

Dec 01, 2022

Author(s)


AWS Lambda is a serverless, event-driven environment for making quick auto-scalable deployments for various applications including machine learning. The most convenient feature of serverless environments is that server management is delegated to the AWS infrastructure, allowing the developer to focus on the deployment with minimum management. In addition, Lambda only incurs a cost in the frequency and duration of client-side requests, making it ideal for developers who prefer a persistent loaded model in a low-traffic request environment. To make these deployments faster and cheaper, sparse models can be a resourceful deployment strategy for machine learning developers.
In this blog, we’ll leverage how to deploy a sentiment analysis DeepSparse pipeline in an AWS Lambda function by using our SparseLambda object for generating an HTTP endpoint.
Building your own Lambda endpoint via Docker requires you to take the following steps:
- Building a local Docker image with the DeepSparse Server from a Dockerfile
- Creating an Amazon Elastic Container Registry (ECR) repository to host the image
- Pushing the image to the ECR repository
- Deploying an HTTP endpoint using the SparseLambda object for automating the Lambda deployment
We’ll be using the code from the AWS-Lambda example directory found in the DeepSparse GitHub repository.
Similar to our Sagemaker blog, we wrapped our workflow in a Python class called SparseLambda to automate the deployment process:
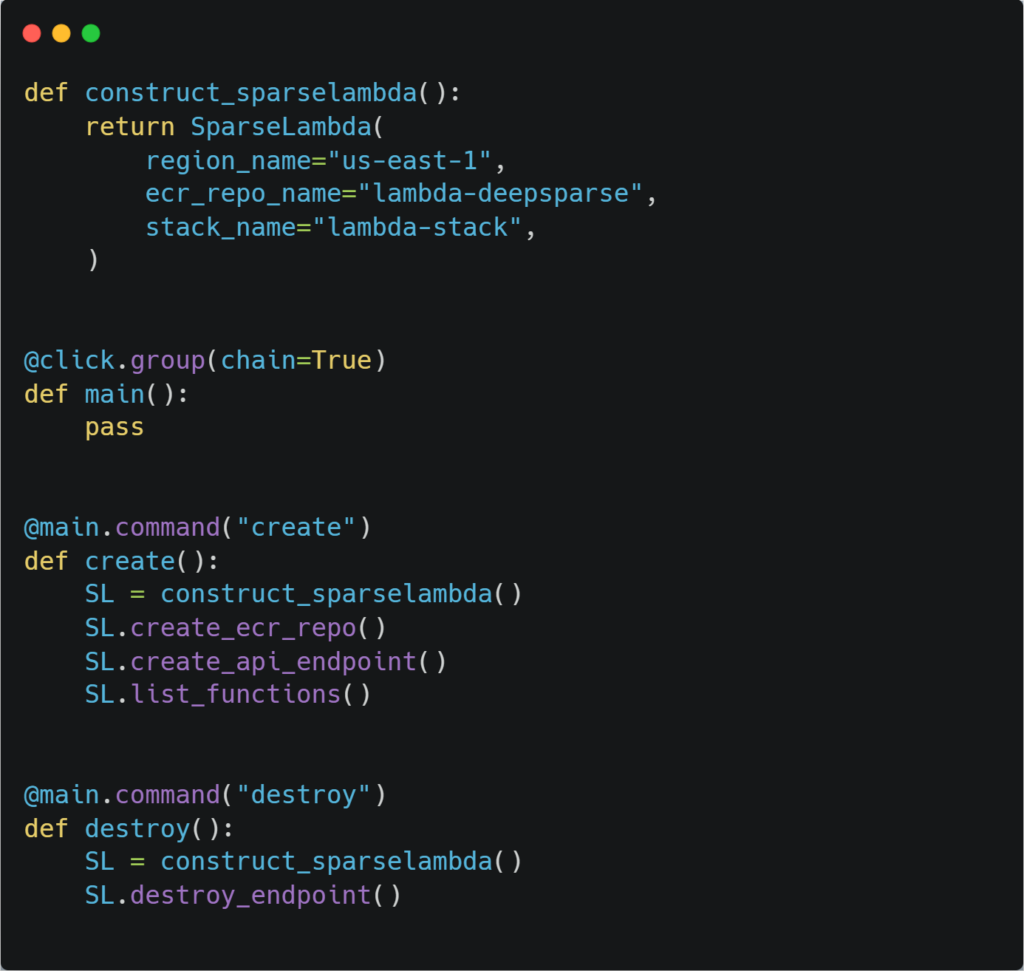
To execute this class and perform these steps, your local machine needs to have the following prerequisites installed:
- AWS Command Line Interface (CLI) version 2.x configured with: access key ID, secret access key, AWS region, and output format
- The Docker CLI available as part of the Docker installation.
