
Dec 17, 2024

Author(s)

Neural Magic is excited to introduce Neural Magic Compress, a developer subscription designed to help enterprises deploy efficient Generative AI (GenAI) models faster, cheaper, and at scale. Built on our open-source foundation, Neural Magic Compress offers access to state-of-the-art compressed models, detailed performance benchmarks, comprehensive evaluations, and dedicated enterprise support—everything you need to optimize costs, accelerate time-to-production, and easily scale AI solutions.
From chatbots and code generation to large-scale data extractions, Neural Magic Compress empowers enterprises to achieve unmatched efficiency and top-tier accuracy—leveraging open-source AI solutions to help you own your data, cut costs, and ensure long-term maintainability.
Real-World Deployment Challenges
Deploying Generative AI (GenAI) models at enterprise scale presents significant hurdles that slow adoption, drive up costs, and delay time-to-production:
- High Infrastructure Costs: GenAI models demand substantial computational resources, significantly driving up deployment expenses and compute requirements, particularly at enterprise scale.
- Slow Response Times: The large size and auto-regressive nature of GenAI models result in slow responses without considerable infrastructure investment.
- Accuracy vs. Efficiency Trade-Offs: Achieving high accuracy with GenAI models necessitates larger sizes, leading to increased costs and reduced deployment efficiency.
Balancing performance, cost, and accuracy while managing complex compression workflows creates long development cycles and failed projects. Neural Magic Compress solves these challenges by simplifying the process and identifying accurate, deployable models from the start.
What is Neural Magic Compress?
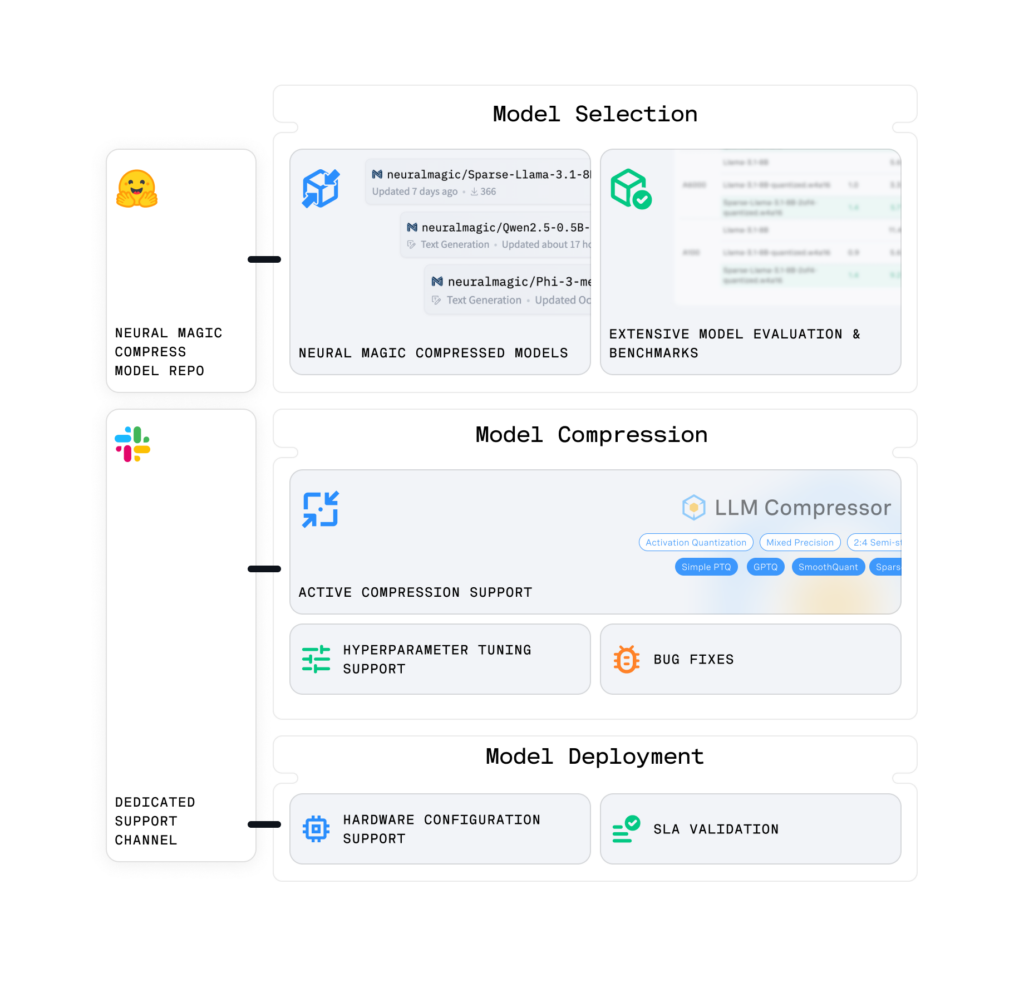
Neural Magic’s open-source tools and research provide the perfect starting point for exploring AI model compression. The Neural Magic Compress subscription builds on this foundation, offering enterprises advanced features like:
- Compressed Model Repo: Access a private library of expertly compressed models, including quantized, sparse, and PEFT-ready models, optimized for accuracy recovery, diverse hardware performance, and seamless enterprise integration.
- Comprehensive Benchmarks: Gain actionable insights with hardware-specific benchmarks and cost analysis, enabling confident decisions on model selection, deployment configurations, and resource optimization.
- Real-World Evaluations: Review detailed evaluations across diverse metrics, ensuring models align with enterprise use cases and meet accuracy and performance requirements.
- Detailed Research Reports: Access exclusive research reports, hyperparameter sweeps, and whitepapers detailing cutting-edge model compression and fine-tuning techniques.
- Expert Guidance: Receive expert guidance on hyperparameter tuning, fine-tuning workflows, and model compression to ensure optimal performance.
- Enterprise Support: Leverage hands-on support for LLM Compressor integration, bug fixes, feature requests, and deployment enablement for seamless pipeline adoption.
Combining these features, Neural Magic Compress bridges the gap between cutting-edge research and real-world GenAI deployments, giving enterprise developers the tools to achieve unparalleled efficiency.
Compression in Action
Neural Magic Compress is already driving tangible results for enterprises across industries, helping them easily overcome the challenges of GenAI deployment. Here are two examples that showcase its impact:
Gaming: Hundreds of Thousands of Daily Code Generations
- Challenge: The baseline Llama 70B model required two 8xA100 systems to meet demanding performance requirements (10 QPS @ 50ms TPOT), leading to high infrastructure costs and inefficiencies.
- Solution: By deploying Neural Magic’s INT8 quantized Llama 70B, the gaming company reduced GPU usage by half while maintaining performance and accuracy standards, significantly cutting costs and boosting efficiency.
Retail: Millions of Daily JSON Extractions
- Challenge: Retail operations struggled to deploy the baseline Llama 70B model effectively due to minimal performance gains from existing quantization approaches on their hardware.
- Solution: Neural Magic engineers collaborated with the retailer to apply hardware-compatible and accurate quantization techniques, enabling a 40% reduction in GPU hours with full accuracy recovery.
Learn More and Get Started
Ready to optimize your GenAI deployments? Connect with us to explore how the Neural Magic Compressor offering can transform your AI journey with speed, efficiency, and faster time-to-market. Contact our team today and discover the tools, models, and support you need to succeed.






