

Mar 14, 2023

Author(s)

Training time is a well-known problem when training computer vision networks such as image classification models. The problem is aggravated by the fact that image data and models are large, therefore requiring a lot of computational resources. Traditionally, these problems have been solved using powerful GPUs to load the data faster. Unfortunately, these GPUs are expensive, making the solution uneconomical for some organizations. This calls for a new set of solutions.
Deep Lake by Activeloop is a data lake for deep learning that stores data of various modalities (e.g., text, audio, video, images, etc.) in an optimized format for deep learning leading to fast loading when training models. The Deep Lake dataset format is optimized for rapid streaming and dataset querying when training models at scale. It compresses the data in their native form and decompresses them when needed, for example, during training. Deep Lake operates lazily; hence data is not loaded into memory. It also supports dataset version control and provides data loaders for popular deep learning frameworks. With the help of the streaming feature, users can also visualize their machine learning datasets with all the metadata right from their browser in Deep Lake UI.
One of the problems that Deep Lake addresses is loading datasets fast during training (in fact, it's the most performant dataloader for PyTorch in various cases). You still need to tackle the challenge of large models that are slow at inference. SparseML solves this problem by decreasing the models' size while maintaining accuracy. SparseML provides tools for applying state-of-the-art sparsification algorithms and quantization frameworks while training neural networks, leading to fast inference. You can sparsify deep learning models in a few lines of code using SparseML’s pre-configured pipelines.
Using Deep Lake leads to fast data loading when training models with SparseML. As a result, you can sparsify models 2 times faster than using normal PyTorch data loaders. In this article, you will learn how to use Deep Lake and SparseML to sparsify a ResNet-50 image classification model.
Ingest Training Data With Deep Lake
Deep Lake community has 250+ publicly available machine learning datasets like COCO, Imagenet, MNIST, or FFHQ that you can stream with one line of code. For this tutorial, however, we will use the plant disease recognition dataset to build a ResNet50 model to classify the type of disease given a plant’s leaf.
First, install deeplake and sparseml.
pip install deeplake sparseml[torch]Next, download the dataset from Kaggle and unzip it.
kaggle datasets download -d rashikrahmanpritom/plant-disease-recognition-dataset
unzip plant-disease-recognition-dataset.zipDefine a function to load the dataset using Deep Lake. Specify htype for optimizing the performance by defining the structure of the data.
def ingest_random(src, dest, overwrite = False, token = None):
# Find the subfolders, but filter additional files like DS_Store that are added on Mac machines.
class_names = [item for item in os.listdir(src) if os.path.isdir(os.path.join(src, item))]
files_list = []
for dirpath, dirnames, filenames in os.walk(src):
for filename in filenames:
files_list.append(os.path.join(dirpath, filename))
random.shuffle(files_list)
ds = deeplake.empty(dest, overwrite = overwrite, token = token) with ds:
# Create the tensors with names of your choice.
ds.create_tensor('images', htype = 'image', sample_compression = 'jpeg')
ds.create_tensor('labels', htype = 'class_label', class_names = class_names)
for file in tqdm(files_list):
label_text = os.path.basename(os.path.dirname(file))
label_num = class_names.index(label_text)
#Append data to the tensors
ds.append({'images': deeplake.read(file), 'labels': np.uint32(label_num)})
return ds
Create a Deep Lake dataset using the above function. Running the function creates a Deep Lake dataset in the plant_disease folder.
