

Feb 03, 2025

Author(s)




The 4-bit Summary
- 4-bit and 8-bit quantized LLMs excel in long-context tasks, retaining over 99% accuracy across 4K to 64K sequence lengths.
- INT4 models show limitations at 128K sequence lengths, though even their unquantized counterparts struggled at this length.
- Results are consistent across LLM sizes and diverse long-context evaluation tasks.
- All models, results, and techniques are open-sourced on Hugging Face and GitHub.
Pushing the Limits of Accurate Quantization
In our recent research blog, We Ran Over Half a Million Evaluations on Quantized LLMs: Here's What We Found, we demonstrated that quantized large language models (LLMs) can rival their full-precision counterparts in accuracy across diverse benchmarks, covering academic and real-world evaluations.
However, the community raised an important question: how well do these models perform in long-context scenarios? With the growing demand for efficient processing of extended sequences through retrieval augmented generation (RAG), agentic pipelines, and reasoning models, this question couldn't be ignored.To address it, we ran nearly 200K long-context evaluations, pushing quantized models to their limits. The results? Even in this challenging setup, quantized LLMs prove remarkably resilient, matching unquantized models in accuracy while improving inference efficiency.
The Framework
To rigorously test quantized models in long-context scenarios, we use RULER, NVIDIA’s benchmark from "RULER: What’s the Real Context Size of Your Long-Context Language Models?" This benchmark generates synthetic examples with configurable sequence lengths and task complexities, providing a robust evaluation framework.
Many LLMs struggle with RULER, showing significant performance degradation as sequence length increases—even though they achieve near-perfect scores on more straightforward needle-in-a-haystack tasks. To assess this challenge, we follow the default setup from the paper, evaluating models across four categories: retrieval, multi-hop tracing, aggregation, and question-answering, at sequence lengths of 4K, 8K, 16K, 32K, 64K, and 128K.
For models, we evaluate Neural Magic’s state-of-the-art quantized Llama-3.1-Instruct models at the 8B and 70B scales, using three different quantization formats: FP W8A8 (FP8 activations and weights), INT W8A8 (INT8 activations and weights), INT W4A16 (INT4 weights only). For deeper insights into these formats and their impact on inference performance, see our research paper “Give Me BF16 or Give Me Death”? Accuracy-Performance Trade-Offs in LLM Quantization.
The Results
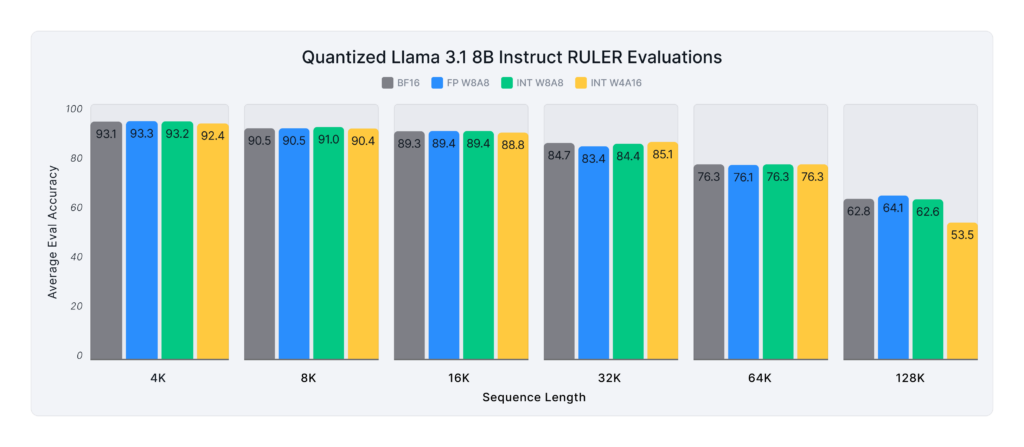
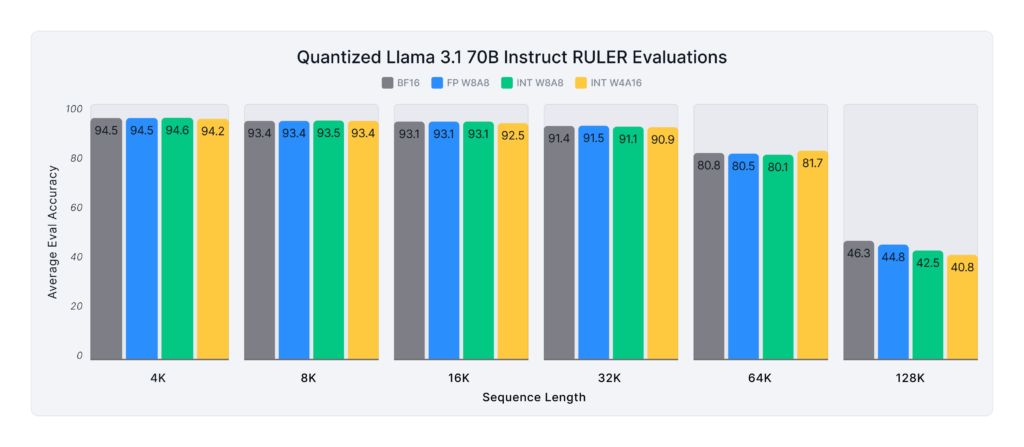
Figures 1 and 2 below show the average score of the baseline and quantized Llama 3.1 8B and 70B Instruct models on the RULER benchmark across various sequence lengths. On average, the 8B model recovers 99.2% of the unquantized model’s accuracy, while the 70B model achieves 98.6% accuracy recovery.
Across all sequence lengths, most quantization formats maintain over 99.5% accuracy recovery, with one exception: INT W4A16 at 128K length, where accuracy recovery drops to 85% (8B) and 88% (70B). However, it is important to note that at this extreme length, even unquantized models perform poorly (average scores below 65 for both sizes). As a result, accuracy recovery at 128K becomes inherently noisy, making it difficult to draw definitive conclusions about quantization’s impact at this scale.
According to RULER’s evaluation criteria, models with such low accuracy are considered unsuitable for use at 128K sequence lengths—a limitation stemming from model architecture and training, rather than quantization itself.
The Takeaways
Our findings demonstrate that quantized LLMs perform exceptionally well in long-context tasks. Across RULER’s benchmarks, quantized models consistently recover over 99% of the unquantized model’s accuracy—demonstrating their reliability and efficiency, with a few exceptions at the extremes where even the unquantized models struggle.
These results align with our previous research, showing that carefully quantized models remain highly competitive with their unquantized counterparts across various academic and real-world benchmarks. Together, these studies debunk the misconception that quantization inherently compromises performance. Instead, with proper engineering, quantized models maintain strong accuracy while offering significant efficiency gains, making them an essential tool for scaling LLMs in real-world applications.
Get Started with Efficient AI
Neural Magic, now part of Red Hat, is committed to advancing open, efficient AI. Our state-of-the-art quantized models, benchmarks, and tools like LLM Compressor are fully open-sourced, enabling faster inference, lower costs, and production-ready performance. Explore our models on Hugging Face, deploy them with vLLM, or customize them with LLM Compressor to unlock tailored optimizations.
Contact us to learn more about enterprise-grade AI solutions or contribute to the open-source ecosystem today!






