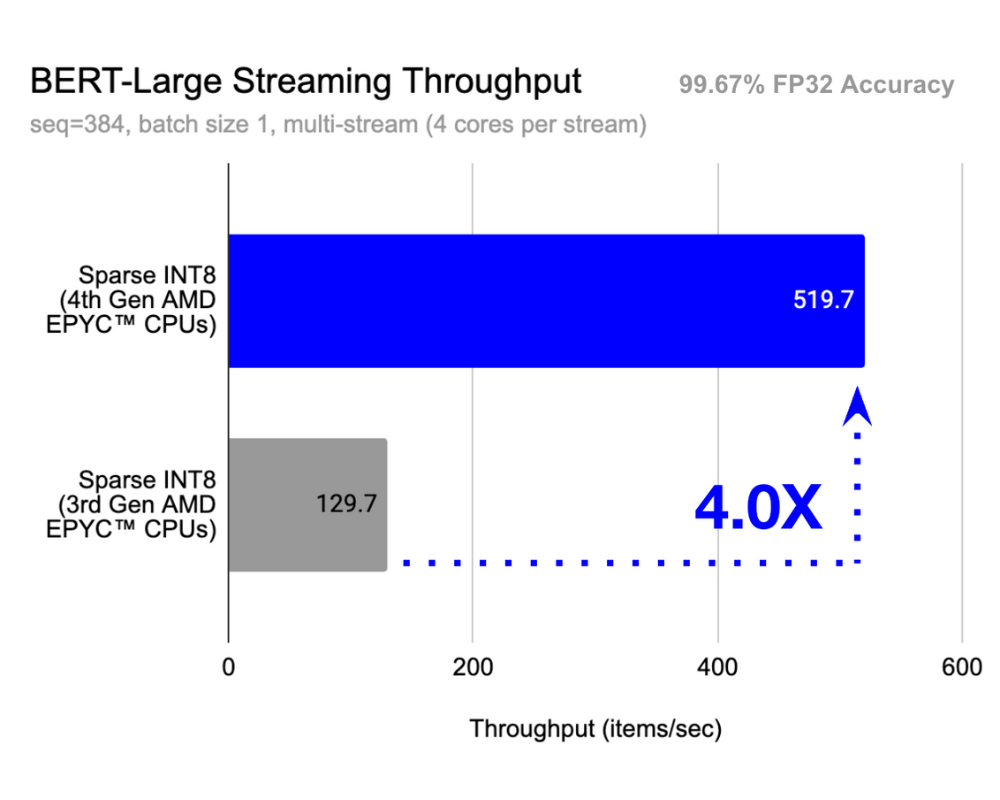
Figure 2: Dual socket AMD EPYC CPU1 throughput performance for ResNet-50, a popular Image Classification model (left) and BERT-Large, a popular Natural Language Processing model (right). Both Sparse-INT8 models deliver less than 1% accuracy degradation.
A Video Is Worth a Billion Words
More performance from your machines gives you flexibility and unlocks value for your business when you can use fewer servers for the same work, or do more work with the same servers. Neural Magic enables machine learning workloads to leverage this same flexibility. To exemplify this, we benchmarked a sparsified YOLOv5 model for object detection on both 3rd Gen and 4th Gen AMD EPYC CPUs to determine how many video streams, and at which frame rates, object detection could be processed on a single server1. All experiments below were conducted in multi-stream scenarios using latency-optimized batch sizes of 1. On 3rd Gen EPYC, we were able to support 18 camera feeds at 30 frames per second (fps). This was best-in-class performance for doing object detection on AMD CPUs at the time.
3rd Gen AMD EPYC™ CPUs + Neural Magic DeepSparse
18 Cameras at 30 FPS
With the new aforementioned enhancements to the 4th Gen AMD EPYC CPUs, in conjunction with continuous performance improvements to the DeepSparse Engine, we have observed a dual socket server supporting 64 cameras. This is a full 3.5x the camera feeds of the prior 3rd Gen EPYC processors. In many cases, this could power a retail store or a manufacturing floor where businesses often strive to improve customer experiences, respond to spillage or spoilage, help ensure safety, or observe traffic patterns with machine learning at scale but struggle with the amount of compute required to do so.
4th Gen AMD EPYC™ CPUs + Neural Magic DeepSparse
64 Cameras at 30 FPS
Imagine what this could mean for your scenarios. Let’s take the example of processing object detection across multiple camera streams a step further. If you only need to process video feeds at a rate of 3 or 5 frames per second, as many customers have claimed, then additional metrics show that one dual socket 4th Gen AMD EPYC server powered by Neural Magic’s DeepSparse would be capable of processing 300 cameras at 5 frames per second! This is a scale that enables your compute dollar or efficiency goals to extend even further in support of your machine learning initiatives.
4th Gen AMD EPYC™ CPUs + Neural Magic DeepSparse
300+ Cameras at 5 FPS
Get Started Today
At Neural Magic, we are on a mission to make applications anywhere intelligent with AI and are committed to bringing best-in-class machine learning performance together with the flexibility, scalability, and efficiency of CPUs - from Public to Private Cloud, to VMs or Containers, on Bare Metal, or at the edge. Collaborating with AMD helps us accelerate that mission.
To learn more about how Neural Magic could benefit your business, contact us and we will be in touch. You can get started today with seeing performance gains yourself in production environments by registering for a free 90-day Enterprise Trial of the DeepSparse Engine.
1Neural Magic measured results on AMD reference systems as of 9/29/2022. Configurations: 2P EPYC 9654 96 core “Titanite” vs. 2P EPYC 7763 64 core “DaytonaX” running on Ubuntu 22.04 LTS, Python 3.9.13, pip==22.12/deepsparse==1.0.2. BERT-Large Streaming Throughput items/sec (seq=384, batch 1, 48 streams, INT8 + sparse) using SQuAD v1.1 dataset; ResNet50 Batched Throughput items/sec (batch 256, single-stream, INT8 sparse) using ImageNet dataset; YOLOv5s Streaming Throughput ([image 3, 640, 640], batch 1, multi-stream, per-stream latency <=33ms) using COCO dataset. Testing not independently verified by AMD.







