

Jan 28, 2025
Originally posted at: https://blog.vllm.ai/2025/01/27/v1-alpha-release.html
We are thrilled to announce the alpha release of vLLM V1, a major upgrade to vLLM’s core architecture. Based on lessons we learned over the past 1.5 years of vLLM development, we revisited key design decisions, consolidated various features, and simplified the codebase to enhance flexibility and scalability. V1 already achieves state-of-the-art performance and is set to gain even more optimizations. Best of all, users can enable V1 seamlessly—just set the VLLM_USE_V1=1 environment variable without any changes to the existing API. After testing and feedback collection in the coming weeks, we plan to transition V1 into the default engine.
Why vLLM V1?
Learning from vLLM V0
Over the past 1.5 years, vLLM has achieved remarkable success in supporting diverse models, features, and hardware backends. However, while our community scaled horizontally, we faced challenges making the systems simple and integrating various optimizations vertically across the stack. Features were often developed independently, making it difficult to combine them effectively and cleanly. Over time, technical debt accumulated, prompting us to revisit our foundational design.
Goals of V1
Based on the above motivation, vLLM V1 is designed to:
- Provide a simple, modular, and easy-to-hack codebase.
- Ensure high performance with near-zero CPU overhead.
- Combine key optimizations into a unified architecture.
- Require zero configs by enabling features/optimizations by default.
Scope of V1
vLLM V1 introduces a comprehensive re-architecture of its core components, including the scheduler, KV cache manager, worker, sampler, and API server. However, it still shares a lot of code with vLLM V0, such as model implementations, GPU kernels, distributed control plane, and various utility functions. This approach allows V1 to leverage the extensive coverage and stability established by V0 while delivering significant enhancements to performance and code complexity.
What’s New in vLLM V1?
1. Optimized Execution Loop & API Server
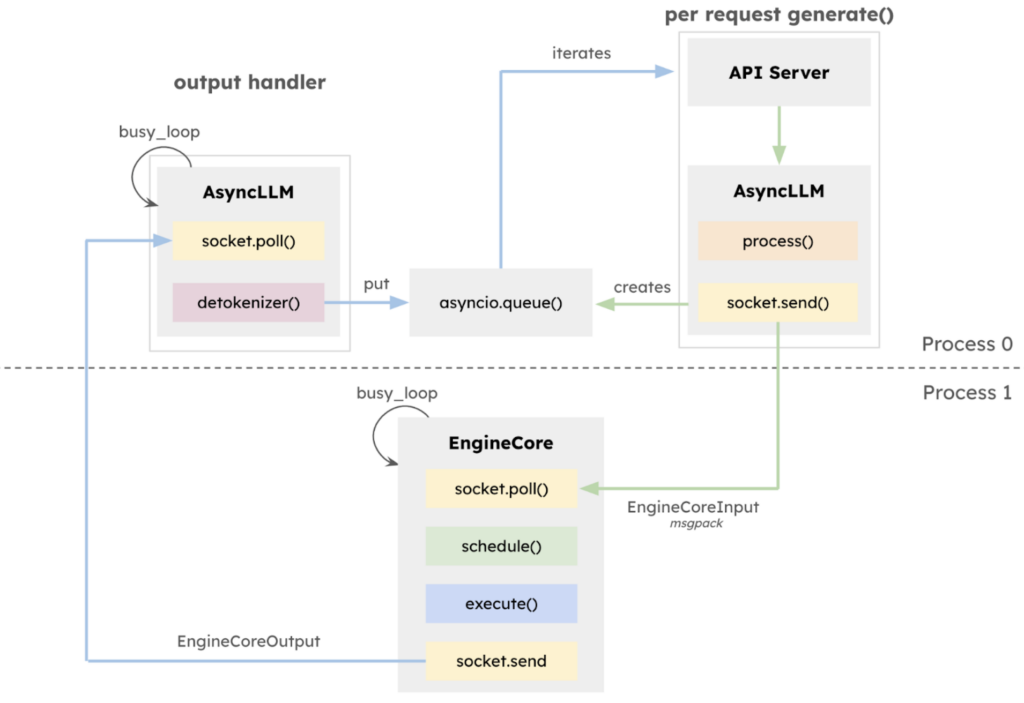
As a full-fledged continuous batching engine and OpenAI-compatible API server, vLLM’s core execution loop relies on CPU operations to manage request states between model forward passes. As GPUs are getting faster and significantly reducing model execution times, the CPU overhead for tasks like running the API server, scheduling work, preparing inputs, de-tokenizing outputs, and streaming responses to users becomes increasingly pronounced. This issue is particularly noticeable with smaller models like Llama-8B running on NVIDIA H100 GPUs, where execution time on the GPU is as low as ~5ms.
