
Aug 23, 2021

Author(s)


Pruning Hugging Face BERT: Apply both pruning and layer dropping sparsification methods to increase BERT performance anywhere from 3.3x to 14x on CPUs depending on accuracy constraints
In this post, we go into detail on pruning Hugging Face BERT and describe how sparsification combined with the DeepSparse Engine improves BERT model performance on CPUs. We’ll show:
- A current state of pruning BERT models for better inference performance;
- How compound sparsification enables faster and smaller models;
- How to leverage Neural Magic recipes and open-source tools to create faster and smaller BERT models on your own pipelines;
- Short-term roadmap for even more performant BERT models.
Over the past six months, we have released support for ResNet-50, YOLOv3, and YOLOv5, showing between 6x and 10x better performance compared to other CPU implementations. Today, we are releasing our initial research on BERT, to be followed by further BERT support (including INT8 quantization combined with pruning) and other popular models in the coming weeks.
Pruning Hugging Face BERT for Better Inference Performance
Nearly three years ago, Google researchers released the original BERT paper, establishing transfer learning from Transformer models as the preferred method for many natural language tasks. By pre-training the model on a large text corpus, researchers created a model that understood general language concepts. The model was then fine tuned onto other, downstream datasets such as SQuAD giving new, state-of-the-art results. Today, researchers and industry alike can achieve breakthrough results by applying the same principles on their own private datasets with less iteration and limited training.
General understanding of language is a complex task leading to a relatively large BERT model. Furthermore, the recurrent neural networks (RNNs) traditionally used for the downstream tasks, while not as accurate, are smaller and faster to deploy, limiting BERT’s adoption for performance or cost-sensitive use cases. Given this, many researchers and companies have begun optimizing BERT for smaller deployments and faster inference via techniques such as unstructured pruning. Hugging Face, for example, released PruneBERT, showing that BERT could be adaptively pruned while fine-tuning on downstream datasets. They were able to remove up to 97% of the weights in the network while recovering to within 93% of the original, dense model’s accuracy on SQuAD.
The results for PruneBERT are impressive—removing 97% of the weights while maintaining a functional model is no small feat. Not only does this create a smaller model to deploy, but also a faster one. Neural Magic’s DeepSparse Engine is specifically engineered to speedup sparse networks on general CPUs. For example, benchmarking the PruneBERT and dense models in DeepSparse and ONNX Runtime for a throughput use case (batch size 32, sequence length 128) on a 24-core server results in the following:
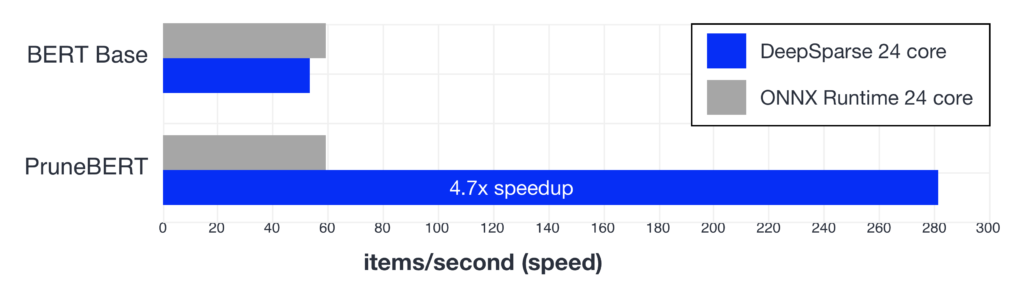
Note that PruneBERT’s inference time in ONNX Runtime is the same as dense while the DeepSparse Engine gives a 4.7x increase. This is possible because DeepSparse is designed to leverage the CPU architecture’s flexibility to skip calculations for the zeroed weights in a sparse model through proprietary algorithms and techniques.
Pruning Hugging Face BERT: Better Performance with Compound Sparsification
The Hugging Face paper additionally highlighted a key aspect for pruning: knowledge distillation boosts the final accuracy while pruning. Distillation attempts to match the current model's outputs to another pre-trained teacher model by editing the loss function. For pruned models, we distill from the dense, base model while pruning to ideally create a more accurate, sparse model. It works well for many use cases within NLP. To give an example, the 97% PruneBERT model’s F1 score on SQuAD improved from 79.9 to 82.3 after distillation (the dense baseline is 88.1).
