
Collaboration

Get started
How to work with NM
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Mauris imperdiet nunc eget ullamcorper ultricies. Cras facilisis purus et orci consequat dapibus.

Step 1
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Mauris imperdiet nunc eget ullamcorper ultricies.

Step 2
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Mauris imperdiet nunc eget ullamcorper ultricies.

Step 3
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Mauris imperdiet nunc eget ullamcorper ultricies.
Optimize Models for Deployment
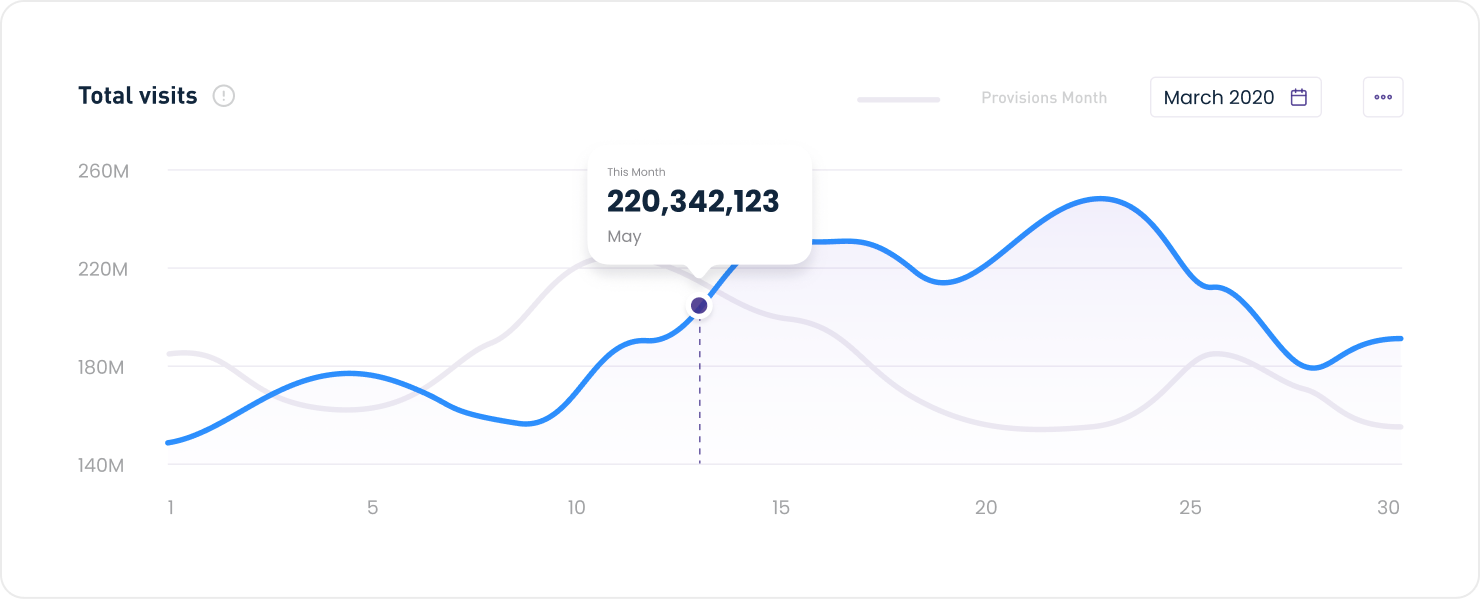
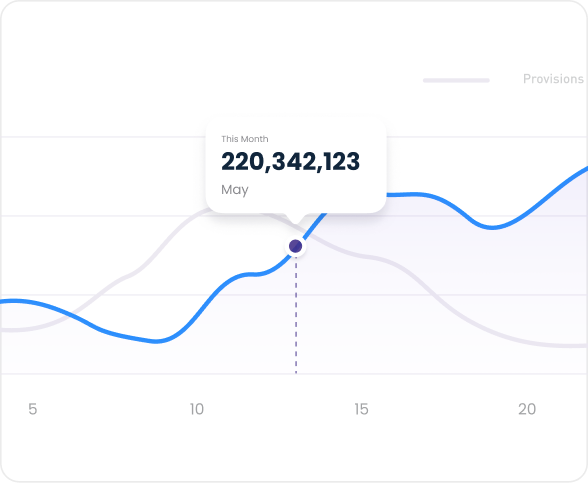