In the v0.6.0 release, vLLM introduced a multiprocessing API server utilizing ZeroMQ for IPC, enabling overlap between the API server and AsyncLLM. vLLM V1 extends this by integrating the multiprocessing architecture deeper into the core of AsyncLLM, creating an isolated EngineCore execution loop that focuses exclusively on the scheduler and model executor. This design allows for greater overlap of CPU-intensive tasks—such as tokenization, multimodal input processing, de-tokenization, and request streaming—with the core execution loop, thereby maximizing model throughput.
2. Simple & Flexible Scheduler
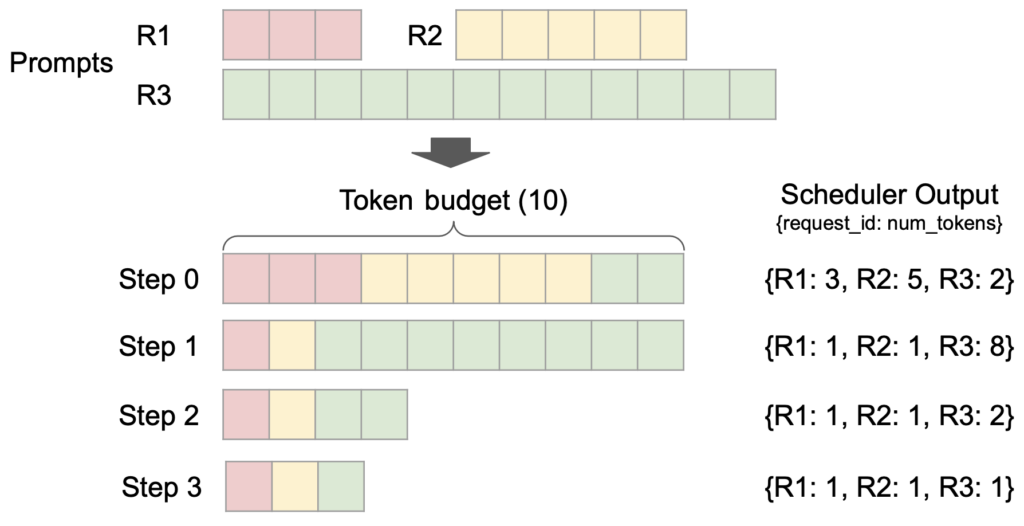
vLLM V1 introduces a simple yet flexible scheduler. It removes the traditional distinction between “prefill” and “decode” phases by treating user-given prompt tokens and model-generated output tokens uniformly. Scheduling decisions are represented as a simple dictionary, e.g., {request_id: num_tokens}, which specifies the number of tokens to process for each request at each step. We find that this representation is general enough to support features such as chunked prefills, prefix caching, and speculative decoding. For instance, chunked-prefill scheduling is seamlessly implemented: with a fixed token budget, the scheduler dynamically decides how many tokens to allocate to each request (as shown in the figure above).
