

Jun 16, 2022

Author(s)


You can now automate the deployment of a sparse transformer model with an Amazon SageMaker endpoint. At Neural Magic, we have simplified the arduous task of infrastructure build (often requiring several steps to complete) by distilling it down to a single CLI command. This post describes the ease of building your personal SageMaker inference endpoint from a local Docker image and then the ability to achieve over 7x increase in performance! Details about this deployment can be found in the Amazon SageMaker example in the DeepSparse repository on GitHub.
Building your own SageMaker endpoint via Docker requires you to take the following steps:
- Building a local Docker image with the DeepSparse Server from a Dockerfile.
- Creating an Amazon Elastic Container Registry (ECR) repository to host the image.
- Pushing the image to the ECR repository.
- Creating a SageMaker model that reads from the hosted ECR image.
- Building a SageMaker endpoint configuration that defines how to provision the model deployment.
- Launching the SageMaker endpoint.
Normally, you would have to do this manually but the good news is we wrapped this workflow in a Python class called SparseMaker. Check out how to initialize it:
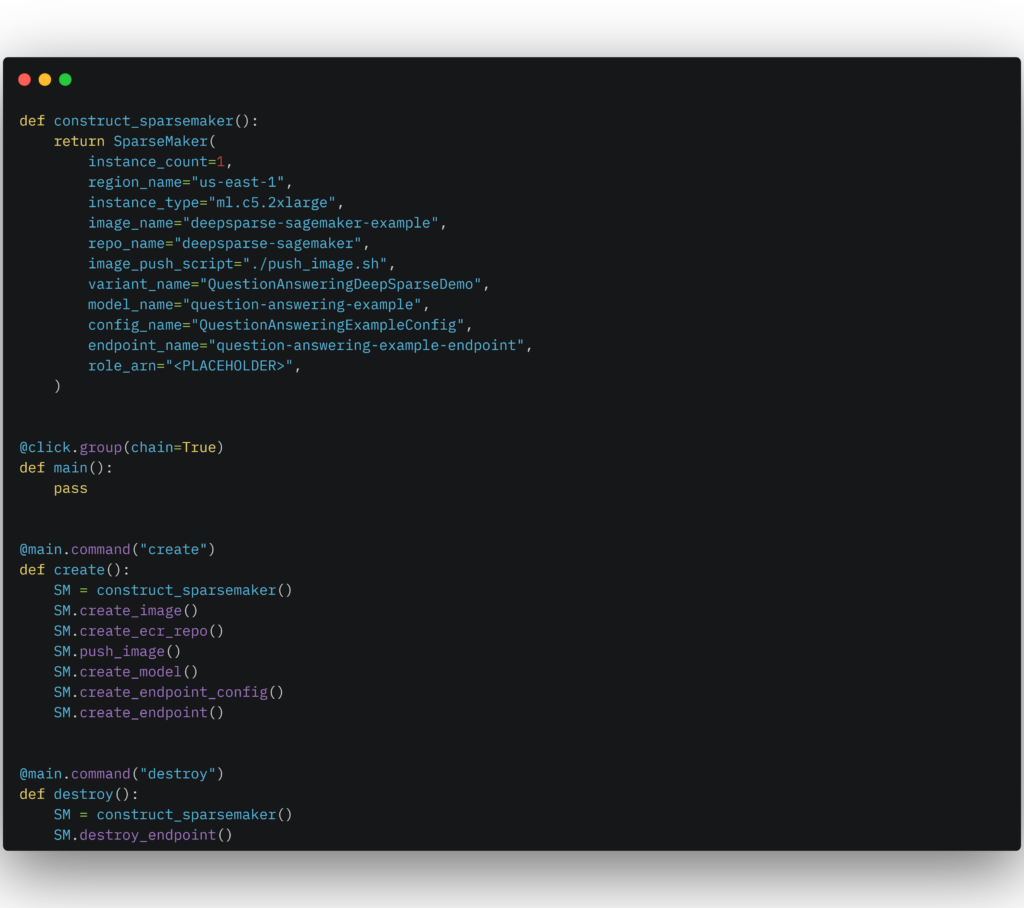
Tip: Find this class and example usage in the endpoint.py file in the SageMaker example. Optionally, customize your AWS SageMaker deployment by naming the number of instances, region name, instance type and the labels for your endpoint configuration.