import deeplake
import os
import numpy as np
import random
from tqdm import tqdm
token="YOUR_ACTIVELOOP_TOKEN"
src = 'Train/Train'
dest = 'plant_disease'
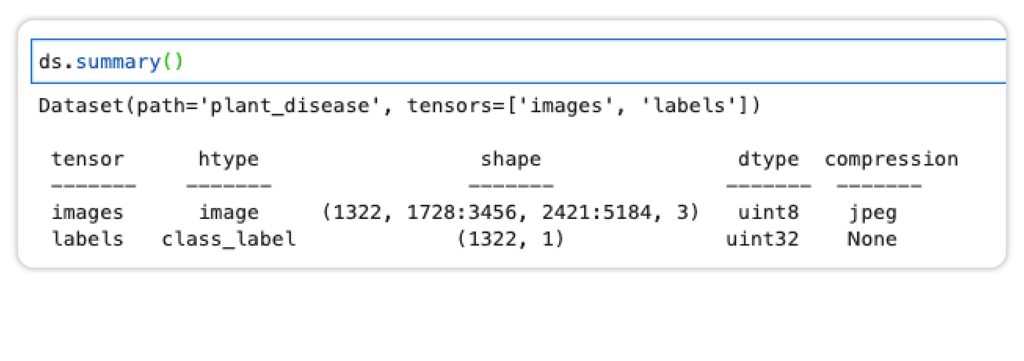
ds = ingest_random(src, dest, token=token)The dataset summary should look like the one shown below.
Perform Image Transformation
The next step is to process the image data in the format expected by the model. For instance, the ResNet model expects the data to have certain statistics. In this processing step, we:
- Convert the data to Pillow images
- Crop the images
- Perform simple data augmentation by flipping and rotating the images
- Convert the data to PyTorch tensors
- Normalize the tensors with the required mean and standard deviation
from torchvision import transforms
from torchvision.transforms.functional import InterpolationMode
tform = transforms.Compose([
transforms.RandomResizedCrop(224, interpolation=interpolation),
transforms.RandomRotation(20), # Image augmentation
transforms.RandomHorizontalFlip(p=0.5), # Image augmentation
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])Load Training Data
With the preprocessing steps in place, the next step is to load the data with PyTorch. This is done by converting the Deep Lake dataset into a PyTorch data loader using the pytorch function while passing the transformations defined earlier.
train_loader = ds.pytorch(
return_index=False,
shuffle=True,
transform={
deeplake_image_column: tform,
deeplake_label_column: None,
},
batch_size=batch_size,
decode_method={deeplake_image_column: "pil"},
)Create ResNet Model
The objective is to fine-tune and sparsify a pre-trained ResNet model on the custom dataset.
Create the ResNet model and move it to the GPU for fast training.
from sparseml.pytorch.models import resnet50
NUM_CLASSES = len(ds[deeplake_label_column].info.class_names)
model = resnet50(pretrained=True, num_classes=NUM_CLASSES)
# Device setup
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)Integrate SparseML
Sparsifying a custom model is done by providing a sparsification recipe that contains instructions on how the sparsification should be done. This recipe is usually a YAML file. The recipe can be custom or provided by SparseZoo.
The configuration in the recipe is injected into the training process using the ScheduledModifierManager, which expects the:
- Model to be modified
- Model’s optimizer
steps_per_epochto ensure the recipe is applied at the right time
The integration is shown in the code below:
- Import
ScheduledModifierManagerfrom SparseML - Create an instance of
ScheduledModifierManagerwith a recipe from SparseZoo - Modify the optimizer and the model using the
ScheduledModifierManagerto ensure the recipe is applied during training
from sparseml.pytorch.optim import ScheduledModifierManager
from torch.optim import SGD
recipe_path = "zoo:cv/classification/resnet_v1-50/pytorch/sparseml/imagenet/pruned95_quant-none?recipe_type=original"
optimizer = SGD(model.parameters(), lr=10e-6, momentum=0.9)
manager = ScheduledModifierManager.from_yaml(recipe_path)
optimizer = manager.modify(model, optimizer, steps_per_epoch=len(train_loader))This is the recipe used in the code above.