3. Zero-Overhead Prefix Caching
vLLM V1, like V0, uses hash-based prefix caching and LRU-based cache eviction. In V0, enabling prefix caching sometimes causes significant CPU overhead, leading to rather decreased performance when the cache hit rate is low. As a result, it is disabled by default. In V1, we optimize the data structure for constant-time cache eviction and carefully minimize Python object creation overhead. This makes V1’s prefix caching introduce near-zero performance degradation, even when the cache hit rate is 0%.
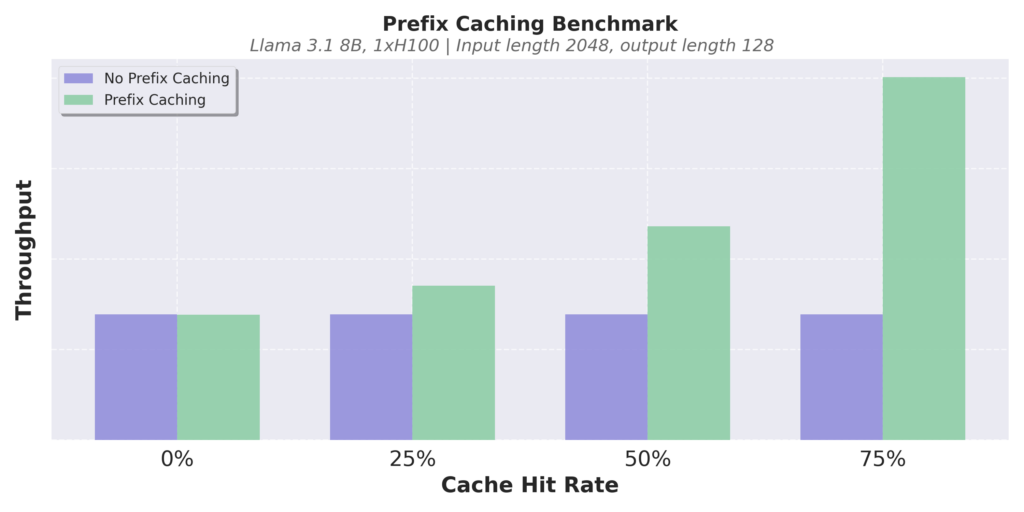
Here are some benchmark results. In our experiments, we observed that V1’s perfix caching causes less than 1% decrease in throughput even when the cache hit rate is 0%, while it improves the performance several times when the cache hit rate is high. Thanks to the near-zero overhead, we now enable prefix caching by default in V1.
4. Clean Architecture for Tensor-Parallel Inference
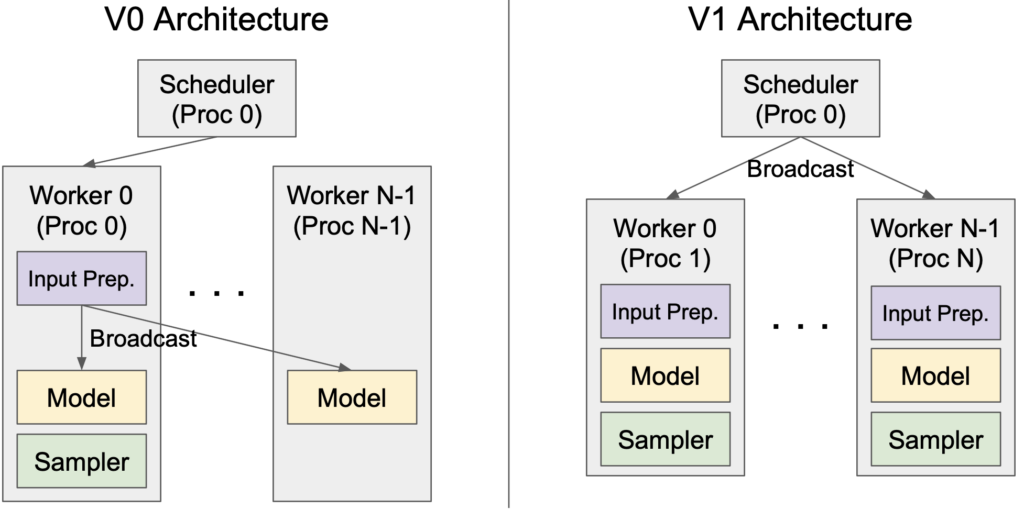
vLLM V1 introduces a clean and efficient architecture for tensor-parallel inference, effectively addressing the limitations of V0. In V0, the scheduler and Worker 0 are colocated within the same process to reduce the inter-process communication overhead when broadcasting input data to workers. However, this design introduces an asymmetric architecture, increasing complexity. V1 overcomes this by caching request states on the worker side and transmitting only incremental updates (diffs) at each step. This optimization minimizes inter-process communication, allowing the scheduler and Worker 0 to operate in separate processes, resulting in a clean, symmetric architecture. Moreover, V1 abstracts away most distributed logic, enabling workers to operate the same way for both single-GPU and multi-GPU setups.