To execute this class and perform these steps, your local machine needs to have the following prerequisites installed:
- AWS Command Line Interface (CLI) version 2.x configured with: access key ID, secret access key, AWS region, and output format.
- The Docker CLI available as part of the Docker installation.
- Amazon Resource Name (ARN) id with full SageMaker and ECR permissions. It should take the following form: arn:aws:iam::XXX:role/service-role/XXX .
The Flow
For our example, we’ll use a sparse-quantized DistilBERT model fine-tuned on the SQuAD dataset for a question answering task. We’ll build a SageMaker endpoint using an ml.c5.2xlarge instance on AWS. This instance holds 8 vCPUs, 16GB of RAM, and costs $0.408 per/hour as of June 2022.
Quick Start
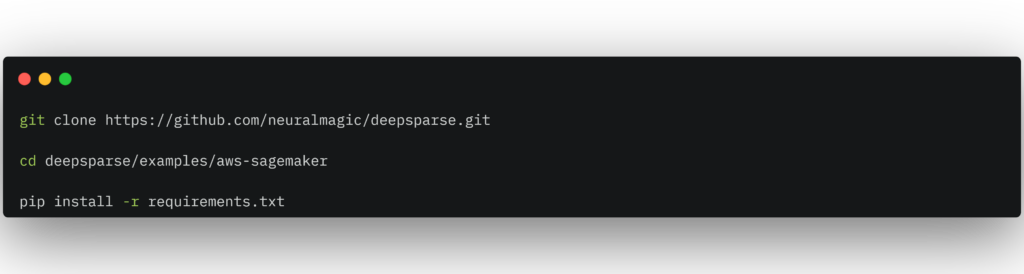
Getting your endpoint up and running in SageMaker requires you to clone the DeepSparse repository, change into the aws-sagemaker example directory, and install boto3 and the rich library via the requirements.txt file.
Don’t forget to add your own ARN id to the `role_arn` parameter of the SparseMaker class.
Your ARN id should have the permissions for you to interact with SageMaker and the ECR where your Docker image resides after being pushed from your local machine.
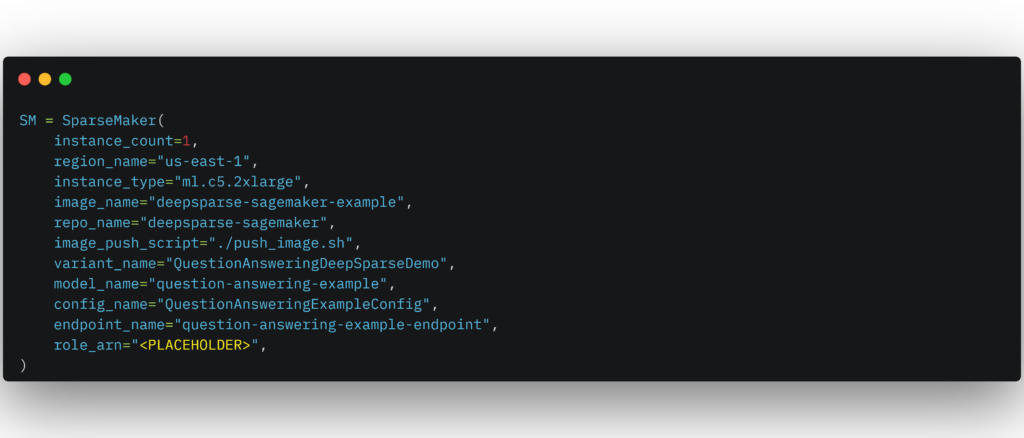
After adding your ARN, run the following command in the terminal to initialize the SparseMaker object and create your endpoint. The following command will create a Docker image locally, make an ECR repo on AWS, push the image to ECR, and then build the SageMaker endpoint:

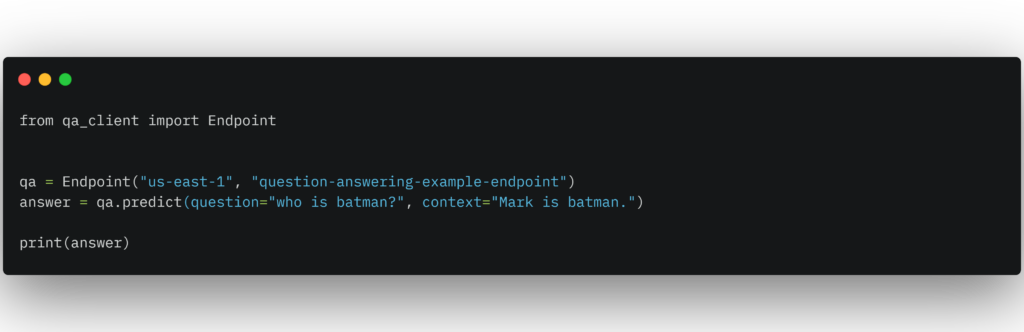
That’s it! After the endpoint has been staged (takes ~1 minute), you can now run inference with the following snippet on your local machine:
Once you're finished, if you want to delete your endpoint run the following command:

Performance
Let’s compare our sparse DistilBERT and DeepSparse Server against the Hugging Face SageMaker pipeline with one of the most widely downloaded DistilBERT models on the Hugging Face hub for the question answering task.
Our sparse model is the result of pruning the DistilBERT model to 80% using a 4-block sparsity pattern on the weights (semi-structured), followed by fine-tuning and quantization on the SQuAD dataset. It achieves 86.3 F1 score on the validation dataset, recovering over 99% of the F1 score of the HF model.
Next, we’ll compare the performance of both models on SageMaker with an ml.c5.2xlarge instance and sequence length of 384.
Results
AWS CloudWatch reveals the lightning speed of our sparse models under full load.
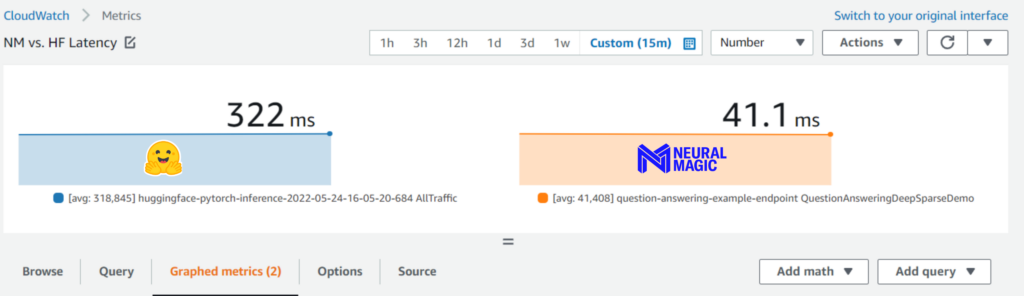
You can see the improvement of over 7x, taking the latency from 322ms to 41ms, using Neural Magic’s pipeline as demonstrated with a bonus: the improved performance allows users to leverage cheaper instances to save cost-per-inference in the cloud. We have pre-optimized models for a wide variety of tasks hosted on the SparseZoo that are ready to be tuned and deployed for your use case.
???
For more on Neural Magic’s open-source codebase, view the GitHub repositories, DeepSparse and SparseML. For Neural Magic Support, sign up or log in to get help with your questions in our Deep Sparse Community Slack. Bugs, feature requests, or additional questions can also be posted to our GitHub Issue Queue.







