
Sep 07, 2022

Author(s)

This YOLOv5 blog post was edited in September 2022 to reflect more-recent sparsification research, software updates, better performance numbers, and easier benchmarking and transfer learning flows.
Prune and Quantize YOLOv5 for a 12x Increase in Performance and a 12x Decrease in Model Files
Neural Magic improves YOLOv5 model performance on CPUs by using state-of-the-art pruning and quantization techniques combined with the DeepSparse Engine. In this blog post, we'll cover our general methodology and demonstrate how to:
- Leverage the Ultralytics YOLOv5 repository with SparseML’s sparsification recipes to create highly pruned and INT8-quantized YOLOv5 models;
- Train YOLOv5 on new datasets to replicate our performance with your own data leveraging pre-sparsified models in the SparseZoo;
- Reproduce our benchmarks using the aforementioned integrations and tools linked from the SparseML Github repo.
Our YOLOv5 workshop, held in July 2022, is centered around these topics. You can view the recording here.
We have previously released support for ResNet-50 and YOLOv3 showing 7x and 6x better performance over CPU implementations, respectively. Furthermore, we’ve created optimized BERT-Base and BERT-Large models that deliver better than GPU-class latency on CPUs with orders of magnitude smaller model files.
Achieving GPU-Class Performance on CPUs
In June of 2020, Ultralytics iterated on the YOLO object detection models by creating and releasing the YOLOv5 GitHub repository. The new iteration added novel contributions such as the Focus convolutional block and more standard, modern practices like compound scaling, among others, to the very successful YOLO family. The iteration also marked the first time a YOLO model was natively developed inside of PyTorch, enabling faster training at FP16 and quantization-aware training (QAT).
The new developments in YOLOv5 led to faster and more accurate models on GPUs, but added additional complexities for CPU deployments. Compound scaling--changing the input size, depth, and width of the networks simultaneously--resulted in small, memory-bound networks such as YOLOv5s along with larger, more compute-bound networks such as YOLOv5l. Furthermore, the post-processing and Focus blocks took a significant amount of time to execute due to memory movement for YOLOv5s and slowed down YOLOv5l, especially at larger input sizes. Therefore, to achieve breakthrough performance for YOLOv5 models on CPUs, additional ML and system advancements were required.
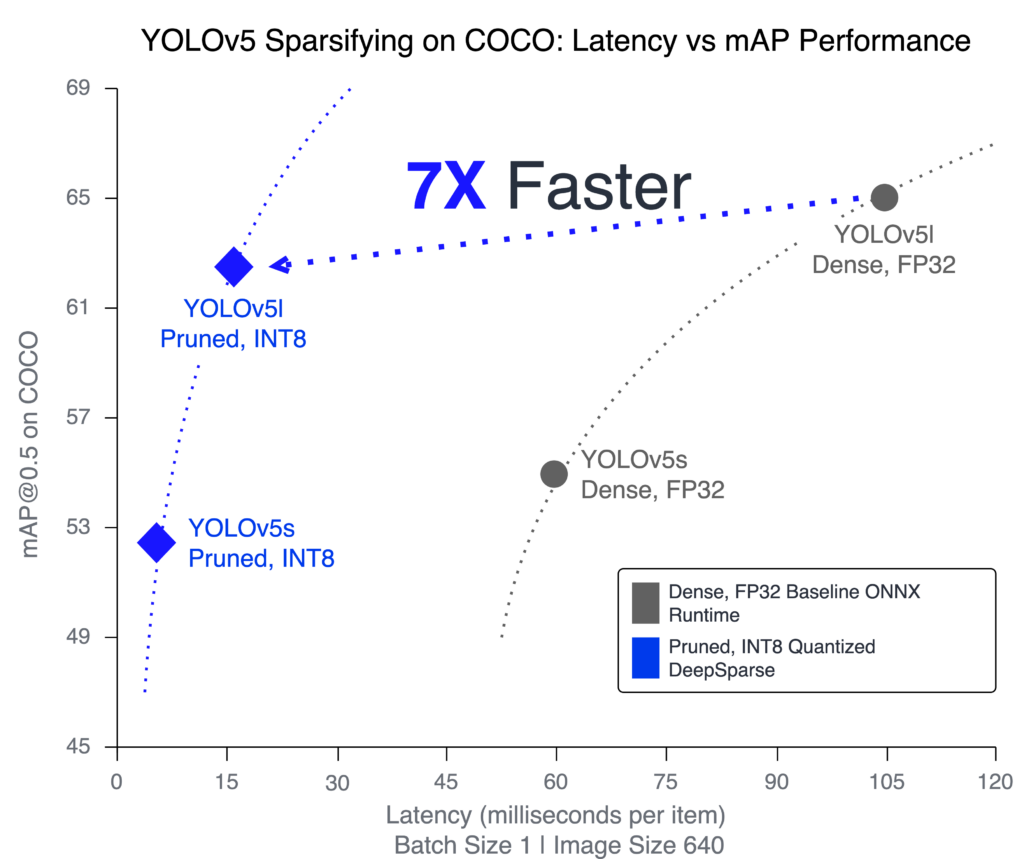
Deployment performance between GPUs and CPUs was starkly different until today. Taking YOLOv5l as an example, at batch size 1 and 640×640 input size, there is more than a 7x gap in performance:
- A T4 FP16 GPU instance on AWS running PyTorch achieved 67.9 items/sec.
- A 24-core C5 CPU instance on AWS running ONNX Runtime achieved 9.7 items/sec
The good news is that there’s a surprising amount of power and flexibility on CPUs; we just need to utilize it to achieve better performance.
To show how a different systems approach can boost performance, we swapped ONNX Runtime with the DeepSparse Engine. DeepSparse Engine has proprietary advancements that better accommodate the advantages of CPU hardware to the YOLOv5 model architectures. These advancements execute depth-wise through the network leveraging the large caches available on the CPU.
Using the same 24-core setup that we used with ONNX Runtime on the dense FP32 network, DeepSparse is able to boost base performance to 18.9 items/sec, a 2x improvement without any optimizations to the model.
The dense FP32 result on the DeepSparse Engine is a notable improvement, but it is still over 3.5x slower than the T4 GPU. So how do we close that gap to get to GPU-level performance on CPUs? Since the network is largely compute-bound on CPU, we can leverage sparsity to gain additional performance improvements. Using SparseML’s recipe-driven approach for model sparsification, plus a lot of research for pruning deep learning networks, we successfully created highly sparse and INT8 quantized YOLOv5l and YOLOv5s models.
Plugging the sparse-quantized YOLOv5l model back into the same setup with the DeepSparse Engine, we are able to achieve 62.1 items/sec -- 6.4x better than ONNX Runtime and nearly the same level of performance as the best available T4 implementation.
A Deep Dive into the Numbers
There are three different variations of benchmarked YOLOv5s and YOLOv5l:
- Baseline (dense FP32)
- Pruned
- Pruned-quantized (INT8)
The mAP at an IoU of 0.5 on the validation set of COCO is reported for all these models in Table 1 below (a higher value is better). Another benefit of both pruning and quantization is that it creates smaller file sizes for deployment. The compressed file sizes for each model were additionally measured and are also found in Table 1 (a lower value is better). These models are then referenced in the later sections with full benchmark numbers for the different deployment setups.
The benchmark numbers below were run on readily available servers on AWS. The code to benchmark and create the models is open sourced in the DeepSparse repo and SparseML repo, respectively. Each benchmark includes end-to-end times, from pre-processing to the model execution to post-processing. To generate accurate numbers for each system, 5 seconds of warmup were run with the following 10 seconds of measurements averaged. Results are recorded in items per second (items/sec) or frames per second (FPS) where a larger value is better.