5. Efficient Input Preparation

In vLLM V0, input tensors and metadata for the model are recreated at each step, often leading to significant CPU overhead. To optimize this, V1 implements the Persistent Batch technique, which caches the input tensors and only applies the diffs to them at each step. Additionally, V1 minimizes the CPU overheads in updating the tensors by extensively utilizing Numpy operations instead of Python’s native ones.
6. torch.compile and Piecewise CUDA Graphs

V1 leverages vLLM’s torch.compile integration to automatically optimize the model. This allows V1 to efficiently support a wide variety of models while minimizing the need of writing custom kernels. Furthermore, V1 introduces piecewise CUDA graphs to alleviate the limitations of CUDA graphs. We are preparing dedicated blog posts on the torch.compile integration and piecewise CUDA graphs, so stay tuned for more updates!
7. Enhanced Support for Multimodal LLMs
vLLM V1 treats multimodal large language models (MLLMs) as first-class citizens and introduces several key improvements in their support.
First, V1 optimizes multimodal input preprocessing by moving it to a non-blocking process. For example, image files (e.g., JPG or PNG) must be converted into tensors of pixel values, cropped, and transformed before being fed into the model. This preprocessing can consume significant CPU cycles, possibly leaving the GPU idle. To address this, V1 offloads the preprocessing task to a separate process, preventing it from blocking the GPU worker, and adds a preprocessing cache so that processed inputs can be reused across requests if they share the same multimodal input.
Second, V1 introduces prefix caching for multimodal inputs. In addition to the hash of token IDs, image hashes are used to identify the KV cache for image inputs. This improvement is especially beneficial for multi-turn conversations that include image inputs.
Third, V1 enables chunked-prefill scheduling for MLLMs with the “encoder cache.” In V0, image inputs and text inputs had to be processed in the same step because the LLM decoder’s token depends on the vision embeddings which are discarded after the step. With the encoder cache, V1 temporarily stores the vision embeddings, allowing the scheduler to split the text inputs into chunks and process them across multiple steps without needing to regenerate vision embeddings every step.
8. FlashAttention 3
The final piece of the puzzle for vLLM V1 was integrating FlashAttention 3. Given the high level of dynamism in V1—such as combining prefill and decode within the same batch—a flexible and high-performance attention kernel was essential. FlashAttention 3 effectively addresses this requirement, offering robust support for a wide range of features while maintaining excellent performance across diverse use cases.
Performance
Thanks to the extensive architectural enhancements, vLLM V1 achieves state-of-the-art throughput and latency, delivering up to 1.7x higher throughput compared to V0 (without multi-step scheduling). These dramatic performance gains stem from comprehensive CPU overhead reductions across the entire stack. The improvements are even more pronounced for vision-language models (VLMs) like Qwen2-VL, thanks to V1’s enhanced support for VLMs.
