Enterpise Strategy
Why
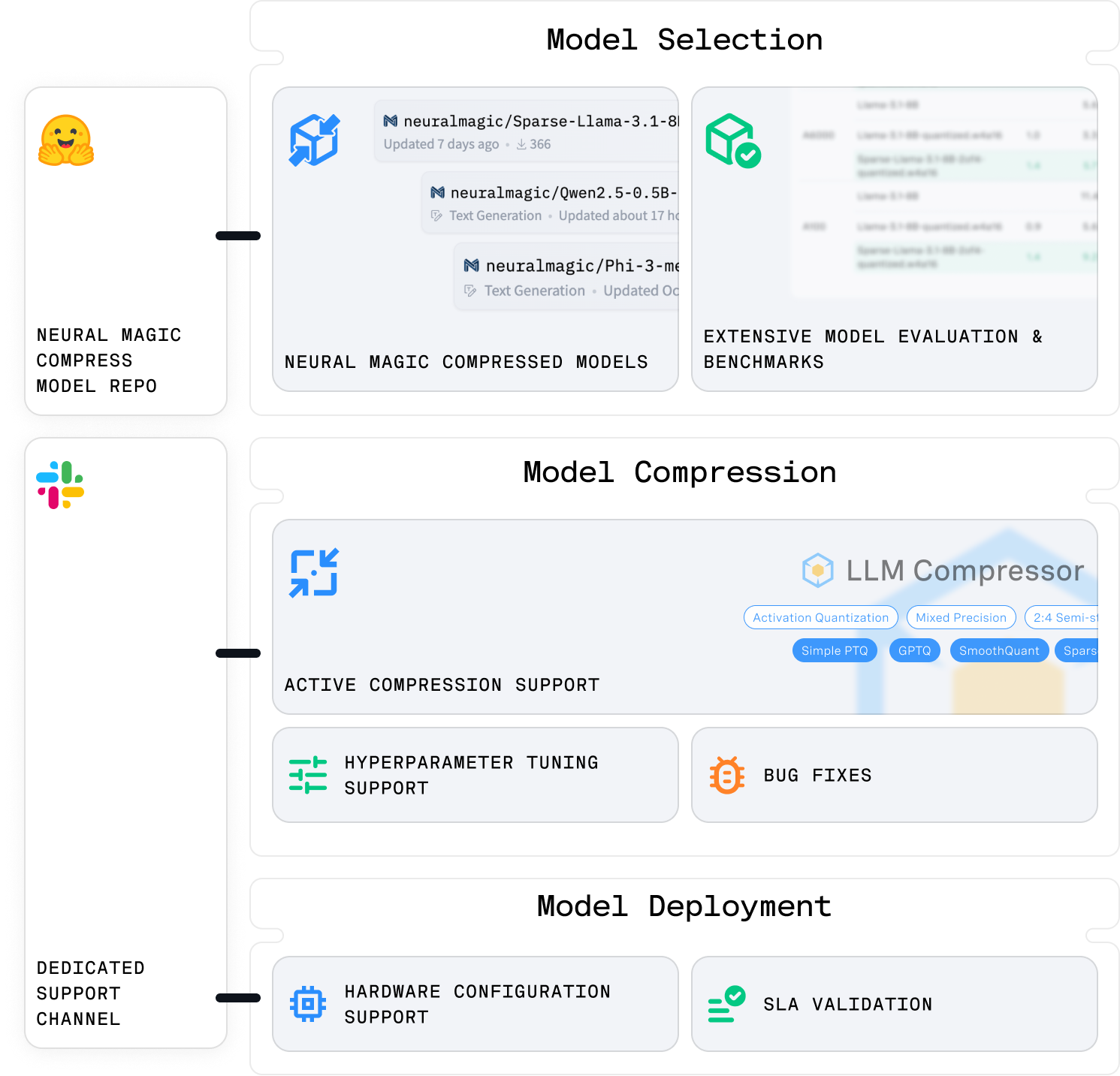
Neural Magic Compress
Neural Magic leads open-source AI innovation, recognized as the top commercial contributor to vLLM and LLM Compressor, and a pioneer in state-of-the-art model compression research and publications. With our Compress subscription, enterprises gain:
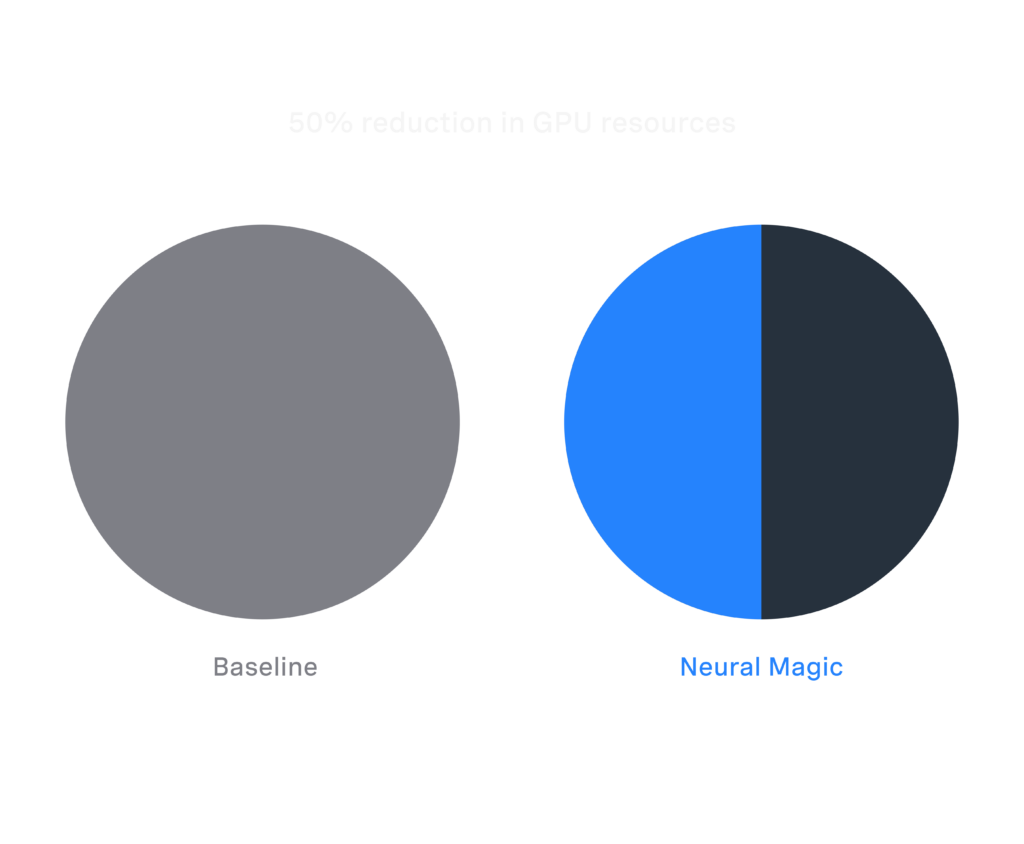
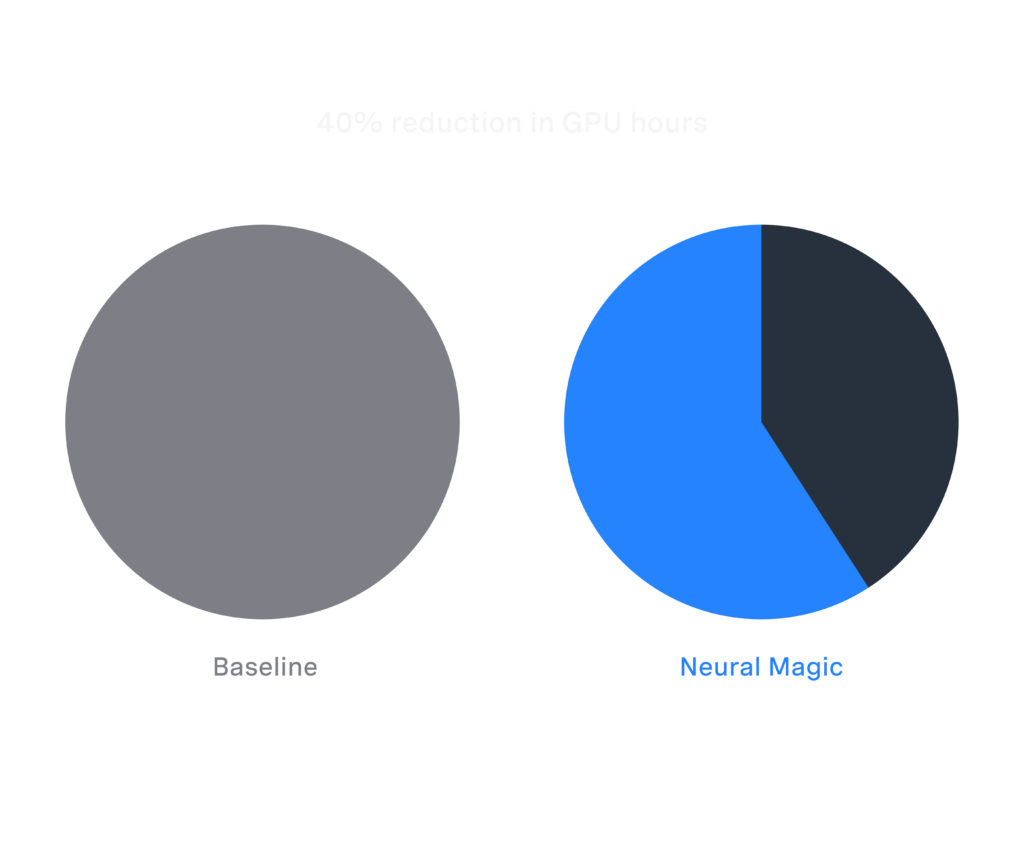
- SOTA Compressed Models: Achieve full accuracy recovery and optimized inference performance tailored for diverse enterprise use cases.
- Robust Compression Toolkit: Using our llm-compressor toolkit, we will guide you through the process of compressing your existing models.
- Enterprise-Grade Support: Access dedicated expertise, feature development, and bug fixes for accelerated AI success.
Our Commitment: To transform enterprise AI by merging groundbreaking research with actionable performance, delivering efficient, scalable, and production-ready solutions.