Apply use-case-specific quantization techniques to improve performance and reduce overall hardware spend using lIm-compressor compression toolkit.
Application of the best optimizations for your existing GPUs.
Build Scalable Deployment Serving Systems
Kubernetes and KServe integrations for resilient scale-out deployemnts.
Kubernetes and KServe integrations for resilient scale-out deployemnts.
Kubernetes and KServe integrations for resilient scale-out deployemnts.
Build Scalable Deployment Serving Systems
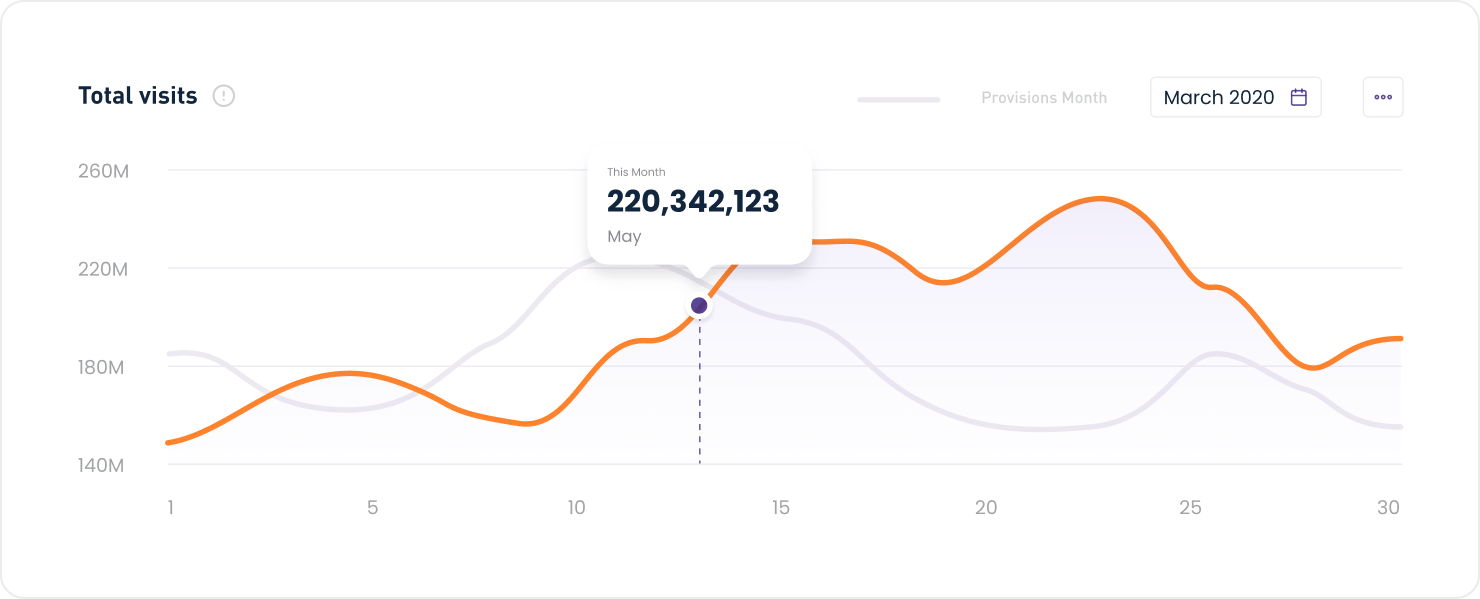
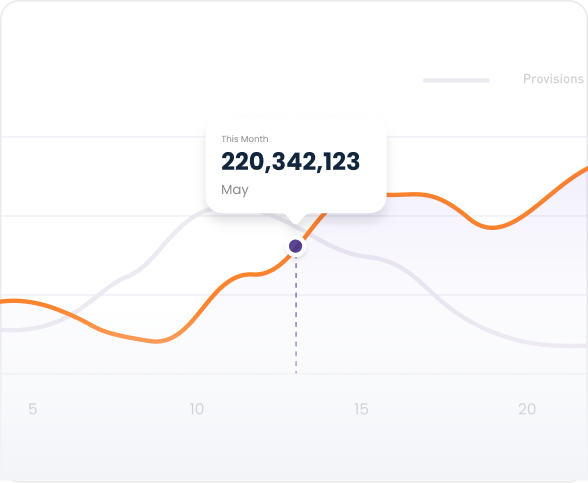
Kubernetes and KServe integrations for resilient scale-out deployemnts.
Kubernetes and KServe integrations for resilient scale-out deployemnts.



