

Dec 13, 2022

Author(s)

Companies have numerous documents such as wikis and internal documentation. These documents could be in the hundreds or thousands. Searching for information from these documents is a painful, long, and tedious process. For instance, you have to manually go through numerous documents to get an answer to a specific question. What if there was a quicker way? Enter Extractive Question Answering. With Extractive Question Answering, you input a query into the system, and in return, you get the answer to your question and the document containing the answer.
Extractive Question Answering involves searching a large collection of records to find the answer. This process involves two steps:
- Retrieving the documents relevant to answering the query, which is done by the Retriever.
- Returning the span of text that answers the question, which is done by the Reader.
Language models can augment the process of reading and retrieving documents. For example, the retriever can be a masked language model, while the reader can be a question-answering model. Masked language models are used because they can find candidate documents based on the similarity of embeddings. They are better compared to other methods such as TF-IDF that rely on exact word matches.
Language models are known to be large and perform very well on natural language tasks. Due to their size, the models are usually slow at inference, especially when no accelerators are used. One way to increase the is by using accelerators such as GPUs. This comes at extra cost and complexity. What if it was possible to get good performance using these large language models but on commodity CPUs? This is where sparsity comes in.
You can reduce the size of the model significantly while maintaining its accuracy. The reduced model size makes it easy to deploy the model and achieve GPU-class performance on commodity CPUs. This blog will teach you how to implement an extractive question answering system using both dense and sparse models. You will then see the difference in the speeds of both models during the creation of embeddings and at inference. You can follow along with the code that is available on Google Colab.
Document Retrieval with DeepSparse and arXiv Dataset
Let’s kick off by creating an in-memory document store to save the arXiv dataset. This is done using haystack, an open-source framework developed by Deepset for building document search systems. Documents and their embeddings are stored in the document store. The documents are then indexed for queries using the write_documents function.
The in-memory store expects:
- The similarity function to be used to compare the document vectors.
- The size of the embedding vector of the language models used.
Apart from in-memory document stores, you can also use the ElasticDocumentStore, FAISSDocumentStore, or WeaviateDocumentStore.
Dense Document Retrieval
First, install the required packages, they are:
pip install deepsparse-nightly[haystack]
pip install sparseml[torch]
pip install farm-haystack[all]==1.4.0 --no-dependenciesDownload and extract the arXiv dataset:
from google_drive_downloader import GoogleDriveDownloader as gdd
gdd.download_file_from_google_drive(file_id='1wrij-aGTeyWEVBPzl0ilwnqkKqk-5D65',
dest_path='./abstract.zip',
unzip=True)Next, convert the documents to dictionaries and write them to the document store. Notice the use of use_gpu=False so that all operations happen in CPUs.
from haystack.document_stores import InMemoryDocumentStore
from haystack.utils import clean_wiki_text, convert_files_to_docs, fetch_archive_from_http
docs = convert_files_to_docs(dir_path='abstract', clean_func=clean_wiki_text, split_paragraphs=True)
document_store = InMemoryDocumentStore(similarity="cosine", embedding_dim=1024, use_gpu=False)
document_store.write_documents(docs)
docs = docs[:500]
# Now, let's write the docs to our DB.
document_store.write_documents(docs)Dense Embedding Retriever
The DeepSparse Embedding Retriever is responsible for obtaining the most relevant documents to the query. It expects:
- The document store.
- The model that will be used to embed the documents.
- The strategy for combining the embeddings.
In this case, we use dense BERT large uncased from the SparseZoo as the embedding model. The embeddings of the query will be similar to the embeddings of the documents containing the answers to the query.
from deepsparse.transformers.haystack import (
DeepSparseEmbeddingRetriever,
DeepSparseReader,
)
retriever = DeepSparseEmbeddingRetriever(
document_store,
(
"zoo:nlp/masked_language_modeling/bert-large/pytorch/huggingface"
"/wikipedia_bookcorpus/base-none"
),
pooling_strategy="reduce_mean",
)Now update the embeddings of the document store using the above retriever.
%%time
document_store.update_embeddings(retriever)This process takes close to 13 minutes.

Define DeepSparse Reader
The next step is to define a reader responsible for obtaining the answer to the query from the relevant documents. Let’s do this using the ExtractiveQAPipeline.
from haystack.pipelines import (
ExtractiveQAPipeline,
)
reader = DeepSparseReader(
model_path="zoo:nlp/question_answering/bert-large/pytorch/huggingface/squad/base-none"
)
pipeline = ExtractiveQAPipeline(reader=reader, retriever=retriever)With all the building blocks in place, the next step is to use the retriever and the reader on the query while timing it.
query = "What is used to compute response of structural system subject to Indian earthquakes at Chamoli and Uttarkashi ground motion data?"
