

Jul 15, 2024

Author(s)




vLLM Now Supports FP8 on NVIDIA GPUs
vLLM, a leading open-source LLM serving engine, has taken a significant leap forward in its recent 0.5 release by incorporating FP8 quantization support. This cutting-edge format promises to revolutionize LLM deployment by dramatically improving efficiency without sacrificing model quality.
The implementation of FP8 support is the result of development efforts from Neural Magic and Anyscale. This integration allows vLLM to utilize specialized hardware units, such as the fourth-generation Tensor Cores on NVIDIA H100 and L40s GPUs, which are designed to accelerate matrix multiplication in FP8 precision.
With FP8, vLLM deployments may receive up to a 2x reduction in latency with minimal accuracy degradation.
This blog post explores the integration of FP8 in vLLM, its benefits, and what it means for the future of LLM inference.
What is FP8?
Traditionally, FP32 (32-bit floating point) and FP16 (16-bit floating point) have been the go-to formats for machine learning models. However, as LLMs grow larger and more complex, there's an increasing need for more efficient formats that can maintain accuracy while reducing computational and memory requirements.
FP8, or 8-bit floating point, is a modern quantization format that strikes a balance between precision and efficiency. It provides a non-uniform range representation and per-tensor scaling factors with hardware acceleration on modern GPUs, allowing for significant performance gains and 2x reduced memory usage without sacrificing model quality.
FP8 Performance in vLLM
Before diving into the performance gains, let’s briefly explain three crucial metrics for LLM serving:
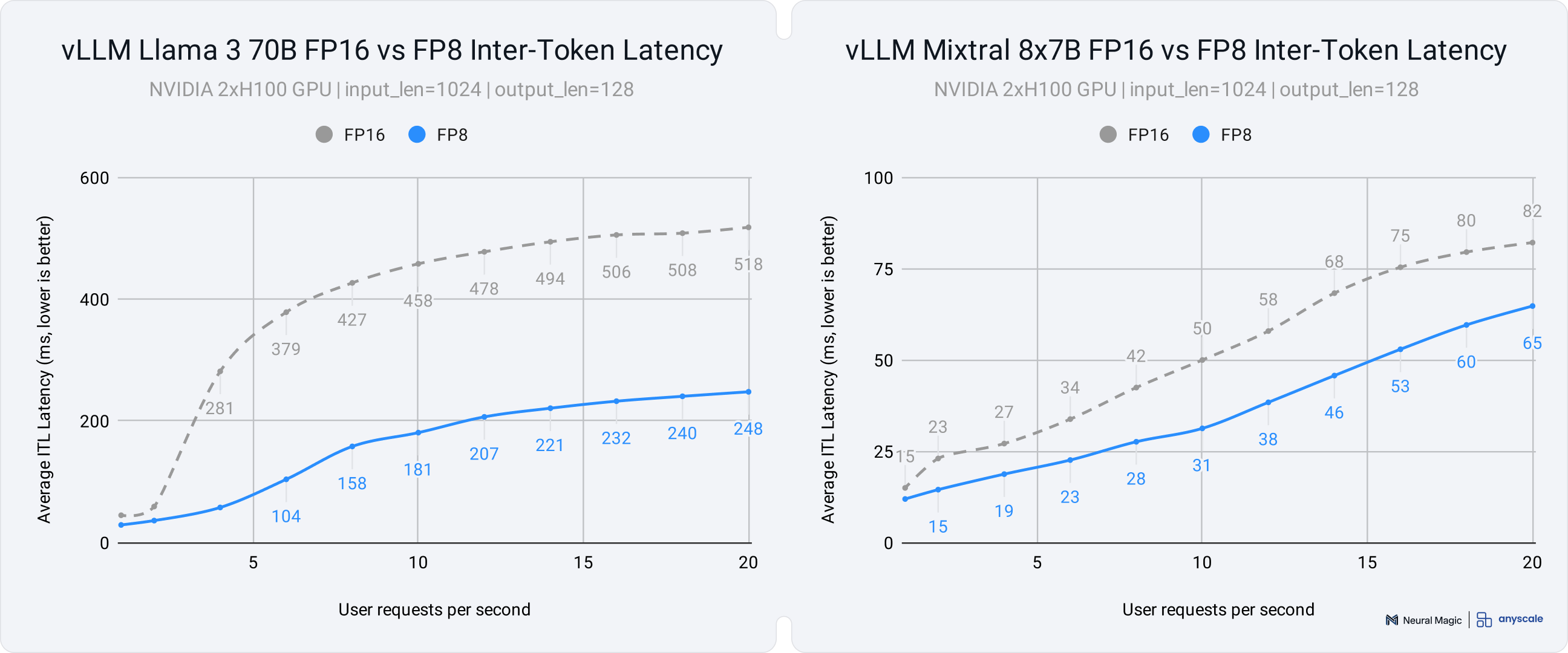
- Inter-Token Latency (ITL): The average time between generating each token in the output per user. Lower ITL means smoother, more responsive text generation.
