
Mar 01, 2023

Author(s)

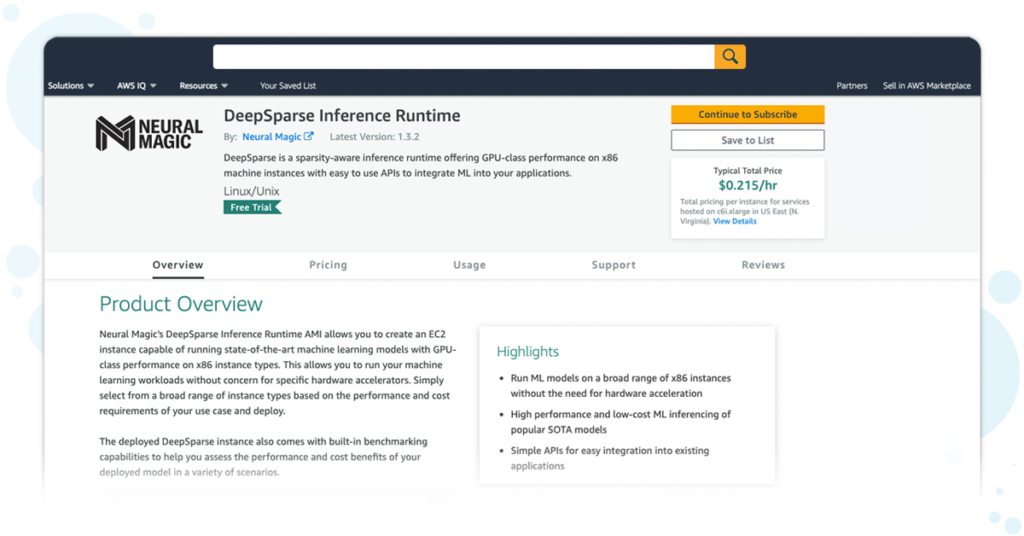
Neural Magic’s DeepSparse Inference Runtime can now be deployed directly from the AWS Marketplace. DeepSparse supports more than 60 different EC2 instance types and sizes, allowing you to quickly deploy the infrastructure that works best for your use case, based on cost and performance. In this blog post, we will illustrate how easy it is to get started.
Deploying deep learning models on the cloud requires infrastructure expertise. Infrastructure decisions must take into account scalability, latency, security, cost, and maintenance in the context of the ML solution to be delivered. These decisions take time to deliberate and can delay deploying and iterating on your ML model. You can now deploy deep learning models with the click of a few buttons with the DeepSparse Inference Runtime on the AWS Marketplace, so you can deploy your use case quickly and achieve GPU-class performance on commodity CPUs.
Here's how you can get started:
Step 1: Subscribe to DeepSparse Inference Runtime from the AWS Marketplace
Start by subscribing to the DeepSparse Inference Runtime.

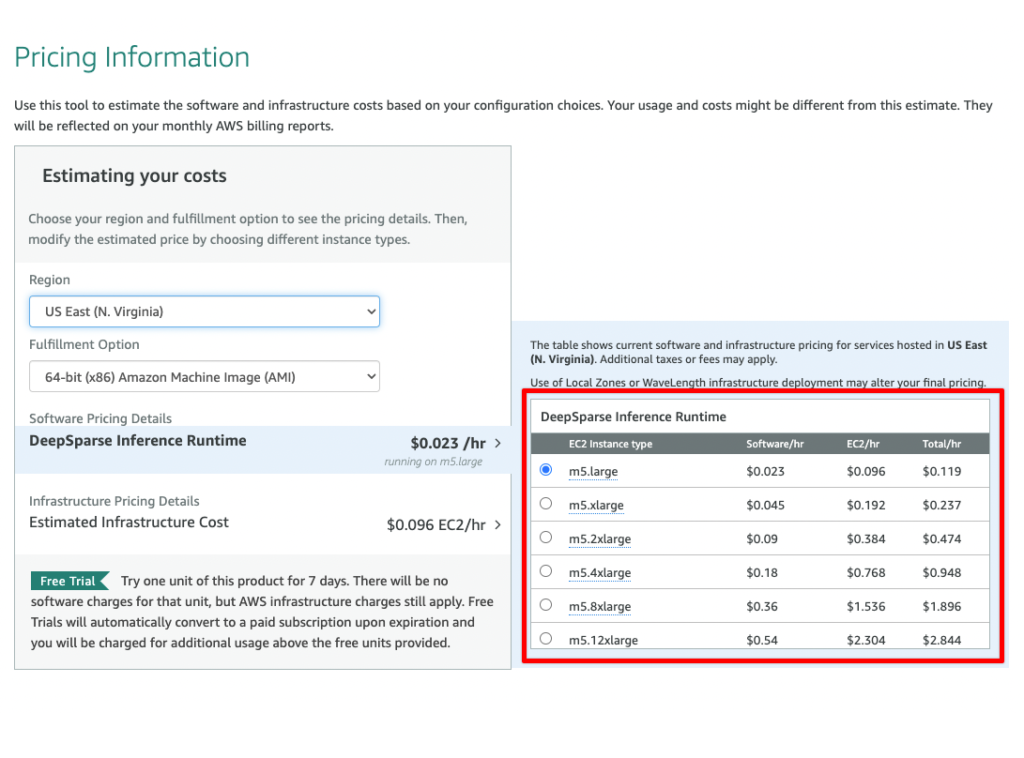
You can try the DeepSparse runtime for free for 7 days. Note, AWS infrastructure charges still apply. Use the calculator provided in the Pricing tab, on this subscription page, to estimate software and infrastructure costs.
Step 2: Configure your DeepSparse Runtime
Once you click Continue to Subscribe, you are directed to a page to confirm your subscription and you can start configuring your instance. Click Continue to Configuration to start the configuration process.

