
Oct 05, 2022

Author(s)


If you have a text classification task at hand, exploring the zero-shot learning approach is a no-brainer. Zero-shot enables you to classify text without the need for model retraining, making it easier and faster to get started. However, zero-shot is very compute-intensive given it needs to infer each candidate label. Enter sparsity to save the day. Sparsity makes zero-shot faster and less compute-intensive, all while retaining classification accuracy.
We are excited to introduce a zero-shot learning feature to our sparsity-aware engine, DeepSparse, to help developers classify text faster at lower costs using commodity CPUs.
Getting Started with Sparse Zero-Shot LearningText Pipeline
This blog post will cover Neural Magic’s new zero-shot pipeline, explore the pipeline’s features, and then test its performance by sampling the SNIPS dataset.
The SNIPS dataset is a common dataset used for intent classification by voice assistants in natural language understanding (NLU). We chose this dataset to highlight the power of zero-shot inference because of its ability to generalize to novel unseen intents, which is a common occurrence in task-driven dialogue systems.
Why Zero-Shot Learning?
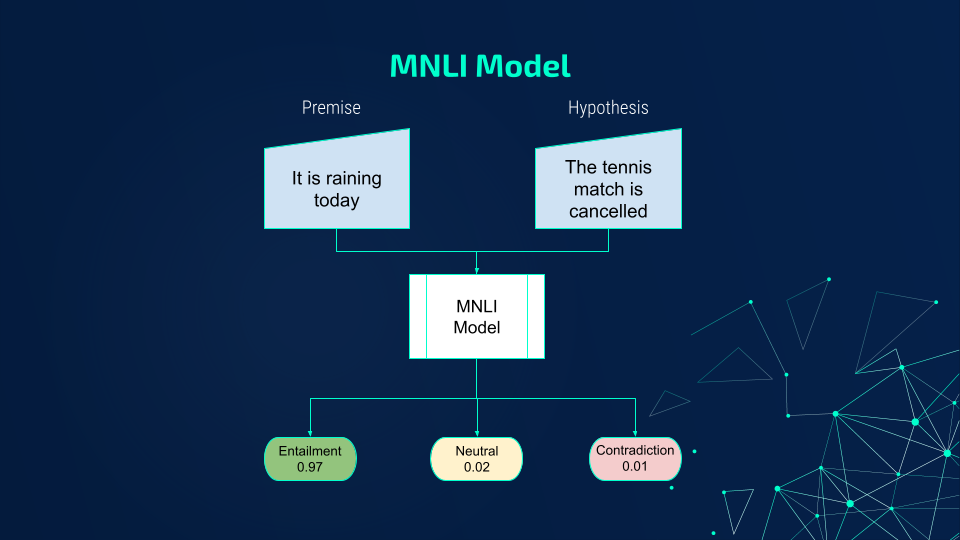
Zero-shot text classification allows one to classify text without retraining a model to your new dataset. This is done by taking the text and labels you want to predict and packaging them up to work as sequence pairs for an NLI classification. The model is then able to assign a score of whether the premise (the text you want to classify) entails the hypothesis (the candidate labels).

Given the input “I like pepperoni pizza,” you would expect a model to choose “food” as the true hypothesis and “movies” and “sports” as contradictions or false.