The CPU servers and core counts for each use case were chosen to ensure a balance between different deployment setups and pricing. Specifically, the AWS C5 servers were used as they are designed for computationally intensive workloads and include both AVX512 and VNNI instruction sets. Due to the general flexibility of CPU servers, the number of cores can be varied to better fit the exact deployment needs, enabling the user to balance performance and cost with ease. And to state the obvious, CPU servers are more readily available and models can be deployed closer to the end-user, cutting out costly network time.
| Model Type | Sparsity | Precision | mAP@50 | File Size (MB) |
| YOLOv5l Base | 0% | FP32 | 65.4 | 147.3 |
| YOLOv5l Pruned | 86.3% | FP32 | 64.3 | 30.7 |
| YOLOv5l Pruned Quantized | 79.2% | INT8 | 62.3 | 11.7 |
| YOLOv5s Base | 0% | FP32 | 55.6 | 23.7 |
| YOLOv5s Pruned | 75.6% | FP32 | 53.4 | 7.8 |
| YOLOv5s Pruned Quantized | 68.2% | INT8 | 52.5 | 3.1 |
Latency Performance
For latency measurements, we use batch size 1 to represent the fastest time an image can be detected and returned. A 24-core, single-socket AWS server is used to test the CPU implementations. Table 2 below displays the measured values (and the source for Figure 1). We can see that combining the DeepSparse Engine with the pruned and quantized models improves the performance over the next best CPU implementation. Compared to PyTorch running the pruned-quantized model, DeepSparse is 7-8x faster for both YOLOv5l and YOLOv5s. Compared to GPUs, pruned-quantized YOLOv5l on DeepSparse nearly matches the T4, and YOLOv5s on DeepSparse is 2x faster than the V100 and T4.
| Inference Engine | Device | Model Type | YOLOv5l items/sec | YOLOv5s items/sec |
| PyTorch GPU | T4 FP32 | Base | 29.1 | 101.3 |
| PyTorch GPU | T4 FP16 | Base | 67.9 | 128.6 |
| PyTorch GPU | V100 FP32 | Base | 75.4 | 86.8 |
| PyTorch GPU | V100 FP16 | Base | 73.6 | 79.9 |
| PyTorch CPU | 24-Core | Base | 11.1 | 24.6 |
| PyTorch CPU | 24-Core | Pruned | 9.1 | 23.4 |
| PyTorch CPU | 24-Core | Pruned Quantized | 9.1 | 23.6 |
| ONNX Runtime CPU | 24-Core | Base | 9.7 | 17.2 |
| ONNX Runtime CPU | 24-Core | Pruned | 6.4 | 17.2 |
| ONNX Runtime CPU | 24-Core | Pruned Quantized | 7.3 | 19.1 |
| DeepSparse | 24-Core | Base | 18.9 | 98.5 |
| DeepSparse | 24-Core | Pruned | 29.6 | 105.6 |
| DeepSparse | 24-Core | Pruned Quantized | 62.1 | 182.5 |
Throughput Performance
For throughput measurements, we use batch size 64 to represent a normal, batched use case for the throughput performance benchmarking. Additionally, a batch size of 64 was sufficient to fully saturate the GPUs and CPUs performance in our testing. A 24-core, single-socket AWS server was used to test the CPU implementations as well. Table 3 below displays the measured values. We can see that the V100 numbers are hard to beat for half precision (FP16); however, pruning and quantizing combined with DeepSparse beat out the T4 performance and V100 for FP32. The combination also beats out the next best CPU numbers by 12x for YOLOv5l and 28x for YOLOv5s!