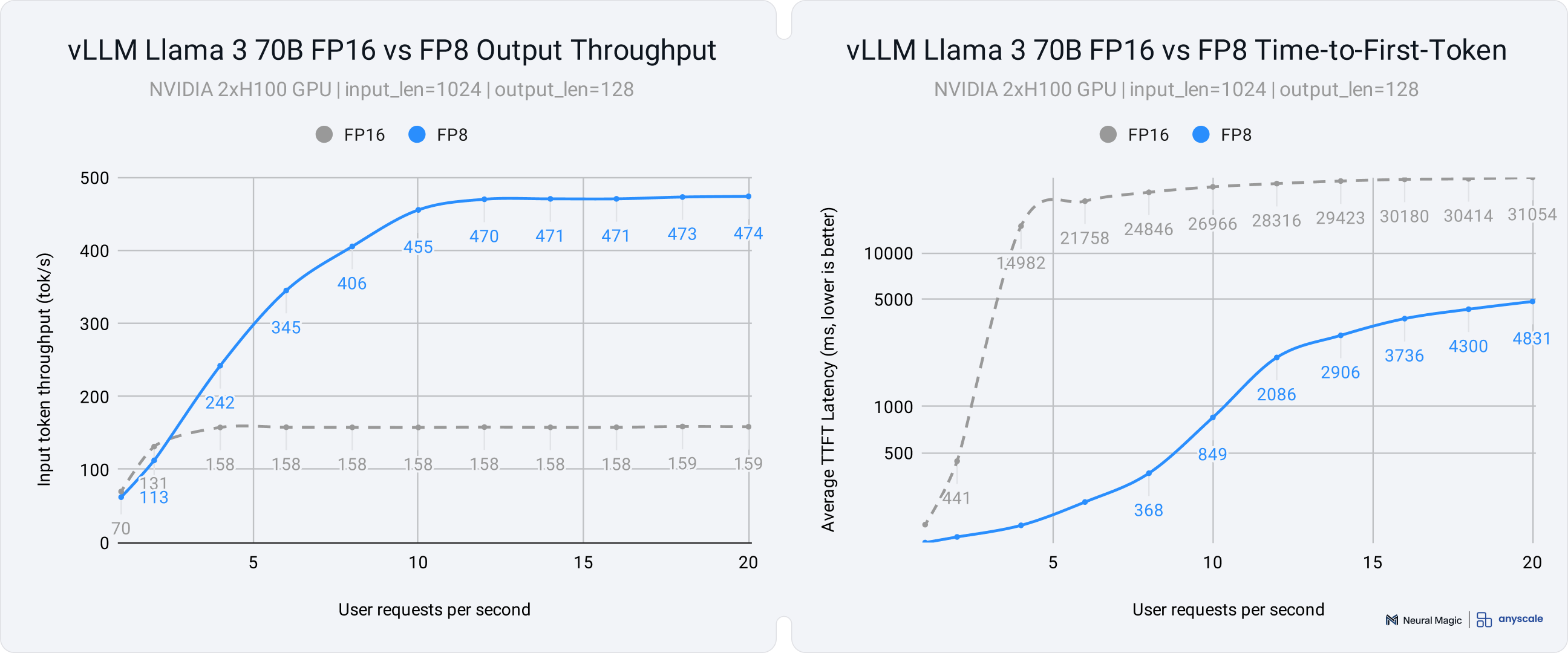
- Throughput: The number of output tokens per second an inference server can generate across all users and requests. Higher throughput allows for serving more requests simultaneously.
- Time-to-First-Token (TTFT): The time it takes for the model to generate the first token of the response after receiving the input prompt. Lower TTFT reduces the initial wait time for users.
These metrics are vital for assessing and optimizing the real-world performance of LLM serving systems, directly impacting user experience and system efficiency.
The integration of FP8 in vLLM has yielded impressive performance gains across various models and use cases:
- Up to 2x ITL improvement for serving dense models (Llama 3 70B)
- Up to 1.6x ITL improvement for serving Mixture of Experts (MoE) models (Mixtral 8x7B)
- Up to 3x throughput improvement in scenarios where the significant memory savings lead to increasing batch sizes.