%%time
results = pipeline.run(
query=query,
params={"Retriever": {"top_k": 1}, "Reader": {"top_k": 1}},
)
print(results)The result obtained is:
{
'query': 'What is used to compute response of structural system subject to Indian earthquakes at Chamoli and Uttarkashi ground motion data?',
'answers': [<Answer {'answer': 'Artificial Neural Network (ANN) models', 'type': 'extractive', 'score': 13.098154067993164, 'context': 'Artificial Neural Network (ANN) models to compute response of', 'offsets_in_document': None, 'offsets_in_context': None, 'document_id': '3c973d43b98c370cd6e3f83f5d0b6474', 'meta': {'name': ' Thi_EY116PQZBQ.txt'}}>],
'documents': [<Document: {'content': ' This paper uses Artificial Neural Network (ANN) models to compute response of\nstructural system subject to Indian earthquakes at Chamoli and Uttarkashi\nground motion data. The system is first trained for a single real earthquake\ndata. The trained ANN architecture is then used to simulate earthquakes with\nvarious intensities and it was found that the predicted responses given by ANN\nmodel are accurate for practical purposes. When the ANN is trained by a part of\nthe ground motion data, it can also identify the responses of the structural\nsystem well. In this way the safeness of the structural systems may be\npredicted in case of future earthquakes without waiting for the earthquake to\noccur for the lessons. Time period and the corresponding maximum response of\nthe building for an earthquake has been evaluated, which is again trained to\npredict the maximum response of the building at different time periods. The\ntrained time period versus maximum response ANN model is also tested for real\nearthquake data of other place, which was not used in the training and was', 'content_type': 'text',
'score': 0.9439600264819776, 'meta': {'name': ' Thi_EY116PQZBQ.txt'}, 'embedding': None, 'id': '3c973d43b98c370cd6e3f83f5d0b6474', '__pydantic_initialised__': True}>], 'root_node': 'Query', 'params': {'Retriever': {'top_k': 1}, 'Reader': {'top_k': 1}}, 'node_id': 'Reader'
}
CPU times: user 9.65 s, sys: 584 ms, total: 10.2 s
Wall time: 2.5 sFrom the above result, you can see the Extractive QA system generated the exact answer to the query with a 94% confidence. It also gives the name of the document containing that answer. This process took 2.5 seconds.
Let’s compare the time taken to update the embeddings and get the final result using a sparse model.
Sparse Document Retrieval
Language models are usually over-parameterized. Some of these parameters can be removed without degrading the model's performance. The SparseZoo has various sparse language models to choose from. Let’s use the sparse versions of the models you have already used above for the retriever and the reader.
Sparse Embedding Retriever
The retriever is similar to the one defined in the last section, with the only difference being that the model is sparse.
retriever = DeepSparseEmbeddingRetriever(
document_store,
(
"zoo:nlp/masked_language_modeling/bert-large/pytorch/huggingface"
"/wikipedia_bookcorpus/pruned90-none"
),
pooling_strategy="reduce_mean",
)Update the document embeddings with the sparse model and compare the time taken by the dense model.
%%time
document_store.update_embeddings(retriever)
Updating the document embeddings with the sparse model took 4min 35s compared to close to 13 minutes by the dense model. That is a 3 times improvement in speed.
Define Sparse DeepSparseReader
Next, define a sparse DeepSparseReader.
reader = DeepSparseReader( model_path="zoo:nlp/question_answering/bert-base_cased/pytorch/huggingface/squad/pruned90_quant-none"
)Create an ExtractiveQAPipeline using the sparse reader and retriever.
pipeline = ExtractiveQAPipeline(reader=reader, retriever=retriever)Finally, use this sparse pipeline to obtain the query results.
