

Mar 07, 2023

Author(s)


This is the final entry in our AWS-centric blog series leading up to the AWS Startup Showcase on Thursday, March 9th. We are excited to be a part of this event with other selected visionary AI startups to talk about the future of deploying AI into production at scale. Sign up here to register for this free virtual event, hosted by AWS and SiliconANGLE.
We use the term “software-delivered AI” a lot here at Neural Magic. But what does this mean? Isn’t all AI considered “software”? The machine learning (ML) models themselves are of course software, but it’s the “delivered” piece that we want to focus on for this blog.
AI == TRANSFORMATIONAL CHANGE
Artificial Intelligence, delivered through machine learning, is bringing transformational change across all industries through the extreme automation of complicated tasks previously unthinkable for machines. Examples of this include computer vision for reduced shrinkage in retail, defect detection in manufacturing, logistics efficiencies in warehousing, natural language processing for call center dialogue analysis, etc. However, this transformational change comes with cost and complexity as enterprises find it difficult to get machine learning into production. Model size and model complexity can be major roadblocks due to the dependency on underlying hardware for the deployment of large and complex models. ML models are constantly evolving. Recent studies show that models are now doubling in size every six months. The recent explosion of large language models (LLMs) like ChatGPT, and the entire Generative AI space, contains models that have now grown into billions of parameters

LARGE == COMPLEX AND EXPENSIVE
The larger the model, the more computationally complex it is to run. That means higher compute costs to run those models. Many ML solutions are delivered through very intentional coupling of software (i.e. the models themselves) and hardware, specifically hardware accelerators like GPUs, TPUs, IPUs, NPUs, etc. Organizations have not been able to realize acceptable performance with reasonable costs for production at scale, as new models and hardware emerge so quickly, making it hard to predict spend and ROI.
And then there is the operational complexity. Introducing new hardware accelerators, including the power, networking, and cooling requirements, present another challenge for enterprises. ML models need to be optimized to the specific hardware they will run on, so planning a scaled deployment across a private data center, public cloud, and edge, with a consistent approach, is difficult. How many different models are you going to be deploying in the next 3 years? Which version of which hardware do you need for each model? Which optimizations do you need to make for that hardware? Are the hardware accelerators you need even available in the cloud regions you want to deploy to? Can you deploy those hardware accelerators at your desired edge location?

This expense, uncertainty, and operational overhead slows down the pace of innovation, as well as the rate of adoption of ML solutions. Even if you have the data, tools, and talent to build a game-changing solution, it won’t matter if you cannot deploy and manage it at production scale, at an acceptable cost.
SOFTWARE-DELIVERED AI
Neural Magic helps solve these complexities by enabling organizations to deliver AI through software instead of hardware, allowing ML models to achieve GPU-class performance on commodity CPUs. We accomplish this by leveraging a well-researched ML optimization practice known as sparsity, which allows us to reduce the computational requirements of ML models by up to 95%. But the real “magic” happens through the coupling of those sparsified models with our own DeepSparse runtime. DeepSparse is an inference runtime that was designed specifically for sparsity to enable parallel processing on commodity CPUs as opposed to the traditional sequential processing of GPUs.
