

Nov 22, 2023

Author(s)


Key Takeaways
- We expanded our Sparse Fine-Tuning research results to include Llama 2. The results include 60% sparsity with INT8 quantization and no drop in accuracy.
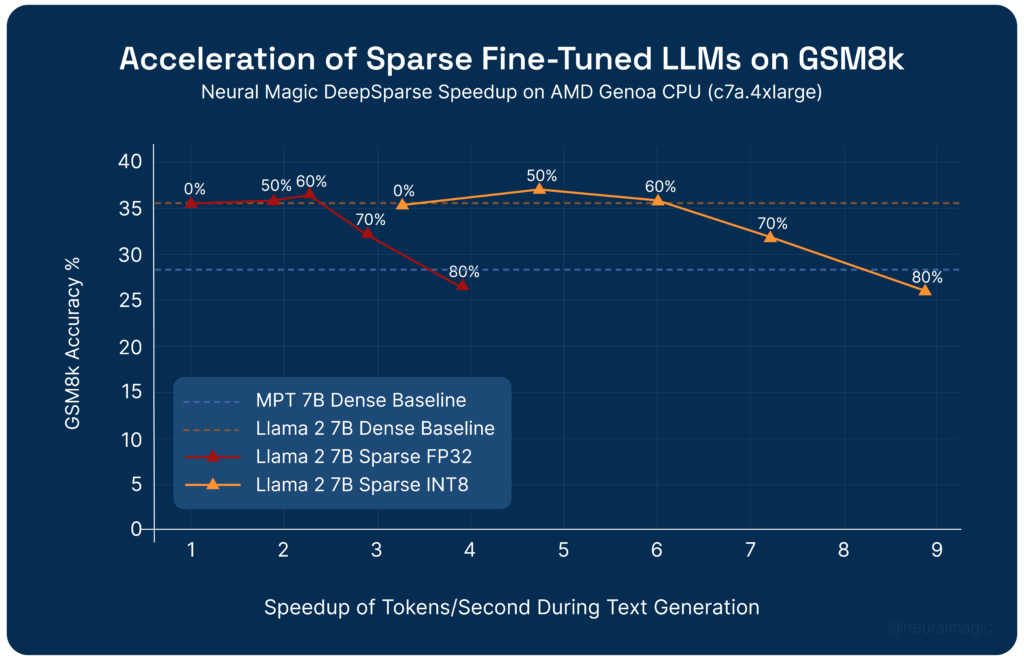
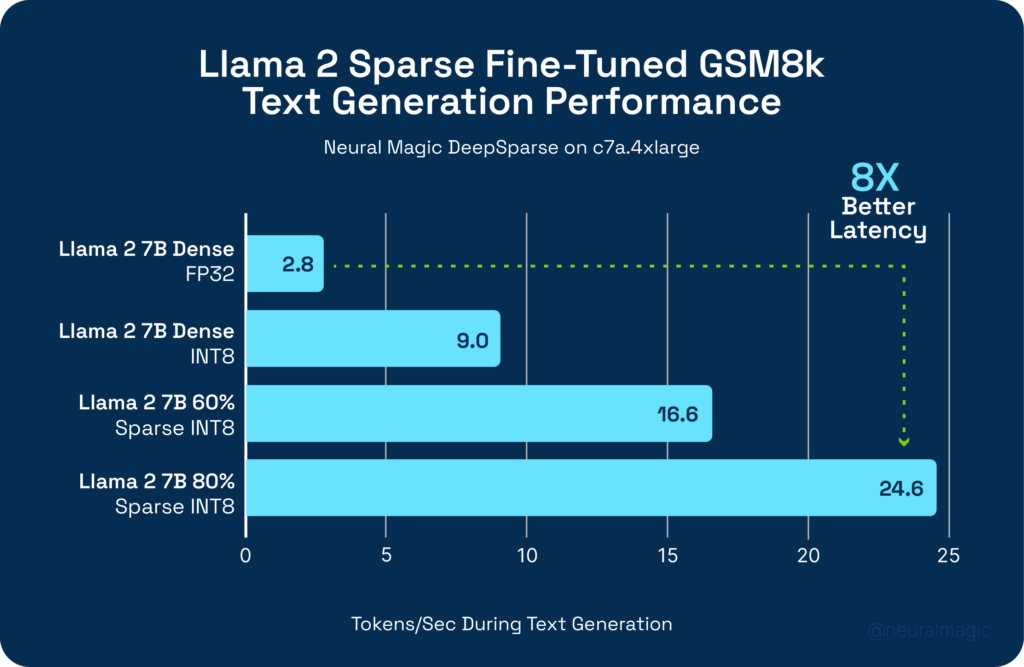
- DeepSparse now supports accelerated inference of sparse-quantized Llama 2 models, with inference speeds 6-8x faster over the baseline at 60-80% sparsity.