Minimal Quality Degradation
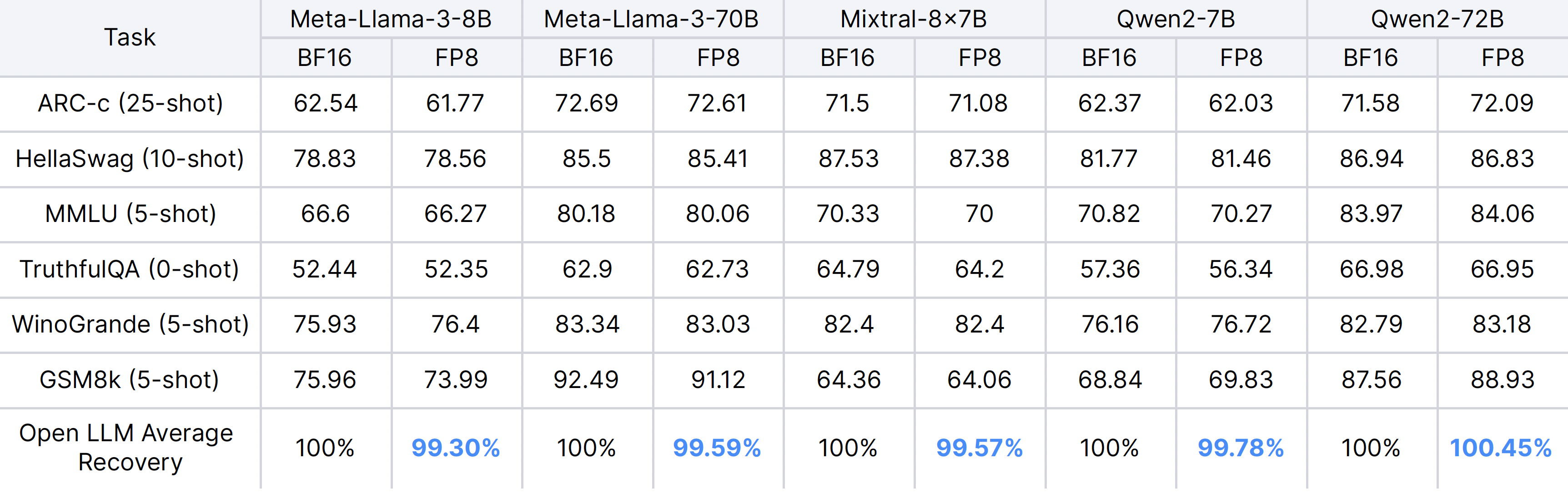
Accuracy preservation of FP8 in vLLM has been validated through lm-evaluation-harness comparisons on Open LLM Leaderboard v1 tasks. Most models experience over 99% accuracy preservation compared to the unquantized baseline.
FP8 Inference Quickstart
Try out FP8 support in vLLM immediately using a quantized FP8 checkpoint:
# pip install vllm==0.5.1
from vllm import LLM
model = LLM("neuralmagic/Meta-Llama-3-8B-Instruct-FP8")
result = model.generate("Hello, my name is")
There is also support for dynamic FP8 quantization for existing FP16/BF16 models within vLLM by specifying the quantization=”fp8” argument. Note that this will not provide the same performance uplift due to the dynamic scale calculations required.
from vllm import LLM
model = LLM("meta-llama/Meta-Llama-3-8B-Instruct", quantization="fp8")
result = model.generate("Hello, my name is")
For easy performant FP8 inference, Neural Magic has produced a growing list of accuracy-verified quantized FP8 checkpoints of popular LLMs ready to use with vLLM. You can reproduce these results or calibrate with your dataset using our open-source tool llm-compressor.
Overview of FP8 Architecture in vLLM
This section goes into detail over several key features of the FP8 architecture in vLLM, along with easy steps for you to get started adopting the features.
Performant FP8 Kernels
vLLM’s implementation of FP8 draws inspiration from PyTorch, initially adopting torch.float8_e4m3fn and torch._scaled_mm to enable runtime quantization of existing FP16/BF16 checkpoints. This straightforward approach allows users to enable FP8 quantization by simply specifying quantization="fp8". Building on this foundation, we extended FP8 support to (MoE) models, starting with a Mixtral implementation in Triton. Since then, we have significantly enhanced the FP8 implementation for performant inference:
- Utilization of static activation scales to reduce quantization overhead
- Development of custom CUTLASS kernels for FP8 matrix multiplication, surpassing PyTorch's FP8 performance
- Optimization of Triton and CUTLASS parameters for improved performance
These advancements collectively contribute to vLLM's state-of-the-art FP8 inference support.