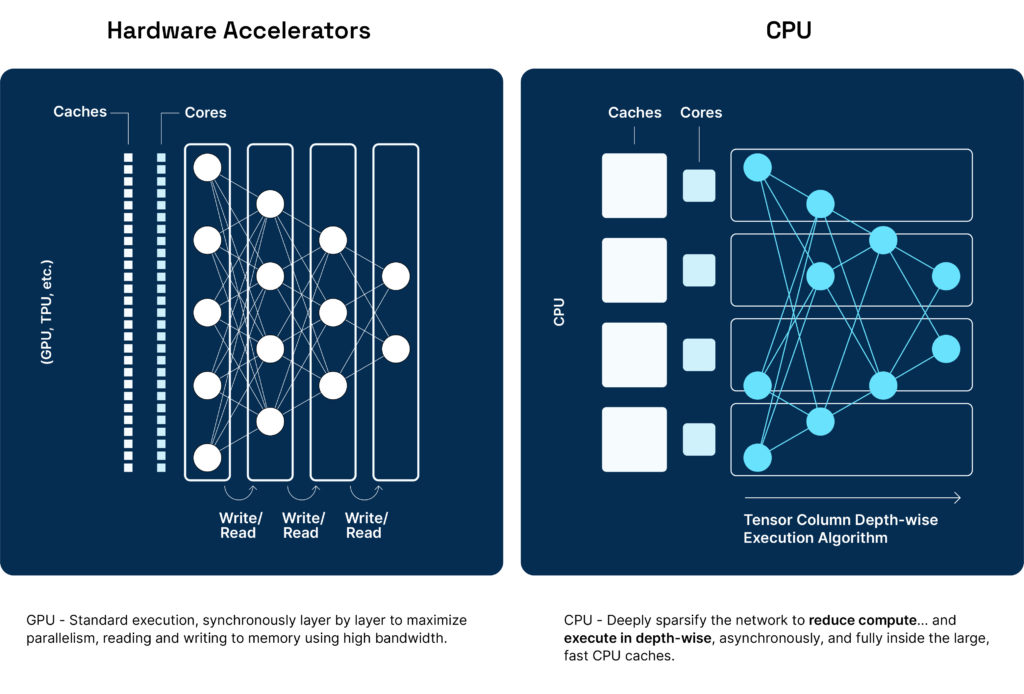
This brings an “optimize once / run anywhere” mentality to ML deployments, as you no longer have to write hardware-specific optimization code for each hardware target. Instead you can sparsify your models one time and run on commodity x86 CPUs across a private data center, public cloud, or edge thanks to the ubiquitous nature of CPUs.
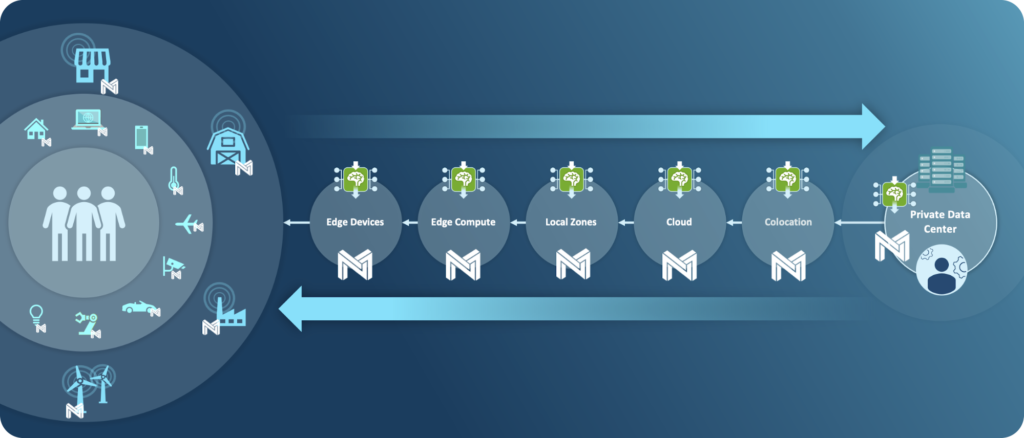
Operational challenges are also minimized because organizations can use the same infrastructure they already have and and their teams know how to run. This is also advantageous when running in the cloud, where you can pay by the minute for CPUs instead of by the hour for GPUs. This also means you don’t have to figure out how to retool to accommodate for GPUs at the edge. Software-delivered AI means simplified AI.
DeepSparse Runtime is also available as a containerized solution, which means you can deploy on top of any container orchestration framework and take advantage of the inherent benefits of a cloud-native architecture. This allows customers to evolve their ML models into actual microservices and leverage the operational benefits of containerized machine learning (horizontal/vertical scale, A/B testing, blue/green rollouts, etc.). All of this is delivered specifically through software and not hardware.
