
Sep 13, 2023

Author(s)

MLPerf™ Inference v2.1 and v3.0 outcomes. What started out as a solution for research resource limitations, founders Nir Shavit and Alexander Matveev now provide a solution for customers that need a more cost efficient, yet still performant option, other than GPUs, to support deep learning initiatives. We are excited to share our latest contributions to MLPerf™ Inference v3.1, as we continue to redefine the boundaries of AI performance on CPUs, extending our coverage to the ARM architecture.
Available in SparseZoo
To build on our previous results, Neural Magic partnered with the cTuning Foundation to leverage the open-source CK technology, to automate and replicate results across all of our 74 accepted results in MLPerf™ Inference v3.1. Our CPU benchmarks use an array of sparsified BERT question answering models and are now available in SparseZoo, our dedicated repository of deployable sparsified models.
Bridging Edge and Cloud with DeepSparse on ARM
The highlight of this round is the introduction of optimizations for DeepSparse. This illustrates our continued efforts to bring together the realms of edge devices and cloud infrastructures. Neural Magic’s technology now spans across various platforms including Intel and AMD and cloud providers such as GCP and AWS. These partnerships encapsulate both x86 and ARM architectures to optimize the synergy between edge devices and cloud infrastructures.
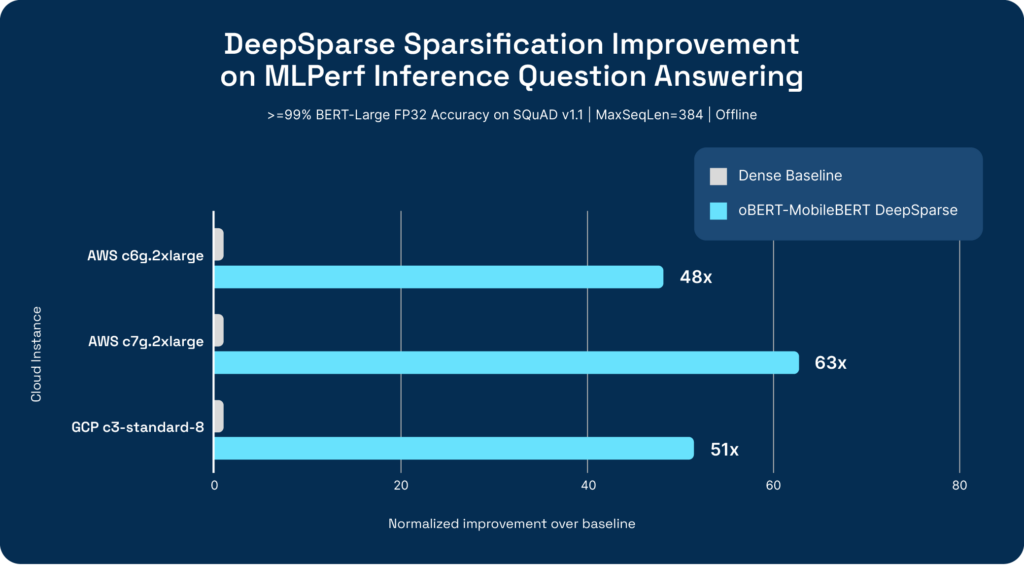
We are delighted to share that on both AWS ARM and GCP x86 instances, DeepSparse is able to provide consistent ~50x improvements over the baseline BERT-Large reference implementation. This demonstrates the power of software and model optimization as a layer of abstraction across different computing platforms to enhance the scalability and efficiency of AI workloads.
Software as a Unifying Tool
Software plays a crucial role in mediating between different platforms across edge and cloud. It allows for operational efficiency without heavy hardware investments. Neural Magic aims to simplify the complexities between various computational platforms, to promote efficiency and innovation in deep learning with a software-based solution.
Neural Magic continues to define new standards in performance and efficiency within the AI space. Motivated by continued AI innovation, we aim to eliminate hardware complexities and support ongoing work by customers.
Get direct access to our engineering teams and the wider community in the Neural Magic Community Slack for any questions you may have for us.
To keep up with our mission of efficient software-delivered AI, please star our GitHub repos and subscribe to our monthly newsletter below.