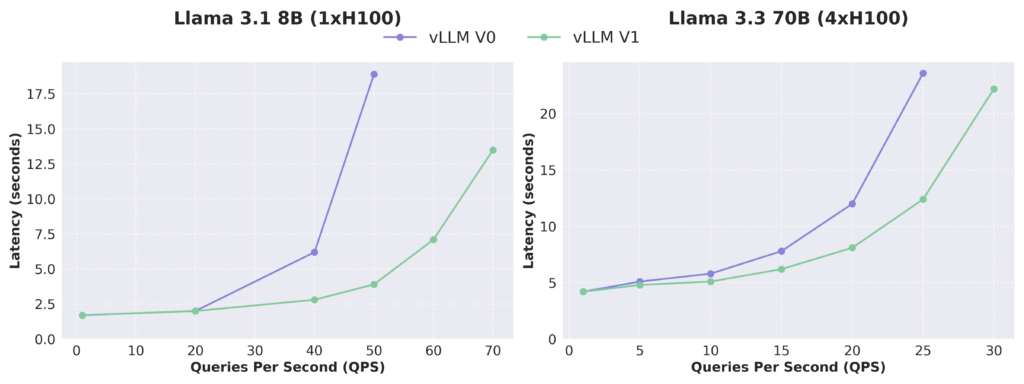
- Text Models: Llama 3.1 8B & Llama 3.3 70B
We measured the performance of vLLM V0 and V1 on Llama 3.1 8B and Llama 3.3 70B models using the ShareGPT dataset. V1 demonstrated consistently lower latency than V0 especially at high QPS, thanks to the higher throughput it achieves. Given that the kernels used for V0 and V1 are almost identical, the performance difference is mainly due to the architectural improvements (reduced CPU overheads) in V1.
- Vision-language Models: Qwen2-VL
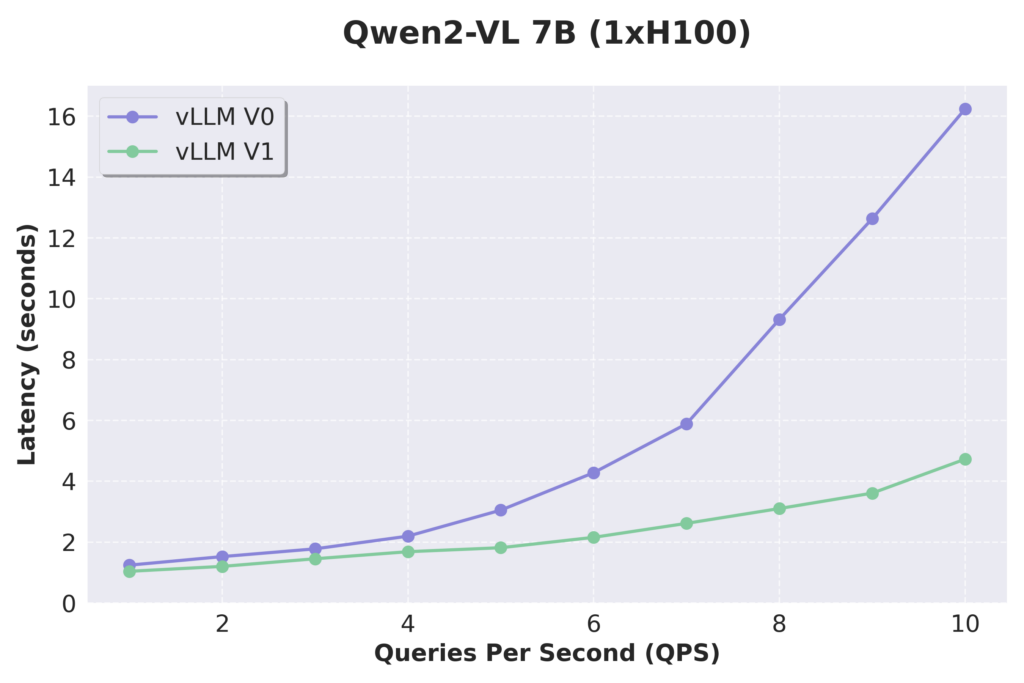
We evaluated the performance on VLMs by testing Qwen2-VL using the VisionArena dataset. V1 delivered even larger speedups over V0, thanks its improved VLM support, driven by two key improvements: offloading input processing to a separate process and implementing more flexible scheduling for multimodal queries. We would also like to point out that prefix caching is now natively supported for multimodal models in V1, but will skip the benchmark results here.
