

Feb 17, 2025

Author(s)




The Compressed Summary
- LLM Compressor (v0.4.0) now supports multimodal model quantization, enabling efficient compression of vision-language and audio models with the most popular quantization formats.
- GPTQ, our most popular algorithm, is fully extended and tested with complex multi-modal architectures, including Whisper and Llama 3.2 Vision.
- Examples and evaluations confirm the expected high recoverability, with >99% across some quick samples while reducing memory and compute requirements.
- Seamless integration with vLLM, powering faster, scalable, and more cost-effective for real-world deployments.
Productized Model Compression
LLM Compressor is an open-source library that productizes the latest research in model compression, enabling easy generation of compressed models with minimal effort. The LLM Compressor framework allows users to apply state-of-the-art research across quantization, sparsity, and general compression techniques to improve generative AI models' efficiency, scalability, and performance while maintaining accuracy. With native Hugging Face and vLLM support, optimized models can seamlessly integrate with deployment pipelines for faster, cost-saving inference at scale, powered by the compressed-tensors model format.
Designed for flexibility, LLM Compressor supports both post-training and training workflows for compression through Modifiers, implementations that apply a specific compression method to a given model. Modifier implementations cover a wide range of compression algorithms and techniques, including:
- Weight-only quantization (W4A16) for limited hardware or latency-sensitive applications.
- Weight and activation quantization (W8A8) targeting general server scenarios for both integer and floating point formats.
- 2:4 semi-structured sparsity for further inference acceleration.
With the v0.4.0 release, LLM Compressor adds general support for multimodal models, including vision and audio, and extends GPTQ-based quantization for performant support. The following sections explore these enhancements, their usage, and examples to quantize your own models.
Multimodal Enablement
LLM Compressor and the GPTQModifier have been expanded to accommodate performant multimodal model compression, enabling SOTA quantization for vision and audio models while maintaining accuracy. This enhancement allows architectures like Whisper and Llama 3.2 Vision to benefit from quantization, making them more efficient for deployment with vLLM.
The GPTQ algorithm, as described in the original paper, applies quantization sequentially to each model layer, using the quantized outputs of the previous layer as inputs to the next. This approach propagates and compensates for quantization-induced errors, improving accuracy recovery while minimizing memory usage – particularly important as each layer requires a large Hessian matrix to calculate and adjust for errors. While this process is trivial for most decoder-only transformer architectures, identifying the layers and data flow for more complex, multimodal architectures requires a generalized and flexible approach. For example, Whisper’s audio encoder feeds features into each text decoder layer; this data passing must be accounted for to faithfully calibrate the model while minimizing the number of resources to do so.
To address this, the GPTQModifier now integrates tracing, a technique that records a model’s execution to capture its computational graph, which can then be partitioned into layers. This enables the calibration and quantization of layers sequentially belonging to arbitrary model architectures, such as vision-language, audio, and other multimodal models. By applying quantization in a structured, automated way, LLM Compressor simplifies the process of complicated research flows into a productized framework for both enterprise and developer use cases.
While tracing works for most models and datasets out of the box, some may require minor adjustments to ensure compatibility. If you encounter issues, refer to the model tracing guide for tips on modifying your model definition.
Validated Accuracy
With the latest enhancements to LLM Compressor, several multimodal models were quantized and evaluated across core benchmarks to assess performance and accuracy retention. Llama 3.2 11B and 90B Vision models were evaluated using mistral-evals on the MMMU task with vLLM, demonstrating >99% accuracy recovery as seen in Table 1. Similarly, Whisper Large V2 was quantized and evaluated on a sample from the LibriSpeech dataset using Word Error Rate (WER). As shown in Table 2, the compressed version maintains >99% recovery while significantly reducing the memory requirements.
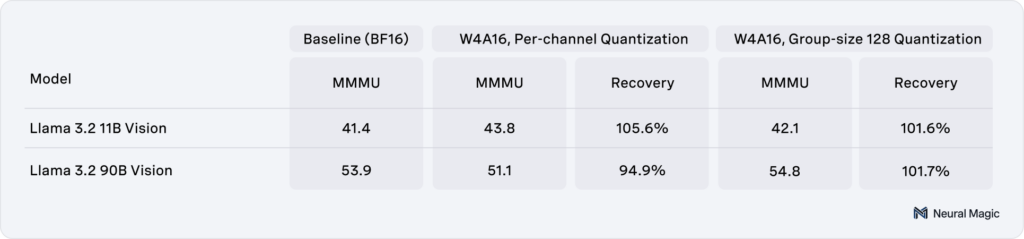
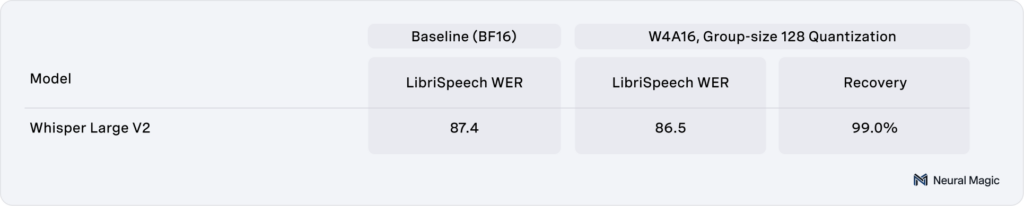
Table 2: LibriSpeech evaluation results for Whisper Large V2, comparing dense and quantized versions.