SOFTWARE-DELIVERED RESULTS
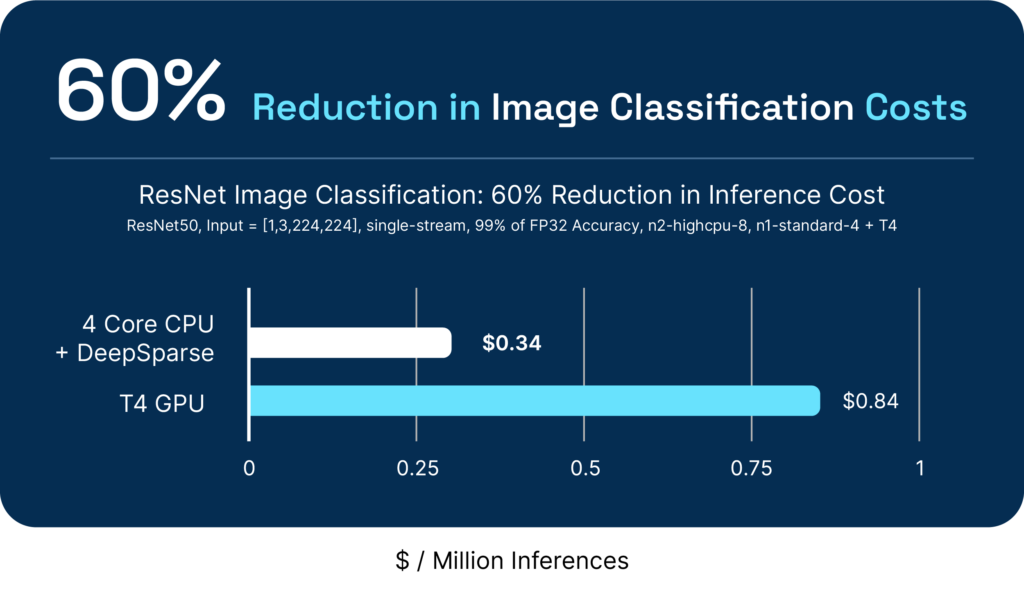
DeepSparse enables greater performance at a lower cost and simplified operations. Below are example performance and cost benchmarks of popular computer vision and natural language processing models against popular readily available hardware accelerators:



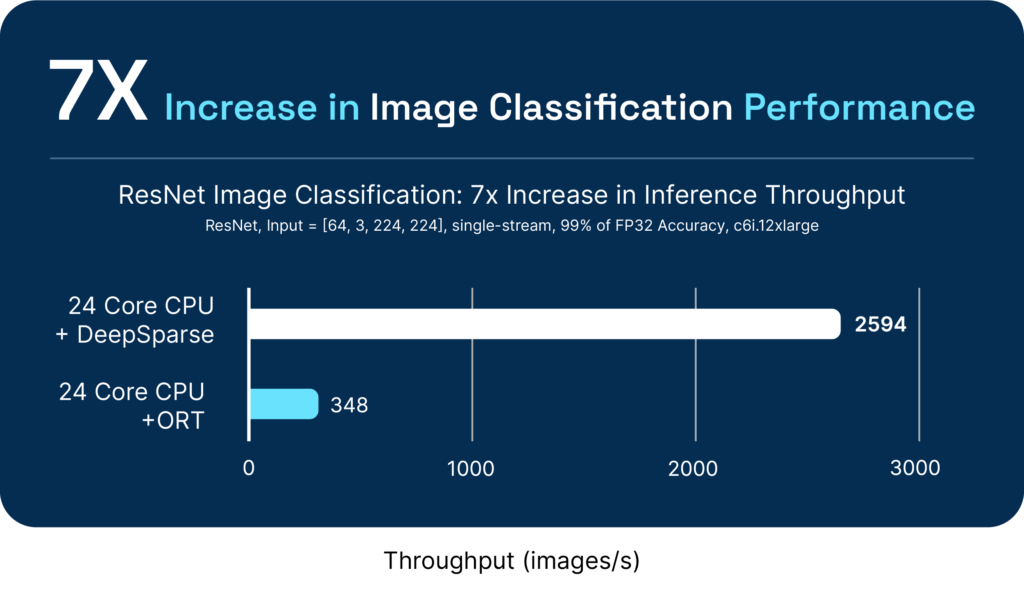
DeepSparse also offers best-in-class performance against other CPU inference runtime options:
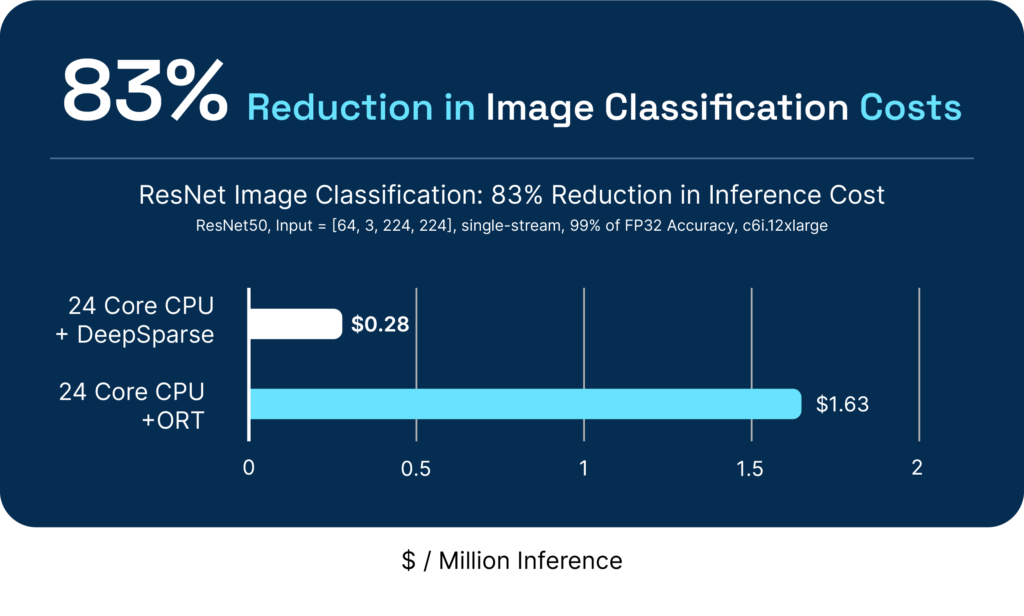
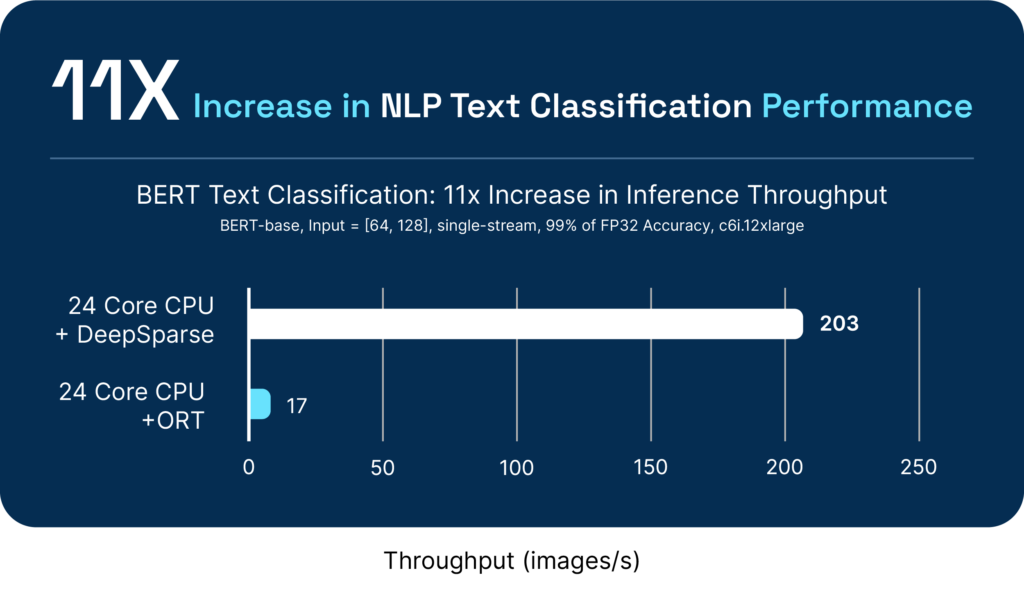
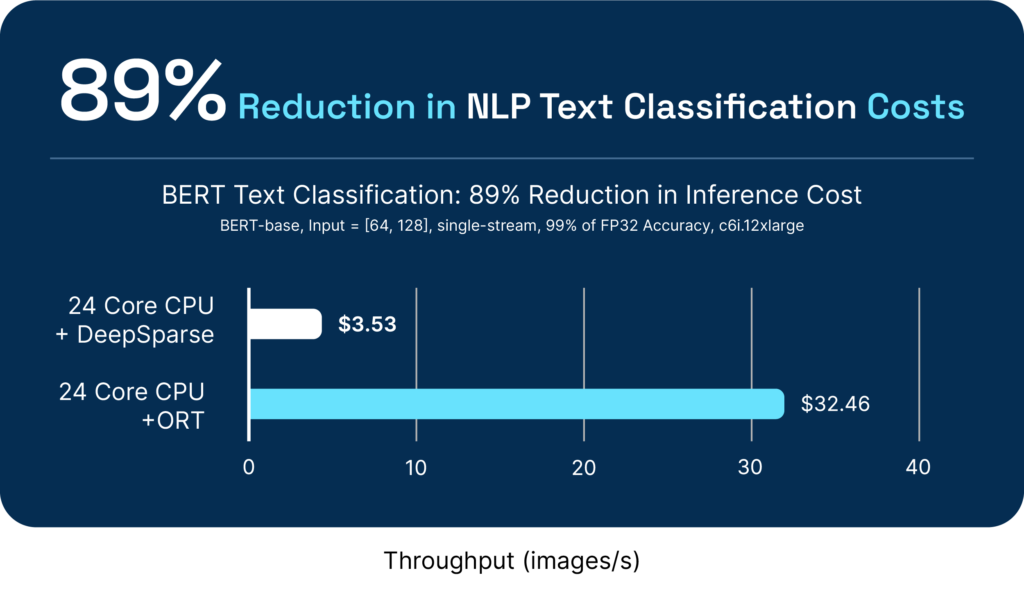
One of our favorite quotes is from an ML Engineer at a large American retailer, who shared "Since deploying to stores, the model has really blown away our data engineers with how computationally cheap it is compared to the standard (…) distribution. It should allow us to more than double the amount of cameras we run on.”
SOFTWARE-DELIVERED ON AWS
We are excited to bring DeepSparse to the AWS Marketplace so AWS customers can achieve these same benefits and results on standard EC2 instances. These instances are available across any and all AWS regions, availability zones, and local zones. This means you don’t have to worry about what kind of specialized hardware acceleration is or is not available in the AWS location that you are deploying your ML solution. It also means you can also deploy that same sparsified model in your private data center or edge location without worrying about the need to recompile or write specialized code. “Optimize once / run anywhere” brings peak performance and low cost anywhere you want to deploy.
Final Thoughts
The transformational value of AI is undeniable. Unfortunately it is also undeniably difficult to get meaningful AI into production. Neural Magic can help by lowering costs and reducing operational complexity while providing the performance and scale that organizations require. Reach out to us if you would like to hear more about how Neural Magic can help your journey to software-delivered AI.
Join us at the AWS Startup Showcase this Thursday, March 9th. We are excited to participate in this event with other selected visionary AI startups, to talk about the future of deploying AI into production at scale. Sign up here to register for this free virtual event.