- We used some interesting algorithmic techniques in order to quantize Llama 2 weights and activations. We hardened the implementation and packaged them in SparseML for enterprise ML engineers to use.
This year has been an exceptionally exciting year for open-source large language models (LLMs). Just 11 months ago proprietary models, like GPT-3, were the only reasonable choice for companies to build generative AI applications. Now, there is a thriving ecosystem of high-quality open-source models, like Meta’s Llama family. In February, Meta released the LLaMA models, proving it is possible to train a high-quality open-source LLM and share the recipe on how to do it. Later in the year, Meta released Llama 2, an improved version trained on twice as much data and licensed for commercial use, which made Llama 2 the top choice for enterprises building GenAI applications.
Neural Magic’s mission is to enable enterprises to deploy deep learning models, like Llama 2, performantly on standard CPU infrastructure. In our recent research paper collaboration with the Institute of Science and Technology Austria (ISTA), “Sparse Fine-Tuning for Inference Acceleration of Large Language Models,” we showed that combining pruning and quantization with Neural Magic's DeepSparse, a sparsity-aware inference runtime, can accelerate LLM inference on CPUs with no drop in accuracy. This blog summarizes detailed insights on the sparse fine-tuning approach, which focuses on MosaicML’s MPT architecture.
Today, we are excited to announce that we now support Llama 2 in DeepSparse and have extended our Sparse Fine-Tuning research to Llama 2 7B. Yet again, we are able to demonstrate the applicability of our software-acceleration approach to leading model architectures.
Recap: What is Sparse Fine-Tuning?
Training a task-specific LLM consists of two steps:
- First, the model is trained on a very large corpus of text, to create a general model. This first step is called “pre-training.”
- Second, the pre-trained model is then adapted for a specific downstream use case by continuing training with a much smaller, high-quality, curated dataset. This second step is called “fine-tuning”.
Our paper with ISTA demonstrates that by applying model compression algorithms like pruning (which removes parameters from the network) and quantization (which converts parameters from high precision FP32 to low precision INT8) during the fine-tuning process, we can create a highly compressed version of the model without losing accuracy. The compressed models can then be deployed with Neural Magic's DeepSparse, an inference runtime optimized to accelerate sparse-quantized models, to speed up inference by 7x over the unoptimized baseline, and to unlock CPUs as a deployment target for LLMs.
Llama 2 Sparse Fine-Tuning Results
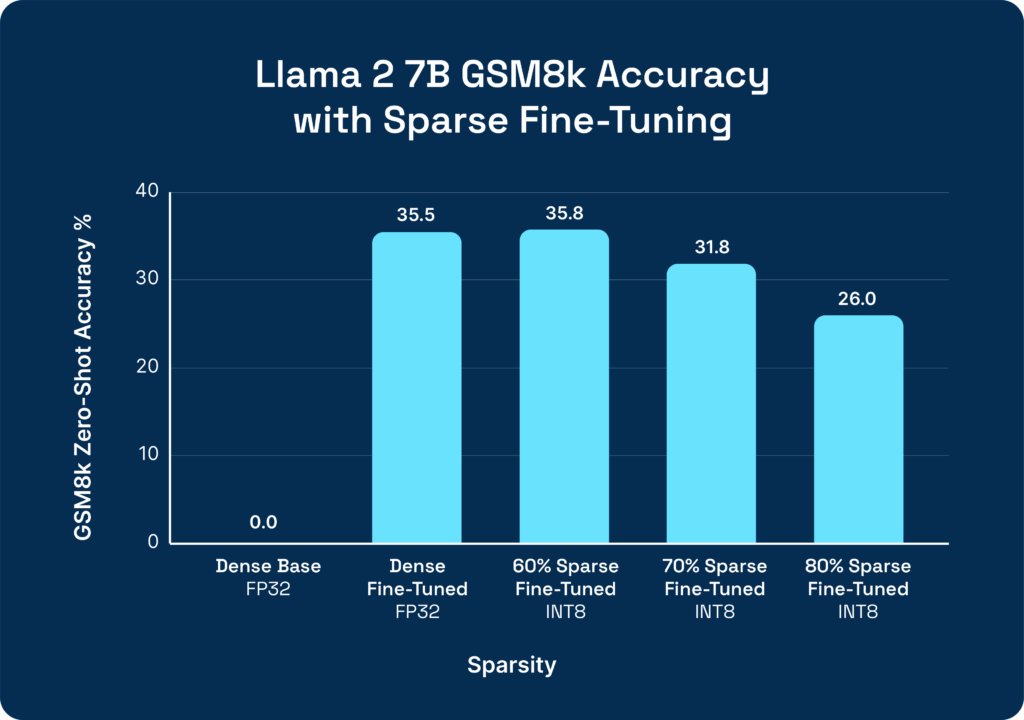
Similar to the MPT setup, we focused on the GSM8k dataset, which consists of diverse grade school math questions. This task is very challenging for LLMs, and the Llama 2 7B base model achieves 0% zero-shot accuracy without any fine-tuning. By fine-tuning for two epochs on the training split of GSM (just ~7k examples), we dramatically improve the test set accuracy to 35.5%.

