
Mar 16, 2021

Author(s)

To understand how Neural Magic's Deep Sparse technology works, it's important to quickly cover the journey of our founders. While mapping the neural connections in the brain at MIT, Neural Magic’s founders Nir Shavit and Alexander Matveev were frustrated with the many limitations imposed by GPUs. Along the way, they stopped to ask themselves a simple question: why is a GPU, or any specialized [and expensive] hardware, required for deep learning?
They knew there had to be a better way. After all, the human brain addresses the computational needs of neural networks by extensively using sparsity to reduce them instead of adding FLOPS to match them. If our brains processed information the same way today’s hardware accelerators consume computing power, we could fry an egg on our head. (You can learn more about how unraveling brain structure can lead to new understandings of what our futuristic machine learning hardware should look like by watching this video: Tissue vs. Silicone: Musings on the Future of Deep Learning Hardware.)
Based on this observation and years of multicore computing experience, they created novel technologies that sparsify deep learning networks and allow them to run on commodity CPUs – at GPU speeds and better. How? They exploited CPU strengths and [literally] flipped the script on how sparse kernels are executed. (To visualize the impact of these methods, follow this ResNet-50 benchmarking example: Sparsifying for Better ResNet-50 Performance on CPUs. Or this YOLOv3 example: YOLOv3 on CPUs: Sparsifying to Achieve GPU-Level Performance).
At Neural Magic, we deliver GPU-class performance on CPUs by leveraging two properties of actual brains:
- Their connectivity graph is extremely sparse and
- Their computation is highly localized: when a neuron fires, the receiving neuron is right by it, so there is low communication overhead.
Let's go into more detail on how we mimicked these two brain properties using intricacies of CPU architecture.
GPUs vs. CPUs: The Difference in Architecture and Execution
Today’s standard layer-after-layer execution of neural networks works well with GPUs and other hardware accelerators by utilizing their thousands of tiny synchronous cores across each layer. It has, however, been unsuccessful at delivering performance on CPUs. This is because CPUs typically have less overall compute, and repeatedly reading and writing complete layers to memory incurs the CPU’s lower memory bandwidth. This approach also makes no use of the CPUs advantages: powerful asynchronous cores with large caches.

Right: CPU — 10s of powerful asynchronous cores with large caches and low memory bandwidth.

Right: CPU — Standard execution works poorly: compute missing, and reading and writing layers to memory doesn't perform well due to CPU’s low bandwidth.
Mimicking the Brain: Sparsity
Sparsification is the process of taking a trained deep learning model and removing redundant information from the overprecise and over-parameterized network resulting in a faster and smaller model. Techniques for sparsification are all encompassing including everything from inducing sparsity using pruning and quantization to enabling naturally occurring activation sparsity. When implemented correctly, these techniques result in significantly more performant and smaller models with limited to no effect on the baseline metrics.

Right: CPU — Deeply sparsify the network, without impact to baseline accuracy, to reduce compute...
Sparsification through pruning is a broadly studied ML technique, allowing reductions of 10x or more in the size and theoretical compute needed to execute a neural network, without losing much accuracy. Our Sparsify and SparseML tools allow us to easily reach industry leading levels of sparsity while preserving baseline accuracy.
Mimicking the Brain: Locality of Reference
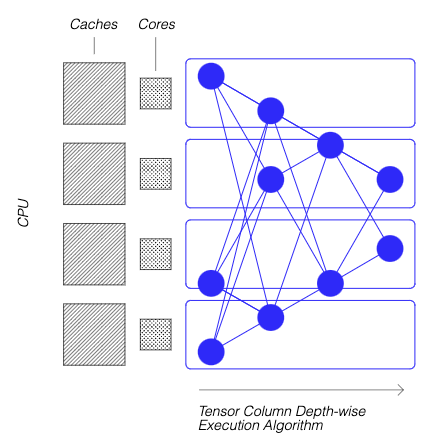
In addition to sparsifying the network, our DeepSparse Engine’s breakthrough sparse kernels execute this sparse computation more effectively. The deeply sparsified computation is memory bound, which is unfortunately not good for a CPU. Our solution to this memory boundedness is to execute the neural network depth-wise rather than layer-after-layer. It might seem like magic, but we are able to break the network into Tensor Columns, vertical stripes of computation that fit completely in cache without having to read or write to memory. Tensor Columns mimic the locality of the brain using the locality of reference of the CPUs cache hierarchy: the outputs of the column’s small section of a layer of neurons waits in cache for the next layer as the sparse execution unfolds depth-wise.

Right: CPU — Deeply sparsify the network to reduce compute…and execute it depth-wise, asynchronously, and fully inside the large CPU caches.
Sparse computation, executed depth-wise in cache, allows us to deliver GPU-class performance on CPUs. You can find all of our software on PyPi, see the code on GitHub, and get detailed information on our Docs website.






