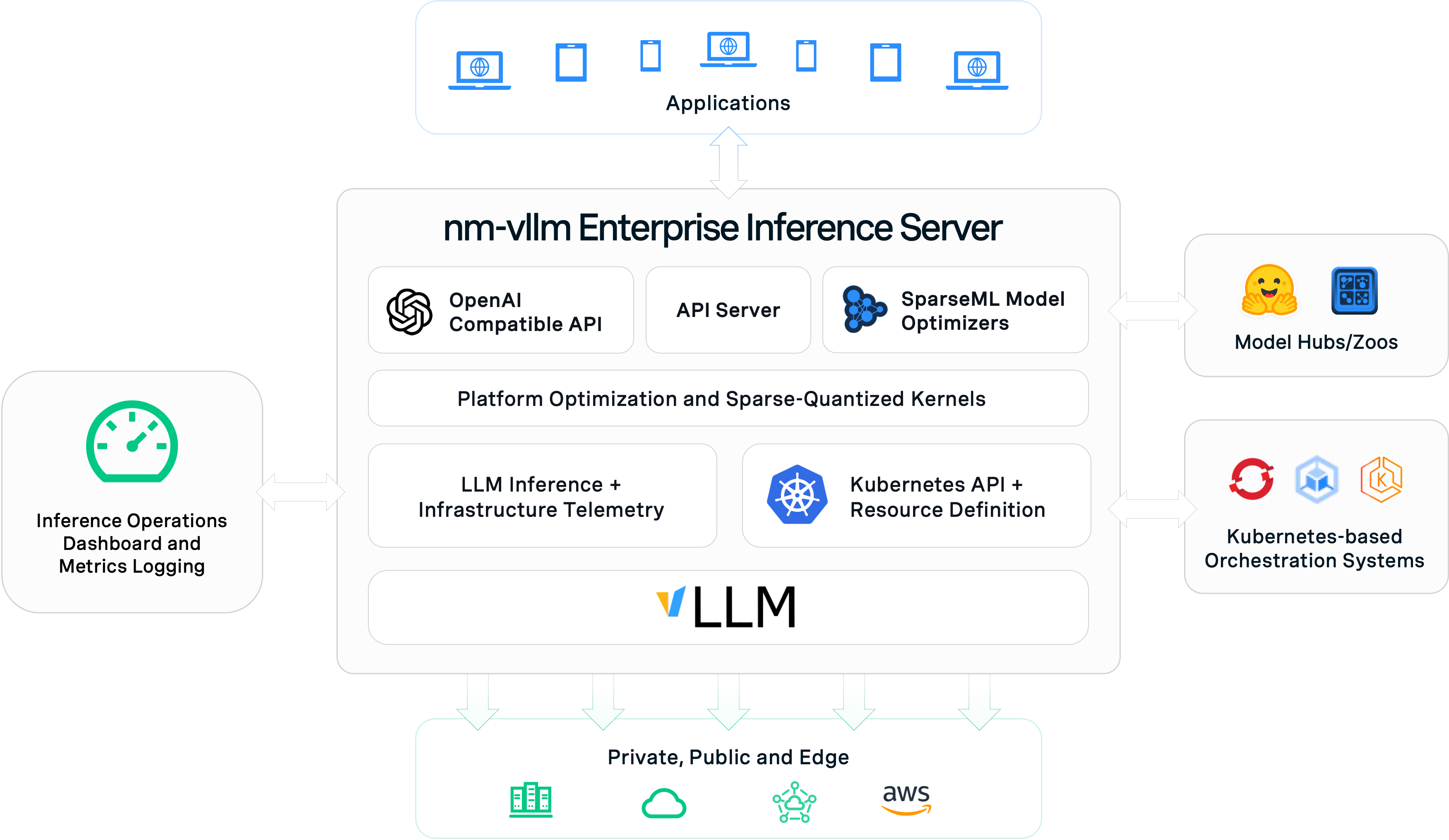
how it works
Accelerate LLMs to Production
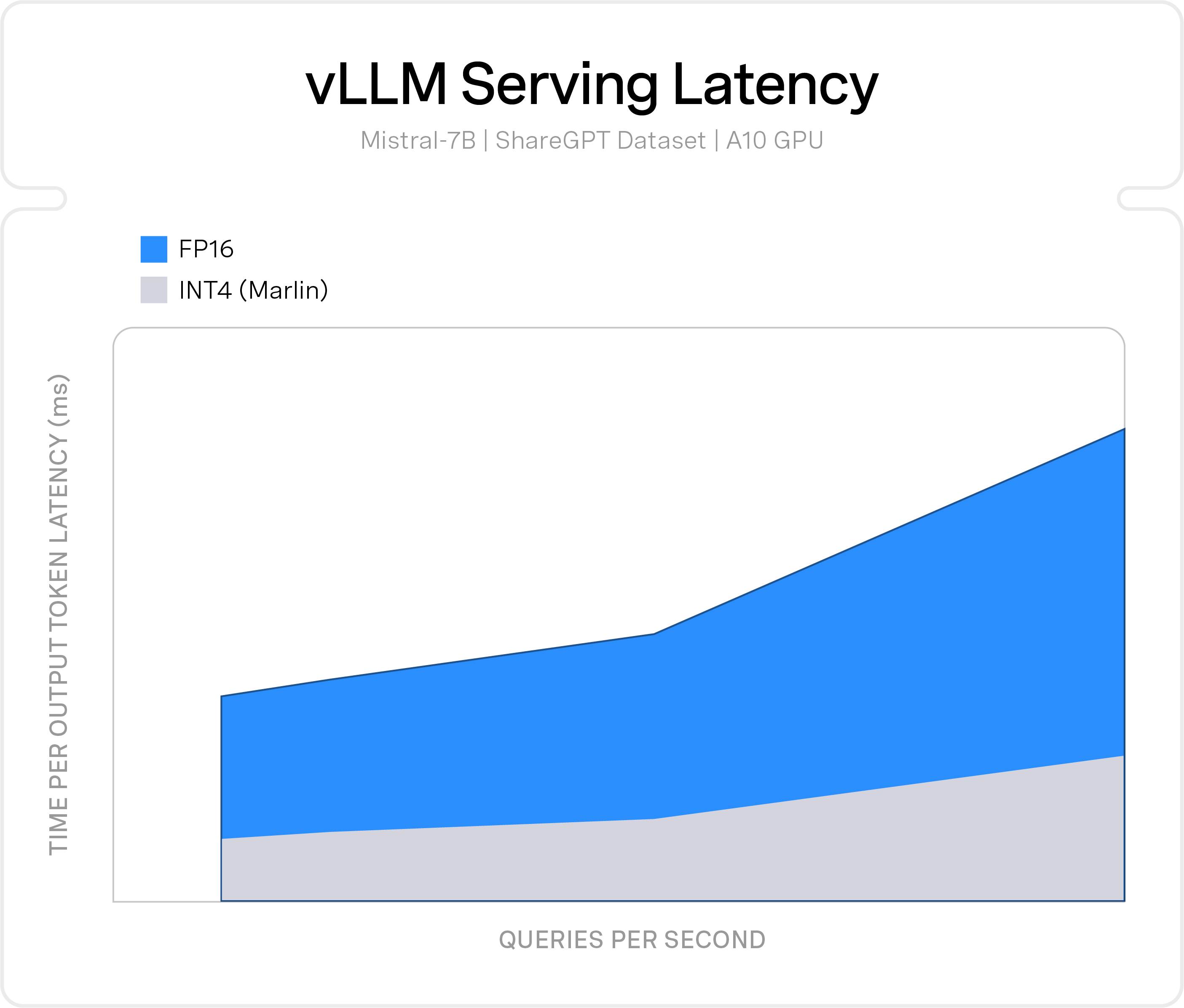
nm-vllm is an enterprise inference server for at-scale operationalization of performant open-source large language models (LLMs). It enables you to optimize open-source LLMs from native Hugging Face and PyTorch frameworks with Neural Magic SparseML to then deploy directly to production on your infrastructure of choice.
With nm-vllm, enterprises have a choice - from cloud, datacenter, to edge - on where to run open-source LLMs with complete control over performance, privacy, security and model lifecycle.