how it works
Accelerate Deep Learning on CPUs
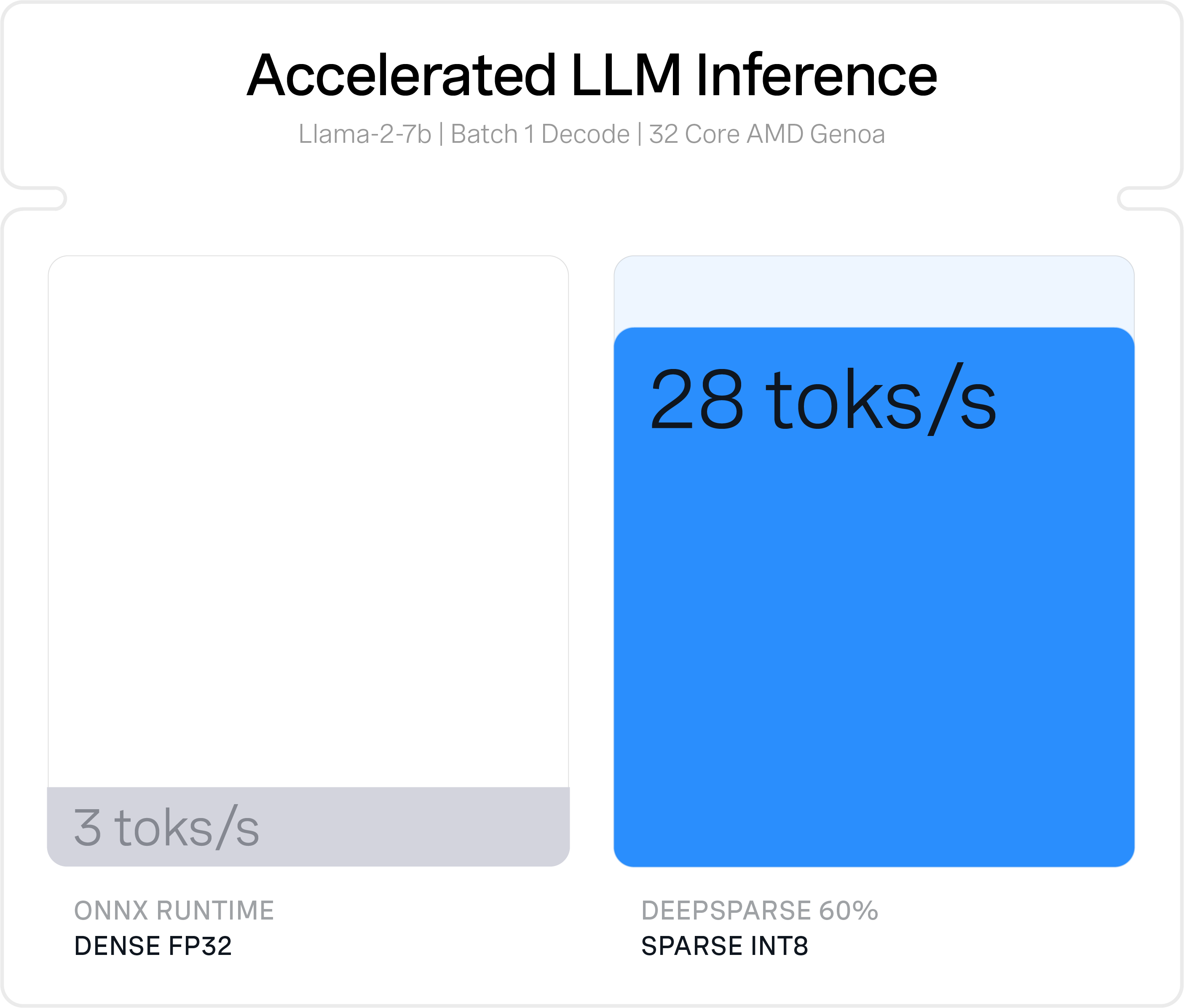
DeepSparse achieves its performance using breakthrough algorithms that reduce the computation needed for neural network execution and accelerate the resulting memory-bound computation.
On commodity CPUs, the DeepSparse architecture is designed to emulate the way the human brain computes. It uses:
- Sparsity to reduce the number of floating-point operations.
- The CPU’s large fast caches to provide locality of reference, executing the network depth-wise and asynchronously.