
Feb 21, 2023

Author(s)


Simplify Pre-processing Pipelines with Sequence Bucketing to Decrease Memory Utilization and Inference Time For Efficient ML
DeepSparse is an inference runtime offering GPU-class performance on CPUs and APIs to integrate ML into your application. DeepSparse has built-in performance features, like sequence bucketing, to lower latency and increase the throughput of deep learning pipelines. These features include
- Bucketing sequences of different sizes to increase inference speed
- Dynamic batch size for maximum resource utilization
- Hosting multiple models on the same engine for optimal work sharing of the CPU
In this series of articles, you will learn about these features and how to use them when deploying deep learning models. This first installment will focus on the power of bucketing sequences.
When working with natural language processing (NLP) models, the input size can vary greatly. One example is customer reviews that come in different lengths. However, NLP models expect the input passed to them to be of a specific size. To accommodate this, a maximum length for the input is chosen, and any tokens exceeding this length are truncated, while shorter sequences are padded to reach the maximum length. For example, if the maximum length is set to 512, a sentence with 20 tokens would be padded to 512 tokens. This can lead to inefficiency in real-world applications where cost is a concern, as padding short sentences to 512 tokens can increase memory utilization. What is the solution? Bucketing.
Bucketing is a technique for placing sequences of varying lengths in different buckets. It reduces the amount of padding and hence makes training and inference more efficient. Popular deep learning frameworks provide tools that enable you to implement bucketing during training and inference. However, that introduces a new piece of code that you need to maintain. This is where DeepSparse shines.
DeepSparse provides built-in support for bucketing, enabling you to deploy NLP models without introducing more code to your pipeline. With the power of bucketing, DeepSparse sends every input to the most appropriate pipeline. In this article, you will learn how to deploy NLP models efficiently by taking advantage of bucketing. DeepSparse handles bucketing natively to reduce the time you would otherwise spend building this preprocessing pipeline. You will also see a performance comparison between a model deployed using bucketing and one without. You will learn that using bucketing reduces the time of inference by half.
Let’s dive in.
The Power of Sequence Bucketing
Bucketing creates different models for the provided input sizes. Let's say you have input data whose length ranges from 157 to 4063, with 700 being the median. Assuming you are using a model like BERT, whose maximum token length is 512, you can use these input shapes [256, 320, 384, 448, 512]. This means that all tokens shorter than 256 will be padded to 256, while any tokens longer than 512 will be truncated to 512. Tokens longer than 256 will be padded to 320, and so on.
At inference, each input is sent to the corresponding bucketed model. In this case, you’d have 5 models because you have defined 5 buckets. Bucketing reduces the amount of compute because you are no longer padding all the sequences to the maximum length in the dataset. You can decide on the bucket sizes by examining the distribution of the dataset and experimenting with different sizes. The best choice is the one that covers all the inputs in the range of the dataset.
Benchmarking DeepSparse With and Without Sequence Bucketing
DeepSparse makes it easy to set up bucketing. You only pass the size, and DeepSparse will automatically set up the buckets. You can determine the optimal size of the buckets by analyzing the lengths of the input data and selecting buckets where most of the data lie.
Let’s illustrate this using the Stanford Question Answering Dataset (SQuAD) dataset. While at it, we’ll compare the inference time between the pipeline with buckets and the one without.
Before we start benchmarking, let’s look at a histogram of the context length to illustrate the variability in the length of the sentences.
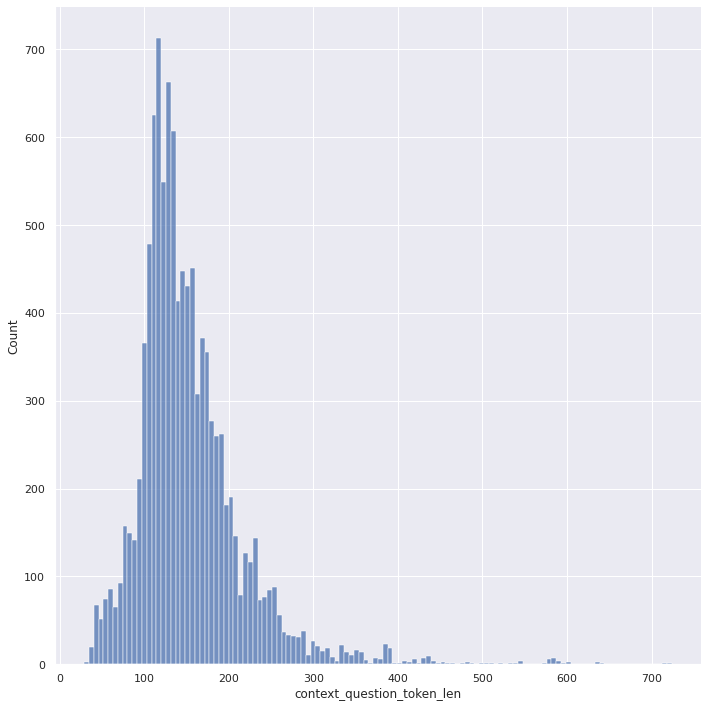
As you can see from the above histogram:
- The maximum length of the sequences is above 724
- The minimum length is 29
- Most of the data is in the 100-250 bucket length
With that information, let’s use DeepSparse to benchmark inference with and without bucketing.
The first step is to install DeepSparse.
pip install deepsparseNext, load the SQuAD validation set.
from datasets import load_dataset
squad_dataset = load_dataset("squad", split="validation")Run inference on the dataset without bucketing.
from deepsparse import Pipeline
qa_pipeline = Pipeline.create(
task="question-answering",
sequence_length = 512,
model_path='zoo:nlp/question_answering/bert-base/pytorch/huggingface/squad/pruned95_obs_quant-none'
)
def run_inference(data):
inferences = []
for item in data:
inference = qa_pipeline(question=item['question'], context=item['context'])
inferences.append(inference)
return inferences
%%time
inferences = run_inference(squad_dataset)
# Wall time: 4min 39sInferencing takes 4min 39s.
Repeat the process but now while applying buckets.
from deepsparse import Pipeline
qa_pipeline = Pipeline.create(
task="question-answering",
sequence_length=[128, 256, 320, 384, 448, 512],
model_path='zoo:nlp/question_answering/bert-base/pytorch/huggingface/squad/pruned95_obs_quant-none'
)
%%time
inferences = run_inference(squad_dataset)
# Wall time: 2min 50sThis time inference takes 2min 50s. That is almost 2 times faster than the pipeline without bucketing.
Final Thoughts
Bucketing is a crucial technique for deploying natural language processing models for real-world inference. Inference time is faster when you introduce bucketing to your inference pipeline. By appreciating the power of bucketing, you'll implement faster pipelines during inference.
While bucketing improves model performance during inference, this performance can be further improved by quantizing and reducing the model size. Sparsifying and quantizing the model makes it more performant without affecting its accuracy. Tools such as SparseZoo make it simple to find and use sparsified models.
To start deploying sparse natural language processing models, head over to SparseZoo, choose a state-of-the-art model, and deploy it with DeepSparse while taking advantage of bucketing.