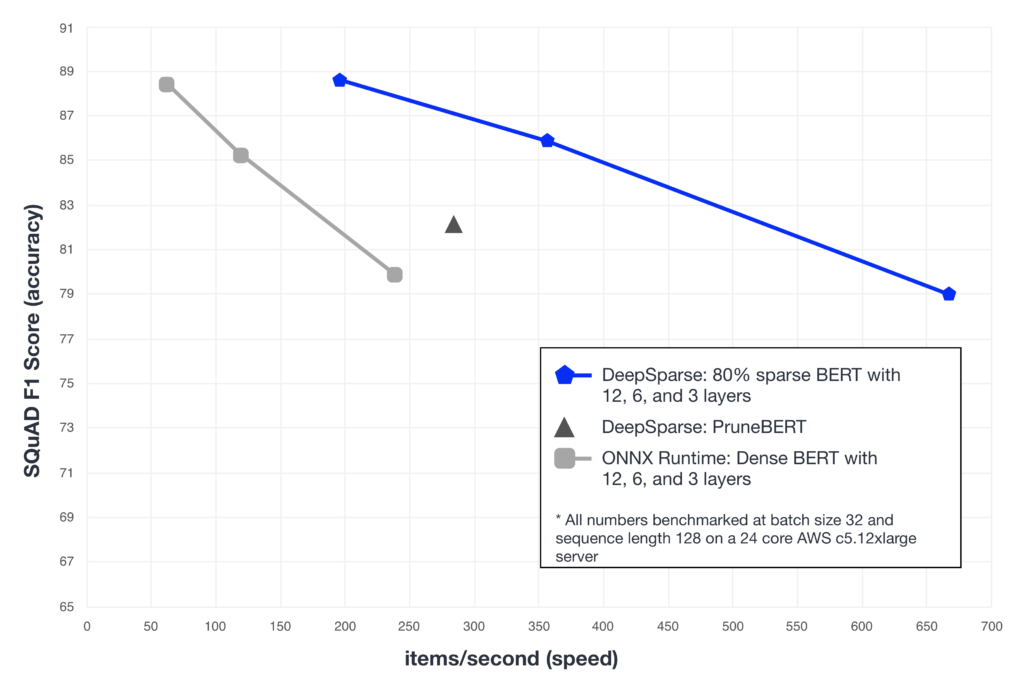
Distillation has more commonly been used with layer dropping as in the DistilBERT paper. Layer dropping for BERT removes whole encoder layers to create a smaller, faster model. From the original 12-layer model, the most common iterations create compressed 6-layer (DistilBERT) or 3-layer versions. In this setup, we can distill using BERT as a teacher into a smaller package while retaining most of the knowledge. This enables engines to run inferences faster, generally scaling linearly: a 6-layer model runs twice as fast and a 3-layer runs four times faster. Figure 3 illustrates this point by showing the linear scaling of performance for dense, layer dropped models. In addition, the benefits of PruneBERT become clearer, giving better inference performance than even the 3-layer model while maintaining better accuracy.
A natural question arises, though, of what happens if we combine distillation with both unstructured pruning and the structured layer dropping? This combination of multiple sparsification techniques is what we have termed compound sparsification. Just as with compound scaling for neural networks, the combination enables smaller, faster, and more accurate models for deployment.
We combined gradual magnitude pruning (GMP), layer dropping, and distillation to create faster and more accurate sparse versions of BERT. GMP was used instead of movement pruning (PruneBERT) from Hugging Face because we found extending the pruning times enabled better recovery with GMP as compared to the paper. The full results are given in the graph below.
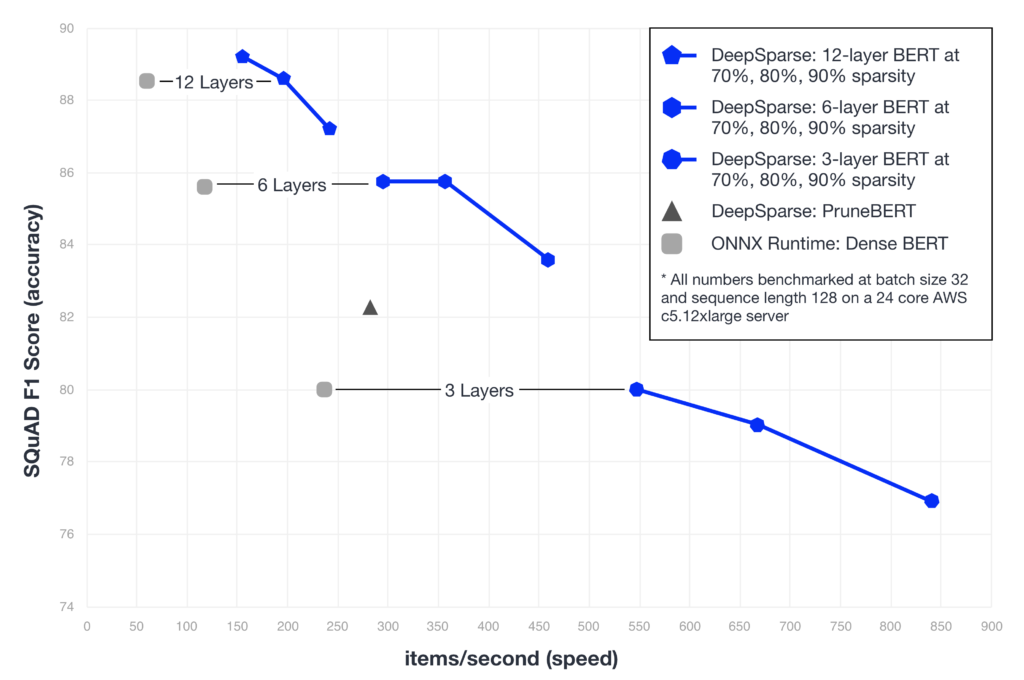
A few notable results from the graph:
- The 12-layer, 90% sparse BERT gives 4.05x speedup, beating out the 3-layer, dense BERT at a much higher accuracy.