On the next page, complete selections for:
- Fulfillment option
- Software version
- AWS Region
Click Continue to Launch to move to the final configuration page.

Step 3: Launch the DeepSparse Inference Runtime
From this page, you will determine how you want to launch DeepSparse. In this case, we will use the default option to launch from the AWS website. You will then configure:
- EC2 instance type - We recommend the c6i family because they have support for AVX512 VNNI, giving the best speedup for quantization.
- The VPC where this EC2 instance will be created.
- Subnet settings - Create or choose a subnet with internet access to get a public IP address.
- Security group settings - Choose or create a security group allowing ports 22 and 5543. Models deployed on the DeepSparse Server will be accessed on the public IP via port 5543 by default.
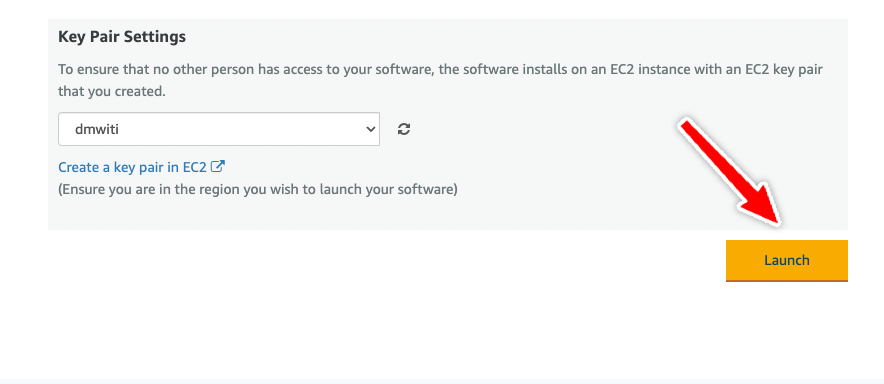
- Key pair settings - Determine the key you’ll use to SSH into the EC2 instance.

Click Launch to start the DeepSparse Inference Runtime.
Step 4: SSH into the EC2 Instance
You have now deployed a DeepSparse Inference Runtime instance on EC2. You can now SSH into that instance to start interacting with it.

Copy your public IP address and log into the instance via SSH.