modifiers:
- !GlobalMagnitudePruningModifier
init_sparsity: 0.05
final_sparsity: 0.8
start_epoch: 0.0
end_epoch: 30.0
update_frequency: 1.0
params: __ALL_PRUNABLE__
- !SetLearningRateModifier
start_epoch: 0.0
learning_rate: 0.05
- !LearningRateFunctionModifier
start_epoch: 30.0
end_epoch: 50.0
lr_func: cosine
init_lr: 0.05
final_lr: 0.001
- !QuantizationModifier
start_epoch: 50.0
freeze_bn_stats_epoch: 53.0
- !SetLearningRateModifier
start_epoch: 50.0
learning_rate: 10e-6
- !EpochRangeModifier
start_epoch: 0.0
end_epoch: 55.0The recipe does pruning and quantization as follows:
GlobalMagnitudePruningModifierperforms gradual magnitude pruning on all the prunable weights starting at 5% from epoch 0 up to 80% at epoch 30LearningRateFunctionModifiercycles the fine-tuning learning rate from the pruning learning rate to 0.001 with a cosine curveEpochRangeModifierextends the training time to continue fine-tuning for an additional 20 epochs after pruning has endedQuantizationModifierapplies quantization-aware training from epoch 50 and freezes batch normalization statistics at the start of epoch 53SetLearningRateModifiersets the quantization learning rate to 10e-6EpochRangeModifiersets the training time to continue training for 55 epochs
Train ResNet Model
You are set to perform the normal training loop in PyTorch.
Calling finalize after training releases the resources used during training.
from torch.nn import CrossEntropyLoss
# Training Loop
start_time = time.perf_counter()
# Loss setup
criterion = CrossEntropyLoss()
for epoch in range(30):
running_loss = 0.0
running_corrects = 0.0
for inputs, labels in train_loader:
labels = torch.squeeze(labels)
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(True):
outputs, _ = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(train_loader.dataset)
epoch_acc = running_corrects.double() / len(train_loader.dataset)
print("Epoch {}: Training Loss: {:.4f} Acc: {:.4f}".format(epoch, epoch_loss, epoch_acc))
end_time = time.perf_counter()
duration = (end_time-start_time) * 1000.0
print(f"Sparse Deeplake Pipeline Took: {duration:.4f} ms")
manager.finalize(model)
Sparsying the model with the Deep Lake data loader is 2 times faster than training the ResNet model with the normal PyTorch data loader.
Deploy ResNet Model With DeepSparse
When training is complete, export and deploy the model using DeepSparse. DeepSparse is an inference runtime that offers GPU-class performance on commodity CPUs. Use the ModuleExporter utility from SparseML to export the model to ONNX.
import torch
import os
dummy_input = torch.randn(1, 3, 224, 224)
from sparseml.pytorch.utils import ModuleExporter
exporter = ModuleExporter(model, output_dir=os.path.join(".", "."))
exporter.export_onnx(sample_batch=dummy_input)Next, create an image classification pipeline using DeepSparse and define the exported ONNX as the path to the mode. Run inference on this model by passing images to the DeepSparse Pipeline.
from deepsparse import Pipeline
cv_pipeline = Pipeline.create(
task="image_classification",
model_path="model.onnx", # Path to checkpoint or SparseZoo stub
class_names=None # optional dict / json mapping class ids to labels (if not using ImageNet classes)
)
input_image = "10007.jpg" # path to input image
inference = cv_pipeline(images=input_image)
inference
# ImageClassificationOutput(labels=[2], scores=[7.409341335296631])Train SparseML Models With Any Dataloader
You have seen how to use Deep Lake data loaders to sparsify a model using SparseML. SparseML doesn’t limit you to specific data loaders. You can use any data loader as long as it generates a PyTorch data loader.
Since SparseML is open source, modify the data loading part of the code to use the data loader of your choice.
Final Thoughts
Loading machine learning datasets using Deep Lake when sparsifying deep learning models reduces the training time by half. You have built small models faster by using these two open-source libraries. You’ve also seen how to integrate other data loaders with SparseML.
Ultimately, you saw how to deploy the resulting model for fast inference using DeepSparse.
Are you interested in pruning and quantizing deep learning models for fast inference? Join our community to interact with other deep learning practitioners and get your questions answered.