Given that zero-shot learning requires the transformer model to infer for each label space and choose the most relevant label (read: slow), sparsification is a good technique that delivers much-improved performance.
Neural Magic’s zero-shot pipeline aims to speedup the zero-shot approach allowing any user to accelerate their data labeling operations, vector search databases, or routine classification tasks such as sentiment analysis, topic detection, or intent detection using our sparse transformer models.
Understanding the Zero-Shot Learning Pipeline
The zero-shot learning pipeline utilizes a sparse transformer trained on the MNLI dataset, a crowd-sourced collection of 433k sentence pairs annotated with textual entailment information.
The pipeline can be executed in either of the two states:
- Static: Batch size and static labels are provided at compile time. At inference time, the number of sequences provided must be equal to the batch size divided by the number of static labels.
- Dynamic: Any number of labels or sequences can be provided at inference time. This mode runs inference sequentially rather than in parallel batches.
To quickly get started with the pipeline and model downloads, first install DeepSparse:
pip install deepsparseOnce installed, download your sparse MNLI model from the SparseZoo and pass its Zoo stub into the pipeline object. The following example shows how you can execute the pipeline with dynamic labels.
from deepsparse import Pipeline
zeroshot_pipeline = Pipeline.create(
task="zero_shot_text_classification",
batch_size=1,
model_scheme="mnli",
model_config={"hypothesis_template": "This text is related to {}"},
model_path="zoo:nlp/text_classification/distilbert-none/pytorch/huggingface/mnli/pruned80_quant-none-vnni",
)
sequence = "I like pepperoni pizza."
labels = ["food", "movies", "sports"]
inference = zeroshot_pipeline(sequences=sequence, labels=labels)
print(inference)The pipeline offers several arguments for configuring your inference:
- task: zero_shot_text_classification.
- batch_size: In static mode, this is the number of sequences times the number of candidate labels. In dynamic mode, batch_size should be 1.
- model_scheme: The method to use for text classification. For this example, we’ll use MNLI models.
- model_config: Allows the user to formulate the logic of the hypothesis template. For example, we can set the template as “this text is related to {}” or “this text is not related to {}”. In addition, you can set “multi_class” to “True” or “False”. This argument specifies if the labels are independent (a text can be both about politics and sports, but the same cannot be said of positive and negative). In other words, if set to “False”, the confidence of each label will add up to 1.0.
- model_path: The path to the MNLI model we want to use.
PRO-TIP: If you have multiple sequences to label, you can pass the sequences as a list.
Try Out Sparse Zero-Shot Pipeline on the SNIPS Dataset
The SNIPS dataset is commonly used for intent classification for voice assistant user commands. SNIPS contains 328 utterances with 10 intent classes.
Example labels:
| ComparePlaces | RequestRide |
| GetWeather | SearchPlace |
| GetPlaceDetails | ShareCurrentLocation |
| GetTrafficInformation | BookRestaurant |
| GetDirections | ShareETA |
For our demonstration, we’ll be looking at two classes, the “RequestRide” and “GetWeather”.
Below are select examples from each class:
| RequestRide Commands | GetWeather Commands |
| I need a taxi to catch my flight tomorrow morning | What's the weather like in Paris, New York, and Chicago? |
| Book a cab | Is it cold outside? |
| Book a Lyft car to go to 33 Greene Street | What will the weather be like from 8 AM to 2 PM in Central Park? |
| I need a taxi in 5 minutes at 36 5th Avenue | Is it raining right now? |
For a further deep dive into the dataset, see here.
To show the power of the sparse zero-shot learning, let’s run the zero-shot pipeline using oBERT, specifically our 80% Pruned Quantized oBERT base uncased model from the SparseZoo.
Our model will be asked to classify whether a sequence is either a “RequestRide” or “GetWeather” command. We’ll also add the “BookRestaurant” label as a way to test our model’s ability to deal with noise to see how it reacts with an unrelated label as an option.
The code below will:
- Extract the select text input from SNIPS
- Load a sparse-quantized DistilBERT model
- Execute the zero-shot pipeline
pip install deepsparse datasetsdef get_sequences():
"""Extracts sequences for ‘RequestRide’ and ‘GetWeather’ commands from SNIPS dataset"""
request_ride_seqs = [doc["text"] for doc in dataset if doc["label"] == 1]
get_weather_seqs = [doc["text"] for doc in dataset if doc["label"] == 2]
return request_ride_seqs, get_weather_seqs
def format_output(outputs):
"""Helper function for getting each sequence as its own dict"""
sequences = outputs.sequences
labels = outputs.labels
scores = outputs.scores
return [
{
"text": sequence,
"labels": {label: score for label, score in zip(labels, scores)}
}
for sequence, labels, scores in zip(sequences, labels, scores)
]
def call_pipeline():
labels = ["get a ride", "check the weather", "book a restaurant"]
pipeline = Pipeline.create(
task="zero_shot_text_classification",
batch_size=1,
model_scheme="mnli",
model_config={"hypothesis_template": "This text is related to {}", "multi_class":True},
model_path="zoo:nlp/text_classification/obert-base/pytorch/huggingface/mnli/pruned80_quant-none-vnni"
)
sequences = get_sequences()
times = []
for sequence in sequences:
start = perf_counter()
inference = pipeline(sequences=sequence, labels=labels)
end = perf_counter()
times.append(end - start)
inference = format_output(inference)
for seq in inference:
print(seq["text"], next(iter((seq["labels"].items()))))
print(f"\n{len(sequences)} sets of sequences took {sum(times):2f} secs.\n")
if __name__ == "__main__":
call_pipeline()After the output is returned, we can see that the recall for the “RequestRide” label is 92%, for 24/26 sequences. The image below shows a few output samples.
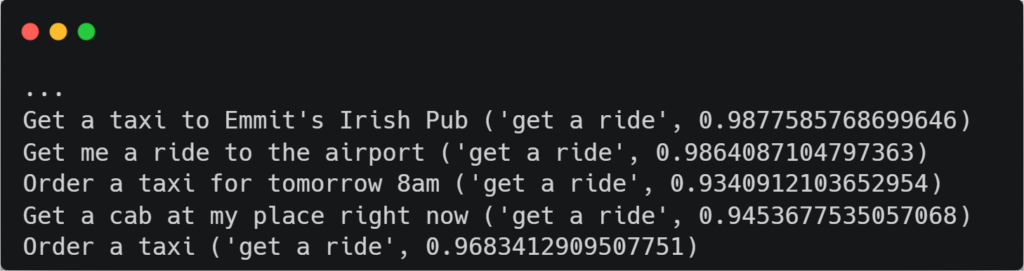
The recall for the “GetWeather” class is 97%, where 41/42 sequences were labeled correctly by the model. This outperforms the dense oBERT model which only gets 90% recall. Not bad!

If we compare the speed of our sparse oBERT against the dense version, we see a robust 4X improvement:
- Sparse oBERT: 2 sets of sequences took 3.9 secs.
- Dense oBERT: 2 sets of sequences took 16.1 secs.
The above numbers were benchmarked on a 10-core PC laptop with avx2 instructions.
Summary: Sparse Zero-Shot Learning
In conclusion, we introduced Neural Magic’s zero-shot pipeline running on a blazing-fast sparse oBERT model.
We outlined some of the pipeline features and experimented on samples from the SNIPS intent classification dataset, ultimately benchmarking results against a dense oBERT.
If you have any questions or comments, please reach out to our community Slack channel or submit a PR on our GitHub. And while there, please support our open-source project while giving us a star!
For a practical example of using a Neural Magic sparse transformer for zero-shot data labeling, please refer to this Rubrix blog.