ssh -i path/to/your/sshkey.pem XXXXXX@your_ipv4_address
Step 5: Deploy a Deep Learning Model with DeepSparse
With DeepSparse installed on the AWS AMI, you are ready to deploy and benchmark a model. DeepSparse provides a benchmarking script to assess the performance of various models.
Here is an example of benchmarking a pruned-quantized version of BERT trained on SQuAD.
deepsparse.benchmark
zoo:nlp/question_answering/bert-base/pytorch/huggingface/squad/pruned95_obs_quant-none -i [64,128] -b 64 -nstreams 1 -s sync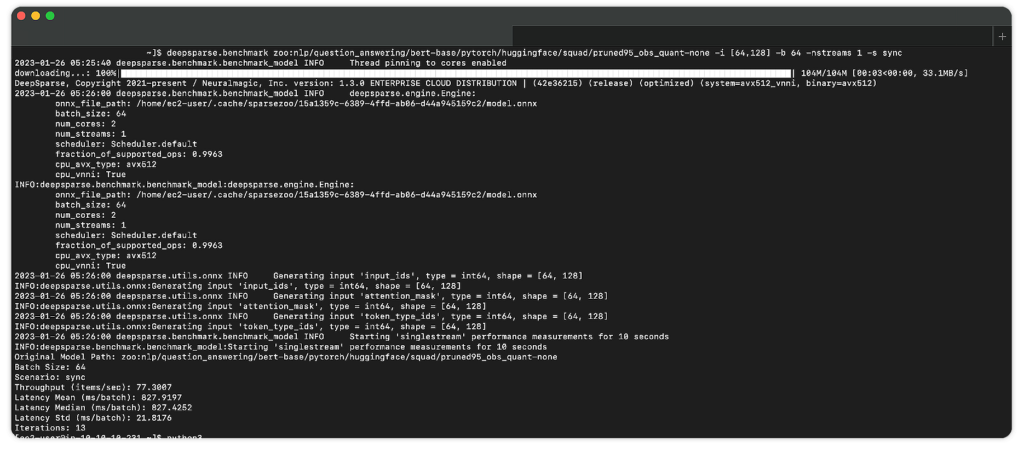
Step 6: Run Inference Using DeepSparse
There are two ways to deploy a model using DeepSparse:
- DeepSparse Pipelines wrap required pre and post-processing steps or
- DeepSparse Server wraps Pipelines with the FastAPI web framework and Uvicorn web server, meaning you don’t have to set this up yourself.
Here is an example of deploying a question-answering system using DeepSparse Pipelines.
from deepsparse import Pipeline
# downloads sparse BERT model from sparse zoo, compiles DeepSparse
qa_pipeline = Pipeline.create(
task="question_answering",
model_path="zoo:nlp/question_answering/bert-base/pytorch/huggingface/squad/pruned95_obs_quant-none")
# run inference
prediction = qa_pipeline(
question="What is my name?",
context="My name is Snorlax")
print(prediction)
# >> score=19.847949981689453 answer='Snorlax' start=11 end=18
The same pipeline can be deployed using the DeepSparse Server by defining it in a YAML file.
loggers:
python:
endpoints:
- task: question_answering
model: zoo:nlp/question_answering/bert-base/pytorch/huggingface/squad/pruned95_obs_quant-noneDownload this config file on the EC2 instance and save it as qa_server_config.yaml.
curl
https://raw.githubusercontent.com/neuralmagic/deepsparse/rs/aws-ami-example/examples/aws-ami/qa_server_config.yaml > qa_server_config.yamlLaunch the server from the CLI. You should see Uvicorn running at port 5543.
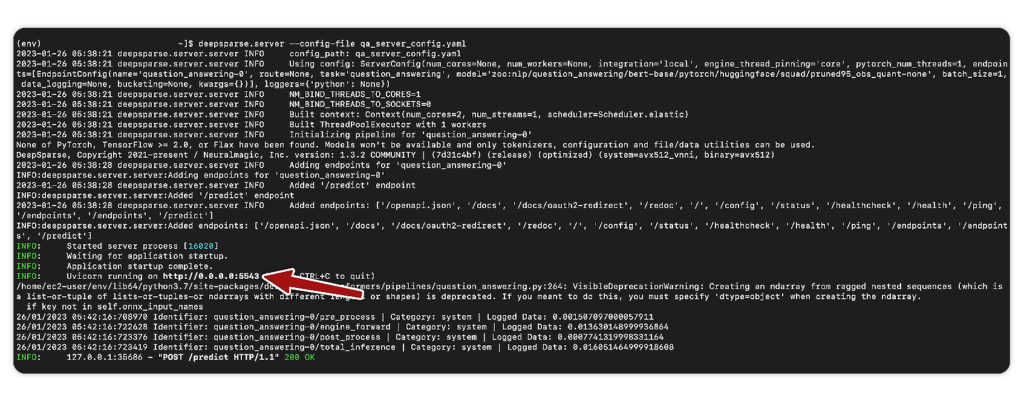
The available endpoints can be viewed by using the docs at http://YOUR_INSTANCE_IP:5543/docs. You can make predictions from the /predict endpoint.
import requests
# fill in your IP address
ip_address = "YOUR_INSTANCE_PUBLIC_IP" # (e.g. 54.160.40.19)
endpoint_url = f"http://{ip_address}:5543/predict"
# question answering request
obj = {
"question": "Who is Mark?",
"context": "Mark is batman."
}
# send HTTP request
response = requests.post(endpoint_url, json=obj)
print(response.text)
# >> {"score":17.623973846435547,"answer":"batman","start":8,"end":14}Next Steps
Now that you have deployed and setup DeepSparse on your selected AWS instance, you can dive deeper into some of the computer vision and natural language processing models available from Neural Magic's SparseZoo for deployment. We have a dedicated blog post just for this topic, where we dive deeper into the available models along with advanced features like benchmarking and monitoring.
Final Thoughts
We are excited to bring DeepSparse to the AWS Marketplace to make it even easier to get your machine learning solutions into production, with the performance and cost advantages DeepSparse provides, running on commodity hardware.
This is the first in a series of AWS-centric blogs leading up to the AWS Startup Showcase on Thursday, March 9th. We are excited to participate in this event with other selected visionary AI startups, to talk about the future of deploying AI into production at scale. Sign up here to register for this free virtual event.