- The AWS Serverless Application Model (AWS SAM), an open-source CLI framework used for building serverless applications on AWS
- Select AWS permissions: AmazonEC2ContainerRegistryFullAccess, AmazonAPIGatewayPushtoCloudWatchLogs, AmazonAPIGatewayAdministrator, AWSLambdaExecute, AWSLambdaBasicExecutionRole, AWSLambdaRole, AWSCloudFormationFullAccess, AWSLambda_FullAccess
Deployment Flow
For our example, we’ll use a sparse-quantized oBERT model fine-tuned on the SST-2 dataset for the sentiment analysis task (positive or negative). We’ll build a Lambda function with an HTTP endpoint using the AWS SAM CLI library. SAM executes our entire workflow by executing the appropriate IAM permissions, pushing the Docker image to ECR, and connecting your Lambda function to a secure HTTP endpoint on API Gateway. This entire stack is managed by the AWS Cloudformation service available on AWS.
The overall flow to deployment involves generating a Docker image and passing select files from the /app directory into the image, which includes the Lambda handler function found in the app.py file:
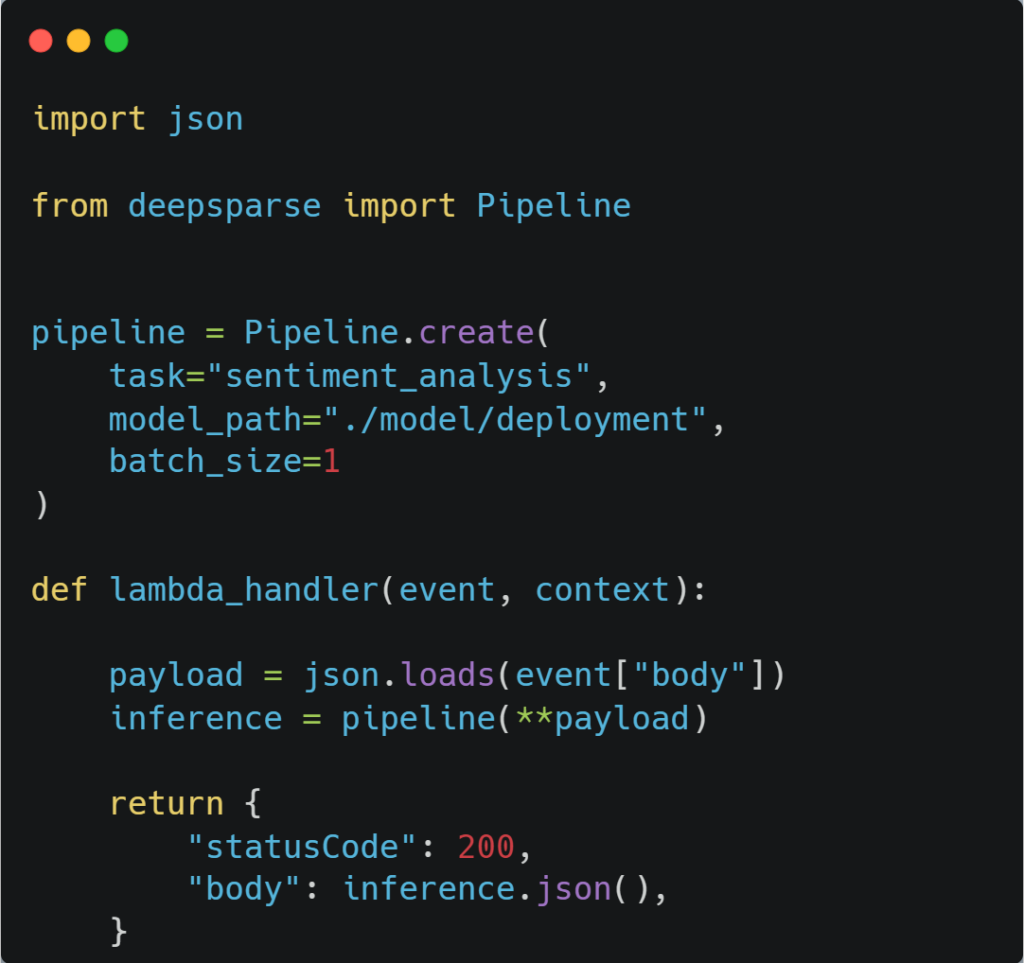
The configuration for the Lambda function is derived from the template.yaml file. This file instructs AWS SAM how to construct your function and has the ability to modify various parameters such as: timeout time, routes, docker management, memory allocation, and auto-scaling policies, etc. For exploring additional policies to add to this file, you can view the template get started page on AWS.
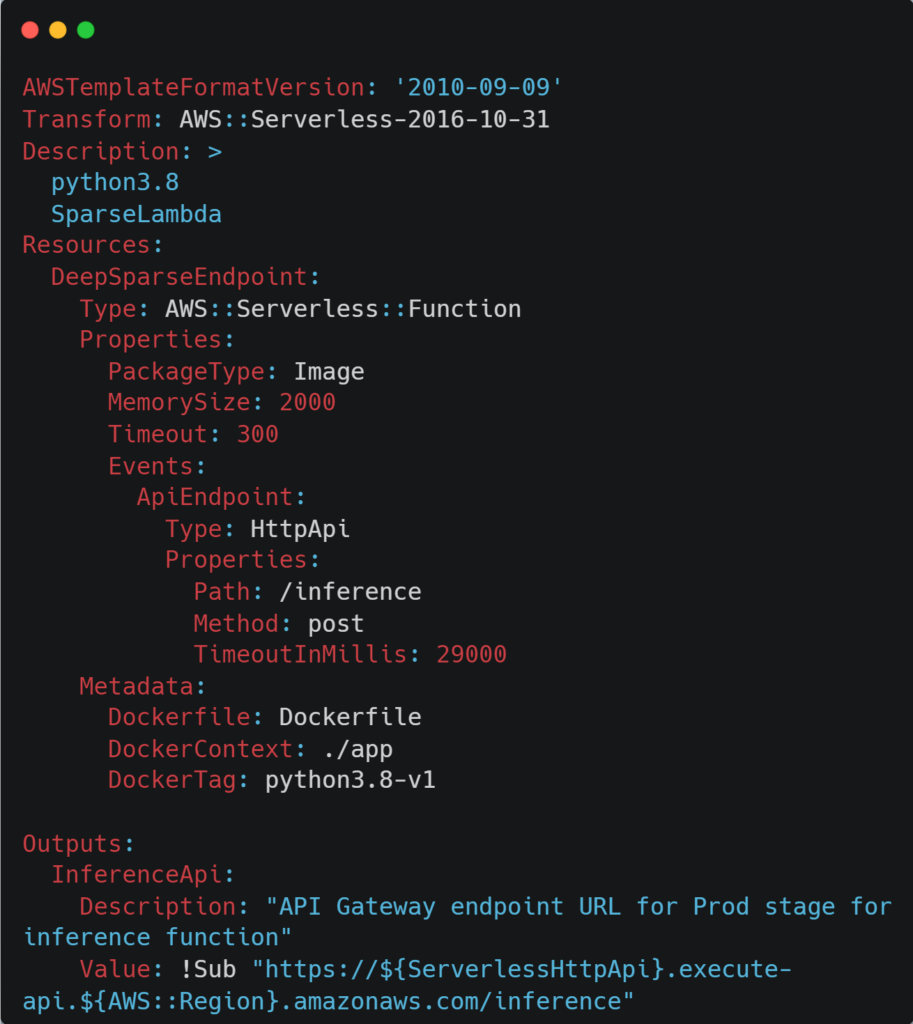
Deploy Endpoint and Start Inferencing
Getting an endpoint up and running in Lambda requires one to clone the DeepSparse repository, change into the aws-lambda example directory, and install boto3 and the click library via the requirements.txt file.