%%time
results = pipeline.run(
query=query,
params={"Retriever": {"top_k": 1}, "Reader": {"top_k": 1}},
)
print(results)The results are:
{'query': 'What is used to compute response of structural system subject to Indian earthquakes at Chamoli and Uttarkashi ground motion data?', 'answers': [<Answer {'answer': 'Artificial Neural Network (ANN) models', 'type': 'extractive', 'score': 25.388872146606445, 'context': 'Artificial Neural Network (ANN) models to compute response of', 'offsets_in_document': None, 'offsets_in_context': None, 'document_id': '3c973d43b98c370cd6e3f83f5d0b6474', 'meta': {'name': ' Thi_EY116PQZBQ.txt'}}>], 'documents': [<Document: {'content': ' This paper uses Artificial Neural Network (ANN) models to compute response of\nstructural system subject to Indian earthquakes at Chamoli and Uttarkashi\nground motion data. The system is first trained for a single real earthquake\ndata. The trained ANN architecture is then used to simulate earthquakes with\nvarious intensities and it was found that the predicted responses given by ANN\nmodel are accurate for practical purposes. When the ANN is trained by a part of\nthe ground motion data, it can also identify the responses of the structural\nsystem well. In this way the safeness of the structural systems may be\npredicted in case of future earthquakes without waiting for the earthquake to\noccur for the lessons. Time period and the corresponding maximum response of\nthe building for an earthquake has been evaluated, which is again trained to\npredict the maximum response of the building at different time periods. The\ntrained time period versus maximum response ANN model is also tested for real\nearthquake data of other place, which was not used in the training and was', 'content_type': 'text', 'score': 0.9098709908250369, 'meta': {'name': ' Thi_EY116PQZBQ.txt'}, 'embedding': None, 'id': '3c973d43b98c370cd6e3f83f5d0b6474', '__pydantic_initialised__': True}>], 'root_node': 'Query', 'params': {'Retriever': {'top_k': 1}, 'Reader': {'top_k': 1}}, 'node_id': 'Reader'}
CPU times: user 3.01 s, sys: 576 ms, total: 3.59 s
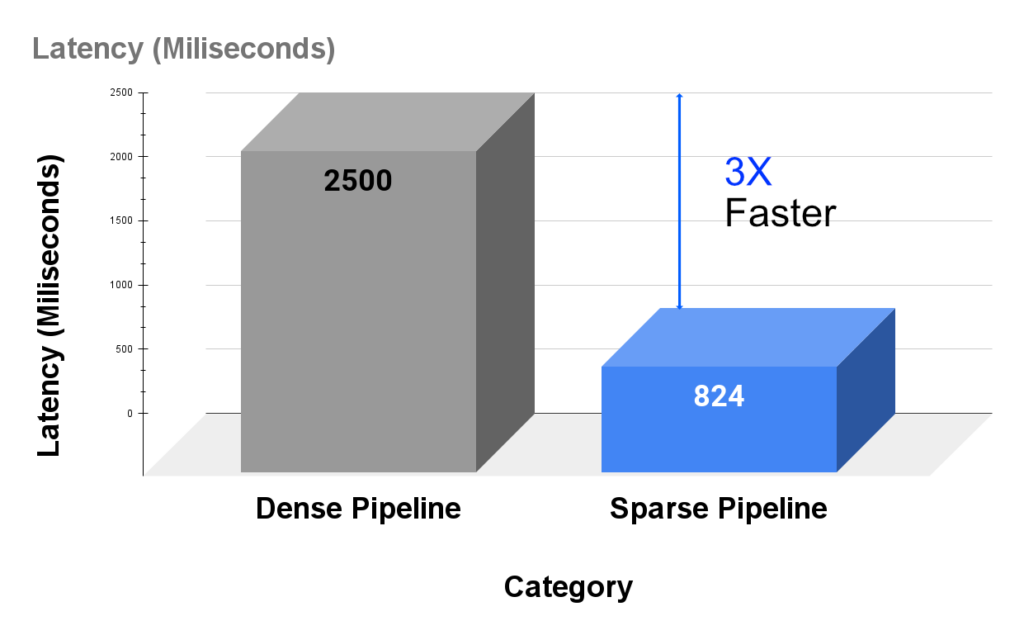
Wall time: 824 msOnce again, the exact answer is generated coupled with the document containing the answer. The sparse pipeline results are generated in 824 milliseconds compared to the 2.5 seconds of the dense pipeline. That is a 3 times increase in speed while obtaining the same accurate results.
Final Thoughts
Given the results obtained above, we can conclude that using a sparse pipeline is a better investment because it generates accurate results faster than a dense pipeline. Furthermore, this pipeline can be deployed using commodity CPUs and does not require expensive hardware for acceleration. To top it up, the models used in the sparse pipeline are smaller than the dense ones and hence easier to deploy. In this article, you have learned that:
- You can quickly search for documents using sparse Transformers.
- You can 3X the speed of updating the document embeddings and obtaining results from an extractive question-answering pipeline using sparse models.
If you have any questions or comments, please reach out on our community Slack or submit a PR on GitHub.