After fine-tuning, we apply SparseGPT to prune the model and continue training (with model distillation) to recover accuracy. After converging, we apply one-shot quantization to convert both the weights and activations of the model to INT8 from FP32. At the 60% sparse INT8 optimization level, we achieve the full accuracy of the unoptimized model.
The resulting sparse-quantized models can be accelerated with DeepSparse. Running on AMD’s latest Zen 4 Genoa cores (on an AWS c7a.4xlarge instance), DeepSparse accelerates the sparse-quantized Llama models to 6-8x faster over the dense FP32 baseline.
Technical Deep Dive: Quantizing Llama 2

Quantization is an important technique for compressing models and accelerating inference. Most quantization methods for LLMs (such as GPTQ) focus on weight-only quantization. However, since the activations remain at FP16 or FP32, the weights are up-converted at inference time to compute at floating-point precision, meaning inference performance only benefits from reduced data movement (i.e., there is no compute savings; only data movement savings). Minimizing data movement is meaningful for batch 1 inference performance since batch 1 inference is memory-bound, but becomes less valuable for server scenarios where batching can be utilized and the workload becomes more compute-bound.
At Neural Magic, we focus on quantizing both the weights and activations, so we can compress the model and accelerate inference by reducing data movement and compute requirements. However, one of the challenges with quantizing Llama 2 activations (and LLMs in general) is that activations can be tricky due to the presence of outliers in certain layers of the network. To get a quantized value from a floating point number, we use the function x_quant = round(x / scale + zero_point). When outliers are present, the quantization scale must stretch to include them. For example, if a layer has values mostly between -1 and 1, but a few outliers near -10 or 10, the quantization scale must accommodate these extreme values. Because the quantization function becomes less sensitive to variations within the normal range, small yet crucial differences in common values are not accurately captured.
The Neural Magic research team has developed a strong default strategy for quantizing activations for Llama 2 that overcomes these outlier issues. This strategy has been codified in “recipes” available in Neural Magic’s SparseZoo, to make it easy for enterprises to leverage our research to quantize their Llama 2 models.
There are two pieces to the strategy:
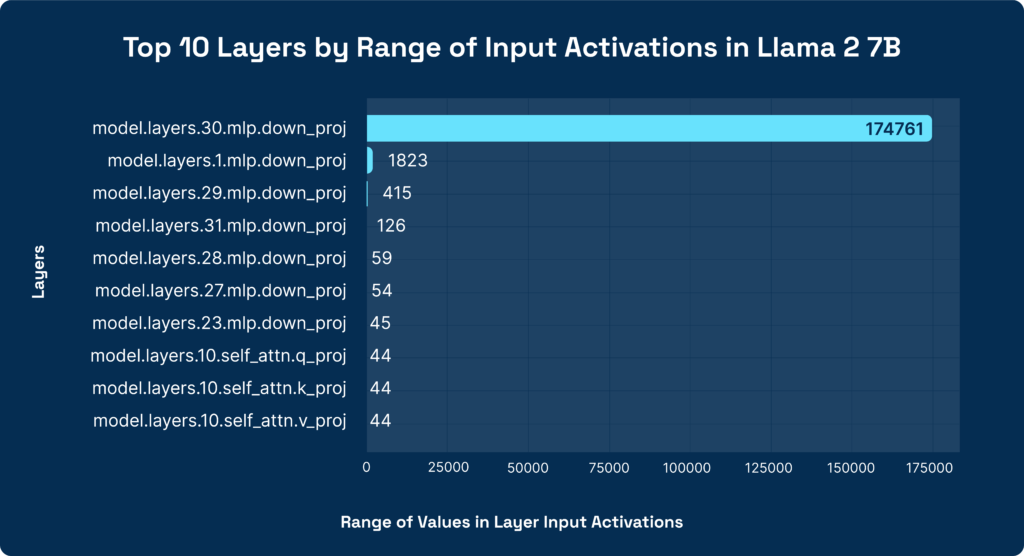
- Selective Quantization: One approach to dealing with outliers is to perform “selective quantization,” where we choose not to quantize the most problematic layers (keeping these layers at FP32 while the rest of the network is at INT8). The optimal criterion for selective quantization is to quantize one layer at a time, measuring the difference in accuracy. This combinatorial process, however, is very time-consuming and our team has developed a much faster heuristic that quickly identifies the most sensitive layers without much experimentation. The graph below shows the top 10 layers of Llama 2 7B sorted by the highest range of activations (the difference between the min and max value of the input) for each layer. The largest layer has a range that is almost 4000x larger than the 10th largest one! Clearly, we will need to treat these layers differently when we develop our quantization recipes.