Hands-On Quantization
In the following sections, we will review some step-by-step examples of how to apply GPTQ quantization to your own models using LLM Compressor. These examples demonstrate real-world applications of multimodal compression, covering vision-language models (Llama 3.2 Vision) and audio models (Whisper Large V2). A complete list of other available examples can be found in the LLM Compressor examples folder. Additionally, for more examples of running multi-modal models with vLLM, see the provided offline inference examples
Environment Enablement
Before running any of the following sections, ensure you have installed LLM Compressor from PyPi on a compatible environment.
pip install llmcompressor>=0.4.0
Quantizing Vision Language Models
We will use the Llama3.2 vision model to demonstrate the support of multimodal vision architecture.
First, we load the model. The Llama3.2 vision model architecture requires loading from a custom `TraceableMllamaForConditionalGeneration` class which makes minor modifications to the original class definition to support tracing with the GPTQModifier.
import requests
import torch
from PIL import Image
from transformers import AutoProcessor
from llmcompressor.modifiers.quantization import GPTQModifier
from llmcompressor.transformers import oneshot
from llmcompressor.transformers.tracing import TraceableMllamaForConditionalGeneration
# Load model.
model_id = "meta-llama/Llama-3.2-11B-Vision-Instruct"
model = TraceableMllamaForConditionalGeneration.from_pretrained(
model_id, device_map="auto", torch_dtype="auto"
)
processor = AutoProcessor.from_pretrained(model_id)
Next, we define our calibration dataset and data collator. For this example, we will use the “flickr30k” dataset, which contains many scenes and images of objects. You can customize the calibration dataset to reflect your use case.
# Oneshot arguments
DATASET_ID = "flickr30k"
DATASET_SPLIT = {"calibration": "test[:512]"}
NUM_CALIBRATION_SAMPLES = 512
MAX_SEQUENCE_LENGTH = 2048
# Define a oneshot data collator for multimodal inputs
def data_collator(batch):
assert len(batch) == 1
return {key: torch.tensor(value) for key, value in batch[0].items()}
Now, we can apply one-shot recipe to quantize our model. In this case, we use GPTQ to apply the weight and activation quantization, as shown in the recipe below. Due to their small size and limited support for quantized acceleration, we ignore the vision model parameters in our recipe.
# Recipe
recipe = GPTQModifier(
targets="Linear",
scheme="W4A16",
ignore=["re:.*lm_head", "re:multi_modal_projector.*", "re:vision_model.*"],
)
# Perform oneshot
oneshot(
model=model,
tokenizer=model_id,
dataset=DATASET_ID,
splits=DATASET_SPLIT,
recipe=recipe,
max_seq_length=MAX_SEQUENCE_LENGTH,
num_calibration_samples=NUM_CALIBRATION_SAMPLES,
trust_remote_code_model=True,
data_collator=data_collator,
)
# Save to disk compressed.
SAVE_DIR = model_id.split("/")[1] + "-W4A16-G128"
model.save_pretrained(SAVE_DIR, save_compressed=True)
processor.save_pretrained(SAVE_DIR)
Finally, the model can now be deployed with vLLM for better inference performance:
from transformers import AutoProcessor
from vllm.assets.image import ImageAsset
from vllm import LLM, SamplingParams
# prepare model
model_id = "Llama-3.2-11B-Vision-Instruct-quantized.w4a16"
llm = LLM(
model=model_id,
max_model_len=4096,
max_num_seqs=16,
limit_mm_per_prompt={"image": 1},
)
processor = AutoProcessor.from_pretrained(model_id)
# prepare inputs
question = "What is the content of this image?"
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": f"{question}"},
],
},
]
prompt = processor.apply_chat_template(
messages, add_generation_prompt=True,tokenize=False
)
image = ImageAsset("cherry_blossom").pil_image.convert("RGB")
inputs = {
"prompt": prompt,
"multi_modal_data": {
"image": image
},
}
# generate response
print("========== SAMPLE GENERATION ==============")
outputs = llm.generate(inputs, SamplingParams(temperature=0.2, max_tokens=64))
print(f"PROMPT : {outputs[0].prompt}")
print(f"RESPONSE: {outputs[0].outputs[0].text}")
print("==========================================")
Quantizing Audio Models
We will use the Whisper Large V2 model to demonstrate multimodal audio architecture support.
