
Our Technology

Today’s ML hardware acceleration (GPUs, TPUs, NPUs, etc) is headed towards chips that apply petaflops of compute to cell phone size memories. Our brains, on the other hand, are biologically the equivalent of applying a cell phone of compute to petabytes of memory. In this sense, the direction taken by hardware designers is the opposite of that, proven out by nature.
But here is what we do know about computation in neural tissue:
- Its connectivity graph is sparse and firing patterns are even sparser.
- Its computation has locality in data transfers: When a neuron fires, the receiving neuron is right by it, so there is low communication overhead.
Can we use these learnings to allow us to make better use of GPU hardware with an abundance of compute and limited memory, and CPU hardware with limited compute and an abundance of memory?
Neural Magic’s approach to performance on both CPUs and GPUs is to mimic nature by leveraging similar sparsity and locality features. Sparsification through pruning is a broadly studied ML technique, that allows reductions of 10x or more in the size and the theoretical flops needed to execute a neural network, without losing much accuracy. Sparsity can help in three ways:
- Memory Footprint (GB): Sparsity reduces memory footprint (on both CPU and GPU)
- Data Movement (GB per FLOP): Sparsity reduces memory traffic (dominates performance of generative LLMs on both CPU and GPU)
- Compute (FLOPS): Sparsity reduces compute with the right execution architecture (harder on GPU, but NM has special kernels)
Locality can help re-use weights to reduce memory to chip data movement, reducing the movement of activations in both CPU and GPU, and on GPUs it can help reduce inter- and intra-swarm data movement.
Finally, Neural Magic is a world leader in quantization of weights, an approach that in the short term can greatly help reduce data movement.
Neural Magic nm-vllm: Enterprise Inference Server for LLMs on GPUs
The execution of generative AI on GPUs is governed by several key parameters: whether the computation is a prefill or decoding step, whether it's a single or multiple GPUs, and whether the execution is by a single unbatched user or in a data center with increasingly large batch sizes.
Neural Magic has created a collection of novel high performance kernels to fit within the vLLM framework to address all of the above cases, utilizing both sparsity and quantization to address all three of the above potential benefits of sparsity: footprint, data-movement, and compute.
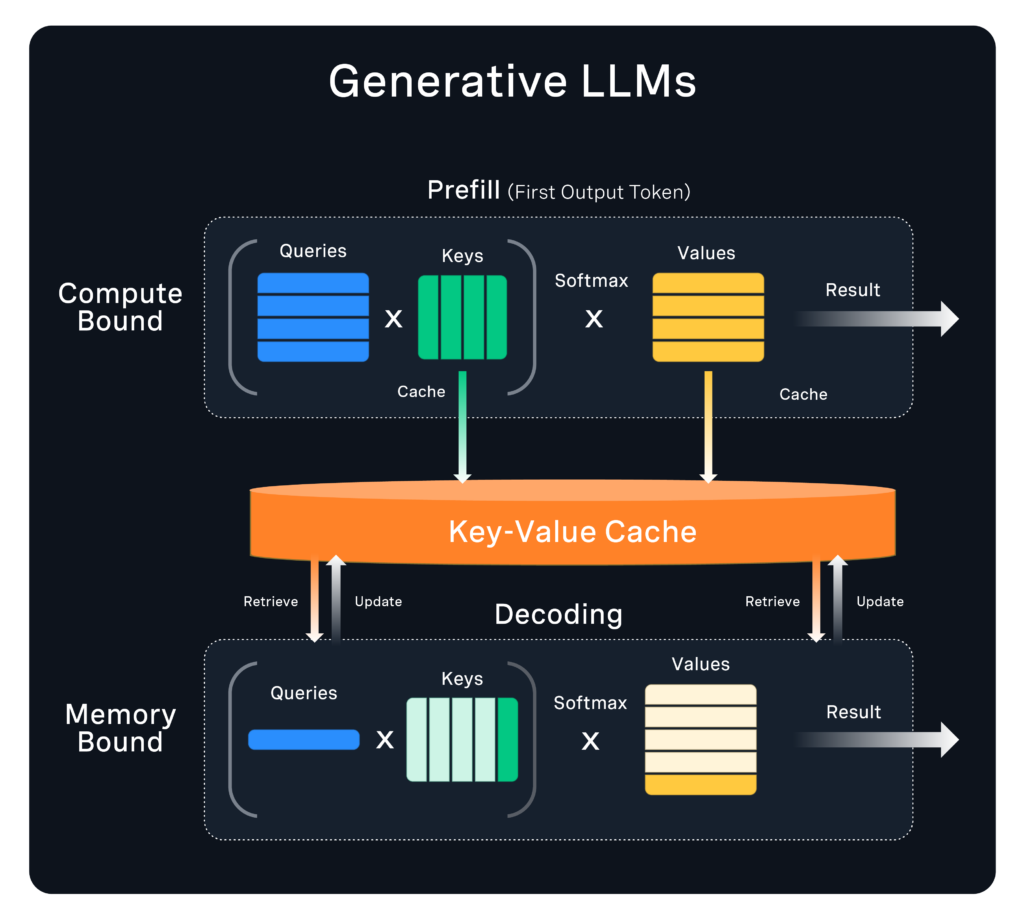
As can be seen in the figure above, in the prefill phase, where batches are large and there is a high compute to memory ratio via matrix-matrix multiplies, our sparse kernels offer good use of 2:4 50% sparsity together with low bit quantization. This allows for a footprint reduction so multiple GPUs are not needed and thus inter-GPU communication is reduced, along with a compute reduction by using the GPU’s ability to execute sparse 2:4 tensors.
In the decoding phase, when there is a low compute to memory ratio because of small batch sizes and vector-matrix operations, our sparse kernels offer reduced memory traffic due to less weights. The reduced memory footprint of the model also enables bringing in more KV cache data, which allows for bigger batches that increase throughput.
The novel kernels would be meaningless without good model optimization techniques. Neural Magic’s novel kernels are combined with state-of-the-art one-shot and fine-tuning techniques to deliver models that reach these combined sparsity and quantization levels with minimal accuracy loss.
Neural Magic DeepSparse: Sparsity-Aware Inference Server for CPUs
Neural Magic’s DeepSparse inference server is designed to mimic, on commodity hardware, the way brains compute. It uses neural network sparsity combined with locality of communication by utilizing the CPU’s large fast caches and its very large memory.
While a GPU runs networks faster using more FLOPs, Neural Magic runs them faster via a reduction in the necessary FLOPs. Our SparseML toolkit allows us to easily reach industry leading levels of sparsity while preserving baseline accuracy, and DeepSparse's breakthrough sparse kernels execute this computation effectively.
But once FLOPs are reduced, the computation becomes more “memory bound”, that is, there is less compute per data item, so the cost of data movement in and out of memory becomes crucially important. Some hardware accelerator vendors propose data-flow architectures to overcome this problem. Neural Magic solves this on commodity CPU hardware by radically changing the neural network software execution architecture. Rather than execute the network layer after layer, we are able to execute the neural network in depth-wise stripes we call Tensor Columns.
Tensor Columns mimic the locality of the brain using the locality of reference of the CPU's cache hierarchy. Each Tensor Column stays completely in the CPU’s large fast caches along the full execution length of the neural network, wherein the column outputs of a small section of a layer of neurons wait in cache for the next layer as the sparse execution unfolds depth-wise. In this way, we almost completely avoid moving data in and out of memory.
The DeepSparse software architecture allows Neural Magic to deliver GPU-class performance on CPUs. We deliver neural network performance all the way from low power, sparse, in cache computation on edge devices, to large footprint models in the shared memory of multi-socket servers.