Memory Reduction
FP8 quantization offers substantial memory benefits. Both weights and activations are stored more efficiently, occupying only half the space required by their original precision. This reduction in memory footprint allows for longer context lengths and accommodates more concurrent requests. Additionally, vLLM extended FP8 quantization to the KV Cache. By specifying kv_cache_dtype="fp8", users can further reduce the memory footprint of in-flight requests, potentially doubling the number of requests that can be processed simultaneously or allowing larger models to fit into GPU memory.
FP8 Checkpoint Compatibility
vLLM now supports direct ingestion of FP8 model checkpoints, streamlining the use of pre-quantized models. When creating FP8 checkpoints for your models, vLLM offers two approaches:
- Static per-tensor scales for weights with dynamic per-tensor scales for activations
- Pros: Easy to use
- Cons: Sub-optimal performance due to cost of scale calculation
- Static per-tensor scales for both weights and activations
- Pros: Optimal performance
- Cons: Requires a calibration step
The following table illustrates the structure of an FP8 checkpoint, using the neuralmagic/Mixtral-8x7B-Instruct-v0.1-FP8 model as an example:

For optimal inference performance, we recommend using llm-compressor or AutoFP8 with relevant calibration data to generate appropriate per-tensor static scales for both weights and activations. Here's a step-by-step guide to quantize your model using AutoFP8:
# pip install git+https://github.com/neuralmagic/AutoFP8.git
from datasets import load_dataset
from transformers import AutoTokenizer
from auto_fp8 import AutoFP8ForCausalLM, BaseQuantizeConfig
# Load and tokenize 2048 dataset samples for calibration of activation scales
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct", use_fast=True)
tokenizer.pad_token = tokenizer.eos_token
ds = load_dataset("neuralmagic/ultrachat_2k", split="train_sft").select(range(2048))
examples = [tokenizer.apply_chat_template(batch["messages"], tokenize=False) for batch in ds]
examples = tokenizer(examples, padding=True, truncation=True, return_tensors="pt").to("cuda")
# Define quantization config with static activation scales
quantize_config = BaseQuantizeConfig(quant_method="fp8", activation_scheme="static")
# Load the model, quantize, and save checkpoint
model = AutoFP8ForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct", quantize_config)
model.quantize(examples)
model.save_quantized("Meta-Llama-3-8B-Instruct-FP8/")
After executing this script, your quantized model checkpoint will be available at Meta-Llama-3-8B-Instruct-FP8/. You can then load this checkpoint directly in vLLM:
from vllm import LLM
model = LLM(model="Meta-Llama-3-8B-Instruct-FP8/")
result = model.generate("Hello, my name is")
For a more comprehensive understanding of FP8 in vLLM, please read our documentation on FP8 here.
The Future of FP8 in vLLM
The integration of FP8 in vLLM is a great step forward, and is just the beginning. The development team is actively working on several exciting enhancements:
- More Advanced Quantization: Through the recent integration of llm-compressor, we will be applying more advanced quantization techniques like SmoothQuant and GPTQ from integer quantization methods to reduce outliers and preserve accuracy. Development is ongoing to support scaling factors of a finer granularity (e.g., per-channel, per-token), which will further improve quantization accuracy. We will also be pushing for INT8 W8A8 quantization to provide similar performance benefits on hardware without support for FP8, such as A100 GPUs.
- FP8 Attention: We will extend FP8 computation to the attention mechanism as well by leveraging kernels from FlashInfer, greatly improving performance at large context lengths.
- Expanded MoE FP8 Support: While FP8 support for Mixture of Experts (MoE) models like Mixtral is already available, work is in progress to extend this support to a broader range of MoE architectures like Qwen2 and DeepSeek-V2.
- Operation Fusion: We are exploring ways to fuse linear layers with surrounding operations to reduce the impact of quantization and dequantization. This is primarily focused on utilizing
torch.compilewith custom passes for layer fusion.
As these features progress, we can expect vLLM to continue pushing the boundaries of LLM inference efficiency, making advanced AI models more accessible and deployable in a wide range of applications.
If you are interested in helping these developments, please join the bi-weekly vLLM Open Office Hours where you can ask questions, meet the community, and learn how to contribute!