- Looking Forward
While these improvements are significant, we view them as just the beginning. The redesigned architecture provies a solid foundation that will enable rapid development of new features. We look forward to sharing additional enhancements in the coming weeks. Stay tuned for more updates!
Limitations & Future Work
While vLLM V1 shows promising results, it is still in its alpha stage and lacks several features from V0. Here’s a clarification:
Model Support:
V1 supports decoder-only Transformers like Llama, mixture-of-experts (MoE) models like Mixtral, and several VLMs such as Qwen2-VL. All quantization methods are supported. However, V1 currently does not support encoder-decoder architectures like multimodal Llama 3.2, Mamba-based models like Jamba, or embedding models. Please check out our documentation for a more detailed list of the supported models.
Feature Limitations:
V1 currently lacks support for log probs, prompt log probs sampling parameters, pipeline parallelism, structured decoding, speculative decoding, prometheus metrics, and LoRA. We are actively working to close this feature gap and add brand-new optimizations to the V1 engine.
Hardware Support:
V1 currently supports only Ampere or later NVIDIA GPUs. We are actively working to extend support to other hardware backends such as TPU.
Finally, please note that you can continue using V0 and maintain backward compatibility by not setting VLLM_USE_V1=1.
How to Get Started
To use vLLM V1:
- Install the latest version of vLLM with
pip install vllm --upgrade. - Set the environment variable
export VLLM_USE_V1=1. - Use vLLM’s Python API or OpenAI-compatible server (
vllm serve <model-name>). You don’t need any change to the existing API.
Please try it out and share your feedback!
Acknowledgment
We gratefully acknowledge that the design of vLLM V1 builds upon and enhances several open-source LLM inference engines, including LightLLM, LMDeploy, SGLang, TGI, and TRT-LLM. These engines have significantly influenced our work, and we have gained valuable insights from them.
The V1 re-architecture is a continued joint effort across the entire vLLM team and community. Below is an incomplete list of contributors to this milestone:
- UC Berkeley, Neural Magic (now Red Hat), Anyscale, and Roblox mainly drove the effort together.
- Woosuk Kwon initiated the project and implemented the scheduler and model runner.
- Robert Shaw implemented the optimized execution loop and API server.
- Cody Yu implemented efficient prefix caching for text and image inputs.
- Roger Wang led the overall enhanced MLLM support in V1.
- Kaichao You led the torch.compile integration and implemented the piecewise CUDA graphs.
- Tyler Michael Smith implemented the tensor parallelism support with Python multiprocessing.
- Rui Qiao implemented the tensor parallelism support with Ray and is implementing pipeline parallelism support.
- Lucas Wilkinson added support for FlashAttention 3.
- Alexander Matveev implemented the optimized preprocessor for multimodal inputs and is implementing TPU support.
- Sourashis Roy implemented the logit penalties in the sampler.
- Cyrus Leung led the MLLM input processing refactoring effort and helped its integration to V1.
- Russell Bryant addressed several multiprocess-related issues.
- Nick Hill optimized the engine loop and API server.
- Ricky Xu and Chen Zhang helped refactor the KV cache manager.
- Jie Li and Michael Goin helped with MLLM support and optimization.
- Aaron Pham is implementing the structured decoding support.
- Varun Sundar Rabindranath is implementing the multi-LoRA support.
- Andrew Feldman is implementing the log probs and prompt log probs support.
- Lily Liu is implementing the speculative decoding support.
- Kuntai Du is implementing the prefill disaggregation and KV Cache transfer support.
- Simon Mo and Zhuohan Li contributed to the V1 system design.