First, we load the model. The whisper architecture requires loading from a custom `TraceableWhisperForConditionalGeneration` class, which makes minor modifications to the original class definition to support tracing with the GPTQModifier.
import torch
from datasets import load_dataset
from transformers import WhisperProcessor
from llmcompressor.modifiers.quantization import GPTQModifier
from llmcompressor.transformers import oneshot
from llmcompressor.transformers.tracing import TraceableWhisperForConditionalGeneration
# Select model and load it.
model_id = "openai/whisper-large-v2"
model = TraceableWhisperForConditionalGeneration.from_pretrained(
model_id,
device_map="auto",
torch_dtype="auto",
)
processor = WhisperProcessor.from_pretrained(model_id)
Next, we load and tokenize a calibration dataset. For this example, we will use the “MLCommons/peoples_speech” dataset, which contains many audio samples and labels. You can customize the calibration dataset to reflect your use case.
# Configure processor the dataset task.
processor.tokenizer.set_prefix_tokens(language="en", task="transcribe")
# Select calibration dataset.
DATASET_ID = "MLCommons/peoples_speech"
DATASET_SUBSET = "test"
DATASET_SPLIT = "test"
# Select number of samples. 512 samples is a good place to start.
# Increasing the number of samples can improve accuracy.
NUM_CALIBRATION_SAMPLES = 512
MAX_SEQUENCE_LENGTH = 2048
# Load dataset and preprocess.
ds = load_dataset(
DATASET_ID,
DATASET_SUBSET,
split=f"{DATASET_SPLIT}[:{NUM_CALIBRATION_SAMPLES}]",
trust_remote_code=True,
)
# Preprocess and Tokenize inputs.
def preprocess_and_tokenize(example):
audio = example["audio"]["array"]
sampling_rate = example["audio"]["sampling_rate"]
text = " " + example["text"].capitalize()
audio_inputs = processor(
audio=audio,
sampling_rate=sampling_rate,
return_tensors="pt",
)
text_inputs = processor(
text=text,
add_special_tokens=True,
return_tensors="pt"
)
text_inputs["decoder_input_ids"] = text_inputs["input_ids"]
del text_inputs["input_ids"]
return dict(**audio_inputs, **text_inputs)
ds = ds.map(preprocess_and_tokenize, remove_columns=ds.column_names)
# Define a oneshot data collator for multimodal inputs.
def data_collator(batch):
assert len(batch) == 1
return {key: torch.tensor(value) for key, value in batch[0].items()}
Now, we can apply one-shot recipe to quantize our model. In this case, we apply GPTQ to apply the weight quantization.
# Recipe
recipe = GPTQModifier(targets="Linear", scheme="W4A16", ignore=["lm_head"])
# Apply algorithms.
oneshot(
model=model,
dataset=ds,
recipe=recipe,
max_seq_length=MAX_SEQUENCE_LENGTH,
num_calibration_samples=NUM_CALIBRATION_SAMPLES,
data_collator=data_collator,
)
# Save to disk compressed.
SAVE_DIR = MODEL_ID.split("/")[1] + "-W4A16-G128"
model.save_pretrained(SAVE_DIR, save_compressed=True)
processor.save_pretrained(SAVE_DIR)
Finally, the model can now be deployed with vLLM for better inference performance:
from vllm.assets.audio import AudioAsset
from vllm import LLM, SamplingParams
# prepare model
llm = LLM(
model="neuralmagic/whisper-large-v2-W4A16-G128",
max_model_len=448,
max_num_seqs=400,
limit_mm_per_prompt={"audio": 1},
)
# prepare inputs
inputs = { # Test explicit encoder/decoder prompt
"encoder_prompt": {
"prompt": "",
"multi_modal_data": {
"audio": AudioAsset("winning_call").audio_and_sample_rate,
},
},
"decoder_prompt": "<|startoftranscript|>",
}
# generate response
print("========== SAMPLE GENERATION ==============")
outputs = llm.generate(inputs, SamplingParams(temperature=0.0, max_tokens=64))
print(f"PROMPT : {outputs[0].prompt}")
print(f"RESPONSE: {outputs[0].outputs[0].text}")
print("==========================================")
Model Compression for Multimodal AI
LLM Compressor provides a powerful and flexible framework for compressing models, enabling faster and more efficient inference with vLLM. With the release of v0.4.0, LLM Compressor now supports quantization and sparsification of multimodal models, allowing users to efficiently scale workloads for OCR, spatial reasoning, and audio transcription/translation tasks.
To get started, explore the latest models, recipes, and examples in the LLM Compressor repository, or experiment with quantization techniques to tailor performance to your needs.
Ready to deploy faster, more scalable AI? Contact us to learn more about enterprise solutions or contribute to our open-source journey today!