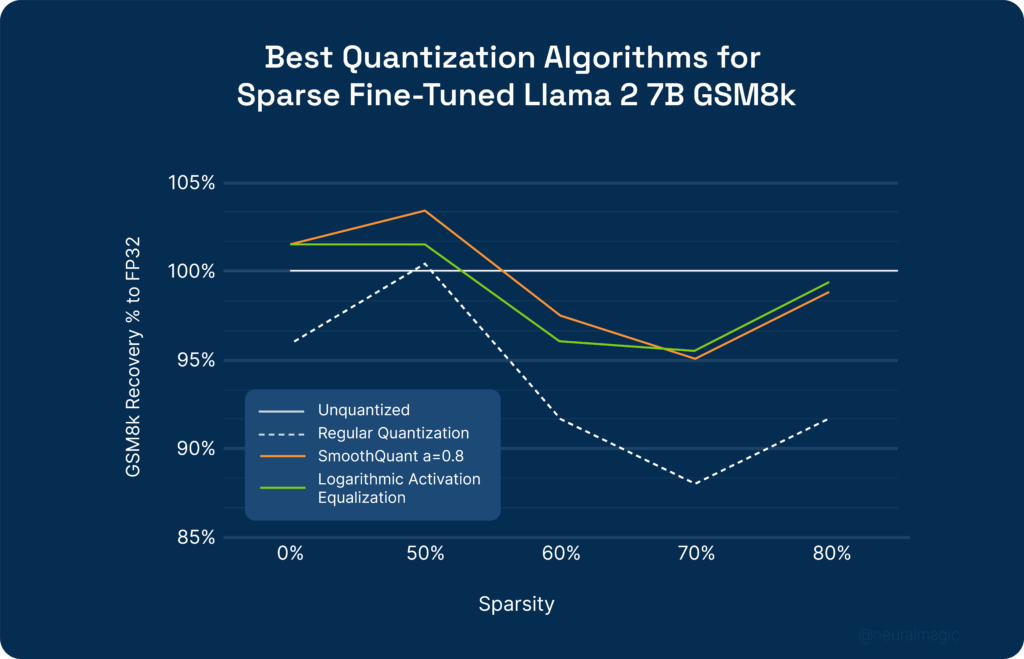
- Smoothing Approaches: In addition to selective quantization, the research community has developed several techniques to deal with outliers in the weights and activations of LLMs, such as SpQR, Logarithmic Activation Equalization (LAE), and SmoothQuant, which offer methodologies for smoothing, adjusting, or extracting the distribution of outliers in weights and activations, to reduce their impact. By applying these algorithms in concert with selective quantization, we can improve the accuracy recovery at various levels of sparsity, as indicated by the graph below, which shows SmoothQuant and LAE consistently outperforming regular quantization approaches across all sparsity levels.
Neural Magic’s open-source model optimization toolkit (SparseML) and recipe repository (SparseZoo) contain all the tools needed to apply this quantization strategy to your Llama 2 fine-tune, to make it easy for enterprise ML engineers to create inference optimized sparse quantized Llama 2 that runs performantly with DeepSparse.
What’s Next?
This work is an example of our continued commitment and focus on industry-leading LLM optimization. We will continue to expand this research to deliver value to our users through the fast CPU deployment of LLMs that run on DeepSparse.
Our priorities include:
- Productizing Sparse Fine-Tuning: We are adapting the research code into SparseML to enable external users to apply Sparse Fine-Tuning to their custom datasets.
- Expanding model support: We have already applied Sparse Fine-Tuning to the popular MPT and Llama 2 architectures, and we will continue to explore Sparse Fine-Tuning with SOTA models like Mistral.
- Pushing to higher sparsity: We continue to improve our pruning algorithms to reach higher levels of sparsity.
Visit the live demo of a Sparse Fine-Tuned Llama running fully on just a CPU. Star and go to the DeepSparse GitHub to learn how to run these models. View all the Llama models on SparseZoo.
Want your own sparse LLM? Reach out to us in our Neural Magic community to let us know what Sparse Fine-Tuned LLM you want to see next!