| Inference Engine | Device | Model Type | YOLOv5l items/sec | YOLOv5s items/sec |
| PyTorch GPU | T4 FP32 | Base | 32.7 | 94.1 |
| PyTorch GPU | T4 FP16 | Base | 83.9 | 204.5 |
| PyTorch GPU | V100 FP32 | Base | 130.7 | 364.9 |
| PyTorch GPU | V100 FP16 | Base | 302.1 | 649.3 |
| PyTorch CPU | 24-Core | Base | 6.8 | 12.8 |
| PyTorch CPU | 24-Core | Pruned | 4.0 | 13.0 |
| PyTorch CPU | 24-Core | Pruned Quantized | 4.0 | 13.0 |
| ONNX Runtime CPU | 24-Core | Base | 11.5 | 14.4 |
| ONNX Runtime CPU | 24-Core | Pruned | 4.8 | 14.4 |
| ONNX Runtime CPU | 24-Core | Pruned Quantized | 5.6 | 15.4 |
| DeepSparse | 24-Core | Base | 28.2 | 136.2 |
| DeepSparse | 24-Core | Pruned | 61.9 | 191.0 |
| DeepSparse | 24-Core | Pruned Quantized | 133.6 | 410.5 |
Replicate with Your Own Data
While benchmarking results above are noteworthy, Neural Magic has not seen many deployed models trained on the COCO dataset. Furthermore, deployment environments vary from private clouds to multi-cloud setups. Below we walk through additional assets and general steps that can be taken to both transfer the sparse models onto your own datasets and benchmark the models on your own deployment hardware.
Sparse Transfer Learning
Sparse transfer learning research is still ongoing; however, interesting results have been published over the past few years building off on the lottery ticket hypothesis. Papers highlighting results for computer vision and natural language processing show sparse transfer learning from being as good as pruning from scratch on the downstream task to outperforming dense transfer learning.
In this same vein, we’ve published an introduction on how to transfer learn from the sparse YOLOv5 models onto new datasets. It’s as simple as checking out the SparseML repository, running the setup for the SparseML and YOLOv5 integration, and then kicking off a command-line command with your data. The command downloads the pre-sparsified model from the SparseZoo and begins training on your dataset. An example that transfers from the pruned quantized YOLOv5l model is given below:
pip install sparseml[torchvision]sparseml.yolov5.train --data VOC.yaml --cfg models_v5.0/yolov5l.yaml --weights zoo:cv/detection/yolov5-l/pytorch/ultralytics/coco/pruned_quant-aggressive_95?recipe_type=transfer --hyp data/hyps/hyp.finetune.yaml --recipe zoo:cv/detection/yolov5-l/pytorch/ultralytics/coco/pruned_quant-aggressive_95?recipe_type=transfer
Benchmarking
To reproduce our benchmarks and check DeepSparse performance on your own deployment, the code is provided as an example in the DeepSparse repo. The benchmarking script supports YOLOv5 models using DeepSparse, ONNX Runtime (CPU), and PyTorch.
For a full list of options run:
deepsparse.benchmark --helpAs an example, to benchmark DeepSparse’s pruned-quantized YOLOv5l performance on your CPU, run:
deepsparse.benchmark
zoo:cv/detection/yolov5-l/pytorch/ultralytics/coco/pruned_quant-aggressive_95 --scenario sync --batch_size 1Conclusion
The DeepSparse Engine combined with SparseML’s recipe-driven approach enables GPU-class performance for the YOLOv5 family of models. Inference performance improved 7-8x for latency and 28x for throughput on YOLOv5s as compared to other CPU inference engines. The transfer learning tutorial and benchmarking example enable straightforward evaluation of the performant models on your own datasets and deployments, so you can realize these gains for your own applications.
These noticeable wins do not stop there with YOLOv5. We will be maximizing what’s possible with sparsification and CPU deployments through higher sparsities, better high-performance algorithms, and cutting-edge multicore programming developments. The results of these advancements will be pushed into our open-source repos for all to benefit. Stay current by starring our GitHub repository or subscribing to our monthly ML performance newsletter here.
We urge you to try unsupported models and report back to us through the GitHub Issue queue as we work hard to broaden our sparse and sparse-quantized model offerings. And to interact with our product and engineering teams, along with other Neural Magic users and developers interested in model sparsification and accelerating deep learning inference performance, join us in the Deep Sparse Community Slack.
Relevant GitHub Repositories
Below is a list of Neural Magic's GitHub repositories used to sparsify and deploy YOLOv5 on CPUs. Please star them to stay current and to support our mission of bringing software and algorithms to the center stage in machine learning infrastructure.