git clone https://github.com/neuralmagic/deepsparse.git
cd deepsparse/examples/aws-lambda
pip install -r requirements.txtAfter cloning the DeepSparse repo, run the following command in the terminal to initialize the SparseLambda object and create your endpoint. The following command will build a Docker image locally, create an ECR repo on AWS, push the image to ECR, and then build the HTTP endpoint via AWS SAM CLI:
python endpoint.py createThat’s it! After the endpoint has been staged (takes ~5 minutes), paste your API Gateway URL (can be found in your terminal output after creating the endpoint) in the LambdaClient object. You can now run an inference with the following snippet on your local machine:
from client import LambdaClient
LC = LambdaClient("https://#########.execute-api.us-east-1.amazonaws.com/inference")
answer = LC.client({"sequences": "i like pizza"})
print(answer)
answer: {'labels': ['positive'], 'scores': [0.9990884065628052]}On your first cold start, it will take ~60 seconds to get your first inference, but afterwards, it should be in milliseconds.
If you want to delete your Lambda endpoint, run:
python endpoint.py destroyOptimization: Avoiding Cold Starts
Executing a cold function can take up valuable time (~60 seconds as mentioned above), however to mitigate this issue, one can set up provisioned concurrency allowing your function to be kept persistently warm. To set up provisioned concurrency, we need to create a new version of our function.
Pass the Lambda function name into the following CLI command:
aws lambda publish-version --function-name <function name>Tip: To find your function name, look at the print out after creating your endpoint which will display a list of all your Lambda functions running in your AWS account. Look for a function starting with the name lambda-stack-deepsparse-..., this is the function we just generated.
After the new function version is published, pass the function name and the version number (which was printed out in a JSON object after executing the previous command) to the provisioned concurrency config command:
aws lambda put-provisioned-concurrency-config --function-name <function name> --qualifier
<version number> --provisioned-concurrent-executions 2After a few minutes, 2 provisioned concurrent executions will be staged although you can modify this argument to the number that best suits your deployment. Keep in mind that provisioned concurrency is an extra cost on AWS.
The last step is to create a new API Gateway trigger inside the new function version we just created. Follow along with this video to see how it’s done on the AWS console:
At the end of the video, a new API URL endpoint for provisioned concurrency was generated! You can pass this new URL into the LambdaClient object as we showed above. You will notice that inference is instantaneous, and our cold start problem has been solved.
Conclusion
In conclusion, we introduced a seamless application to auto-deploy a sparse transformer model for sentiment analysis on AWS Lambda. This approach is able to automate the creation of a Docker image, ECR repo and an HTTP endpoint in a Lambda function. In addition, we showed how we can optimize for provisioned concurrency to avoid the cold start problem in serverless environments.
For more on Neural Magic’s open-source codebase, view the GitHub repositories, DeepSparse and SparseML. For Neural Magic Support, sign up or log in to get help with your questions in our community Slack. Bugs, feature requests, or additional questions can also be posted to our GitHub Issue Queue.