- The 6-layer, 90% sparse BERT gives 7.71x speedup beating out PruneBERT for both speed and accuracy.
- The 3-layer, 70% sparse BERT matches the 3-layer dense BERT for accuracy while giving 9.20x absolute speedup (2.32x faster than 3-layer, dense BERT).
Pruning Hugging Face BERT: Making it Easier with Recipes and Open Source
Research findings and methods like PruneBERT and compound sparsification help push the envelope forward for what is possible in deep learning. Generally, though, they can be hard to adapt to industry needs involving a lot of engineering, experimentation, and training time. To remedy this, Neural Magic has focused on a recipe-driven, open-source approach. Recipes encode the hyperparameters for sparsification which, when combined with the SparseML open-source code, enable users to sparsify models in their own pipelines with only a few lines of code.
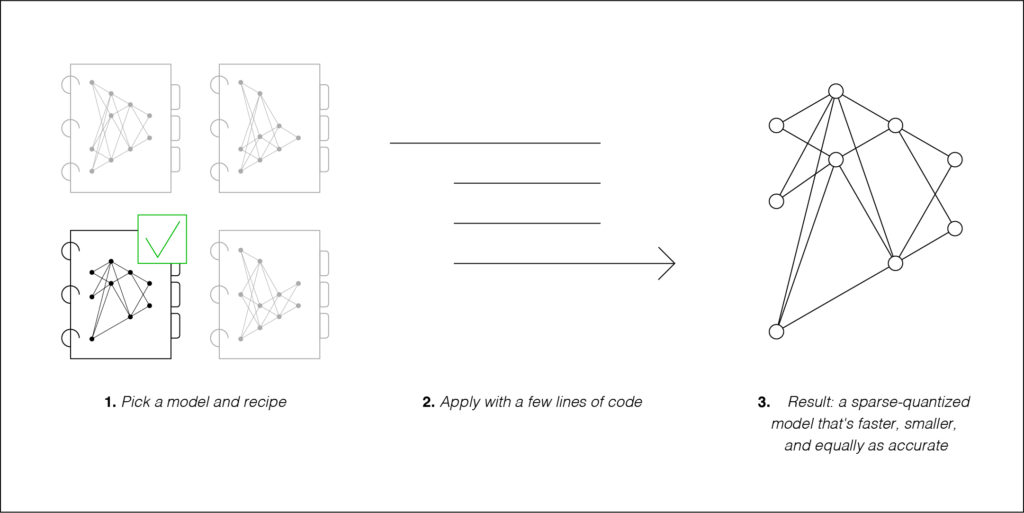
The open-source nature of SparseML allows anyone to edit and integrate to fit their needs. Not only this, but it enables you to integrate with other open-source code containing popular training flows such as Hugging Face’s Transformers library. Leveraging both of these patterns, we’ve created a training integration with Transformers, example recipes for pruning BERT, a tutorial to show how to apply these recipes, and benchmarking examples for DeepSparse. Try them out and let us know if you have any questions, ideas, or feedback!
What’s Next
Currently, the DeepSparse Engine combined with SparseML’s recipe-driven approach enables inference performance improvements anywhere from 2x-5x for throughput on BERT as compared to other CPU inference engines at FP32. A downside of sparsifying BERT on downstream tasks is that it does extend the training time and complexity when compared with the fine-tuning processes laid out in the BERT paper. This is something we are actively working on through sparse transfer learning. If the downstream sparsification process is currently too long or complicated, we will discover sparse architectures within BERT that are fine tuned as well as the dense weights.
These compound sparsification results focus entirely on FP32 improvements. The inclusion of INT8 quantization into the compound sparsification step is next on our roadmap through quantization-aware training, recipes, and performance engineering in the DeepSparse Engine. Quantization will enable even faster performance on CPUs.
Finally, the BERT model is surprisingly memory bound—most of the time is spent in transferring data between operations rather than on computation for those operators. Neural Magic will continue innovating around algorithms that use the unique cache architectures on CPUs to speed up BERT even further. These advancements combined with compound sparsification will enable CPU deployments previously not possible. Join our Slack or Discourse communities, star our GitHub repository or subscribe to our quarterly ML performance newsletter here to stay current.







