
Mar 21, 2022

Author(s)


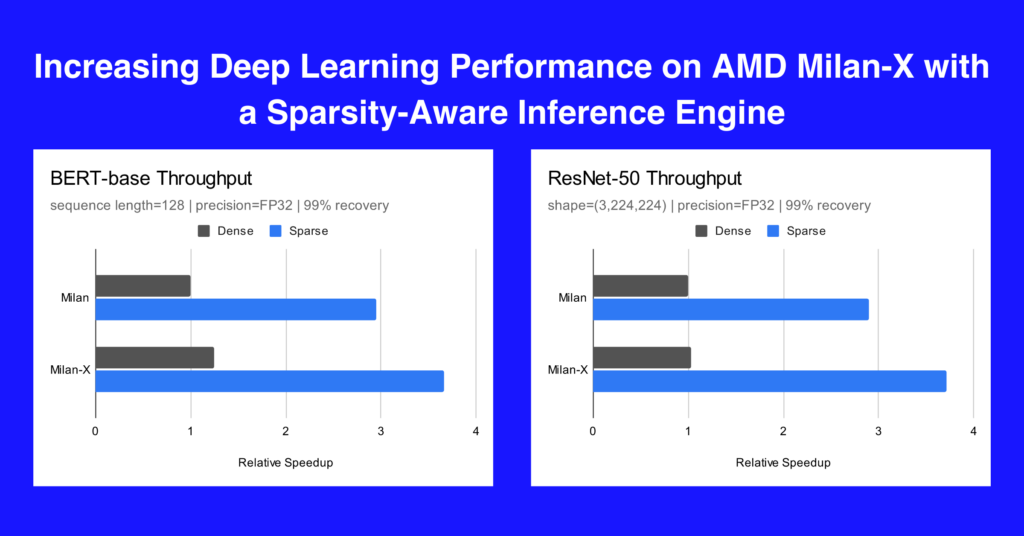
In alignment with AMD's latest launch, Neural Magic is pushing CPU-based neural network execution to new heights. Using only software and SOTA sparsification research, Neural Magic achieves a 3x relative speedup of inference performance for sparse BERT NLP and ResNet-50 image classification models, with a nearly 20-25% boost attributed to the L3 cache increase from Milan to Milan-X.
In this blog, we share how our techniques and our software, DeepSparse Engine and SparseML libraries, capitalize on AMD’s Milan-X architectural advancements to deliver additional speedups over Milan. We show a short demo video of a sparse sentiment analysis use case in action, and share how you can get started with delivering breakthrough inference performance on CPUs.


We chose to focus on floating-point precision as it allowed for the highest possible sparsities while maintaining the accuracy of the baseline model.
Benchmarking Hardware
We benchmarked on two virtual machines:
- Azure HBv3 with 120 cores of AMD EPYC Milan
- Azure HBv3 with 120 cores of AMD EPYC Milan-X
Since these instances are top-tier HPC platforms, we benchmarked a throughput-focused scenario of Milan and Milan-X serving BERT-base and ResNet-50 models with simultaneous concurrent inference requests. This allowed us to see how they perform under full CPU and memory utilization for modern datacenter-class ML workloads.
Sparse Performance on CPUs
Neural Magic improves performance through the following techniques:
- Maximizing network sparsity while preserving accuracy to reduce compute.
- Executing the network depth-wise in cache rather than the traditional layer-by-layer approach to increase bandwidth.
- Reusing data in registers, not just in cache, with operator fusion.
- Scheduling parallelism to match the topology of the system, keeping data local at all levels of the memory hierarchy.
Accuracy-preserving sparsification
Achieving performant sparse architectures on SOTA models for downstream tasks becomes simple when using replicable training recipes and sparse transfer learning in SparseML.
In multiple NLP use cases such as question answering, token classification (named entity recognition), and text classification (sentiment analysis), we were able to prune 90% of the parameters in BERT-base while maintaining 99% of the baseline model accuracy. For ResNet-50, we were able to prune 95% of the parameters while maintaining 99% of the baseline model accuracy on ImageNet.

Sparsification improves performance by eliminating the bottleneck on computation that plagues dense model inference on CPUs. By reducing the number of parameters, we reduce the FLOPs needed to carry out costly operations like convolutions and matrix multiplications. The resulting computation executes faster but leaves the processor idle while it waits for data transfer from memory, opening the door for further optimizations.
Depth-wise execution
After sparsification, sparse inference is constricted by memory bandwidth. To improve performance further, Neural Magic’s DeepSparse Engine maximizes cache utilization. Rather than the traditional layer-by-layer execution approach (Figure 1), our engine reduces data movement by running the network depth-wise in stripes that fit in cache (Figure 2).


Thus, larger sections of the network inference can stay entirely in thread-local and shared cache, increasing the effective memory bandwidth of the CPU and improving performance for sparsified networks.
Combining these techniques and software technologies allows for an execution engine that eliminates the compute disadvantage of CPUs and makes use of its well-known advantage: large fast caches.
Advantages of Milan-X
Milan-X offers caches of sizes unseen before and thus pushes the paradigm of lowered-compute in-cache execution of ML models to new levels.
Large caches significantly boost the performance of applications that require high memory bandwidth by increasing the hit rate of cache, making CPU execution more efficient by spending fewer cycles waiting for memory accesses to resolve.
Sparse Performance In Action
Get Started Today
By leveraging advances in processor architecture, Neural Magic’s inference performance on CPUs demonstrates our commitment to innovating at the speed of software to produce faster, smaller, and cost-efficient deployable models. To see the sparse performance for yourself, sign up or log in to our Deep Sparse Community Slack and check out the channel #benchmark-amd where we provide instructions and guidance on how you can see performance on AMD Milan-X in your own deployments. Bugs, feature requests, or additional questions can also be posted to our GitHub Issue Queue.
To benchmark and apply your data to sparse NLP and Compute Vision use cases with ease, use our end-to-end sparse use case tutorials.
Up Next
In the next few months, we will release a version of the DeepSparse Engine that further improves performance by running sparse-quantized models efficiently on Milan and Milan-X.
For a more technical deep-dive on Neural Magic's technology, register for the discussion happening on April 21, 2022 titled Using a Sparsity-Aware Inference Engine for Fast and Accurate Deep Learning on Milan-X.
Further Resources
- Try it Now Use Cases:
- Question Answering
- Token Classification
- Text Classification
- Image Classification
- Object Detection
- Learn more about Neural Magic's technology
- Milan-X Technical Specification







