

Oct 20, 2023

Author(s)

LangChain is one of the most exciting tools in Generative AI, with many interesting design paradigms for building large language model (LLM) applications. However, developers who use LangChain have to choose between expensive APIs or cumbersome GPUs to power LLMs in their chains. With Neural Magic, developers can accelerate their model on CPU hardware, to make it easy to build powerful LangChain applications.
You can achieve remarkable speeds on CPUs by deploying sparse LLMs with DeepSparse, an inference runtime that offers up to 7X faster text generation on CPUs by leveraging the model's sparsity. This means you can run your LLMs wherever there is a CPU: in the cloud, in a data center, or at the edge.
Continue reading to learn how to use LangChain and DeepSparse to deploy LLM applications on CPUs.
How to Use LangChain With DeepSparse
First, confirm your hardware is supported, and then install the required packages:
pip install deepsparse-nightly[llm] langchainTo use DeepSparse in LangChain, import the DeepSparse class and pass the path to a model. You can use a Hugging Face model or a SparseZoo stub.
from langchain.llms import DeepSparse
prompt = "Who was the first president of the United States of America?"
llm = DeepSparse(model="hf:neuralmagic/mpt-7b-chat-pruned50-quant")
print(llm(prompt))
# The first president of the United States of America was George Washington. He was elected in 1789 and served two terms until 1797.
Stream Content
The DeepSparse LangChain integration supports streaming the LLM's response by passing the streaming argument as True:
from langchain.llms import DeepSparse
llm = DeepSparse(model="hf:neuralmagic/mpt-7b-chat-pruned50-quant", streaming=True)
for chunk in llm.stream("Tell me a joke", stop=["'","\n"]):
print(chunk, end='', flush=True)
Use LangChain Prompt Templates
The DeepSparse class is a LangChain wrapper, which means you can access all the other LangChain utilities, such as prompt templates and parsing outputs:
from langchain import PromptTemplate
from langchain.output_parsers import CommaSeparatedListOutputParser
llm_parser = CommaSeparatedListOutputParser()
llm = DeepSparse(model='hf:neuralmagic/mpt-7b-chat-pruned50-quant')
prompt = PromptTemplate(
template="List how to {do}",
input_variables=["do"]
)
output = llm.predict(text=prompt.format(do="Become a great software engineer"))
print(output)

Chat With PDF Application on a CPU
To see an LLM application running on a CPU, build a PDF chat application using DeepSparse, Chainlit, and LangChain. This application will require the following packages:
pip install deepsparse-nightly[llm] chainlit langchain PyPDF2 sentence_transformers chromadb
Start by importing all the required modules:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
import os
import chainlit as cl
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.llms import DeepSparse
from io import BytesIO
import PyPDF2
Next, set up the embeddings and model so that they are downloaded once the program starts. The model is the mosaicml/mpt-7b-chat that has been pruned to 50% and then quantized. For the embeddings, use sentence-transformers through Hugging Face:
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={"device": "cpu"},
)
llm = DeepSparse(
model="hf:neuralmagic/mpt-7b-chat-pruned50-quant",
model_config={"sequence_length": 2048},
stop=["<|im_end|>", "<|endoftext|>"],
streaming=True,
)
Upload your PDF
Chainlit provides tools for building LLM applications quickly.
In this case, when the application starts, the user is prompted to upload a PDF file. Once the file has been uploaded, perform the following tasks before the user can chat with the PDF:
- Extract the contents of the PDF file.
- Split the content into smaller pieces since the LLM has a maximum number of tokens it can accept, 2048 for MPT.
- Create word embeddings for the split text.
- Store the embeddings in a vector store, in this case, Chromadb.
- Create a
RetrievalQAchain that will use the Chromadb vector store.
All this functionality is bundled in a function that is decorated by cl.on_chat_start. The chain created in this function is saved for use in the next function.
Here is the entire function:
@cl.on_chat_start
async def init():
files = None
# Wait for the user to upload a file
while files == None:
files = await cl.AskFileMessage(
content="Please upload a pdf file to begin!",
accept=["application/pdf"],
max_size_mb=50,
).send()
file = files[0]
msg = cl.Message(content=f"Processing `{file.name}`...")
await msg.send()
if file.type != "application/pdf":
raise TypeError("Only PDF files are supported")
pdf_stream = BytesIO(file.content)
pdf = PyPDF2.PdfReader(pdf_stream)
pdf_text = ""
for page in pdf.pages:
pdf_text += page.extract_text()
texts = text_splitter.create_documents([pdf_text])
for i, text in enumerate(texts):
text.metadata["source"] = f"{i}-pl"
# Create a Chroma vector store
docsearch = Chroma.from_documents(texts, embeddings)
# Create a chain that uses the Chroma vector store
chain = RetrievalQA.from_chain_type(
llm,
chain_type="stuff",
return_source_documents=True,
retriever=docsearch.as_retriever(),
)
# Save the metadata and texts in the user session
metadatas = [{"source": f"{i}-pl"} for i in range(len(texts))]
cl.user_session.set("metadatas", metadatas)
cl.user_session.set("texts", texts)
# Let the user know that the system is ready
msg.content = f"Processing `{file.name}` done. You can now ask questions!"
await msg.update()
cl.user_session.set("chain", chain)In the retriever, set return_source_documents to True to get the sources for the answers the LLM provides.
Chat with PDF
With all the building blocks in place, you are now ready to start receiving messages from the user. This is done by creating a function that is decorated by cl.on_message. This function accepts a message parameter. The function also grabs the chain created in the previous function via the user's session. Chainlit runs the function decorated by on_message when a user sends a message.
In this case, create an asynchronous callback handler, which allows you to call the chain via the acall_method. The LLM returns a dictionary containing the result and source_documents keys, which you can print on the screen.
Here is the entire function:
@cl.on_message
async def main(message: cl.Message):
chain = cl.user_session.get("chain") # type: RetrievalQAWithSourcesChain
cb = cl.AsyncLangchainCallbackHandler(
stream_final_answer=True, answer_prefix_tokens=["FINAL", "ANSWER"]
)
cb.answer_reached = True
res = await chain.acall(message.content, callbacks=[cb])
answer = res["result"]
source_documents = res["source_documents"]
source_elements = []
# Get the metadata and texts from the user session
metadatas = cl.user_session.get("metadatas")
all_sources = [m["source"] for m in metadatas]
texts = cl.user_session.get("texts")
if source_documents:
found_sources = []
# Add the sources to the message
for source_idx, source in enumerate(source_documents):
# Get the index of the source
source_name = f"source_{source_idx}"
found_sources.append(source_name)
# Create the text element referenced in the message
source_elements.append(
cl.Text(content=str(source.page_content).strip(), name=source_name)
)
if found_sources:
answer += f"\nSources: {', '.join(found_sources)}"
else:
answer += "\nNo sources found"
if cb.has_streamed_final_answer:
cb.final_stream.content = answer
cb.final_stream.elements = source_elements
await cb.final_stream.update()
else:
await cl.Message(content=answer, elements=source_elements).send()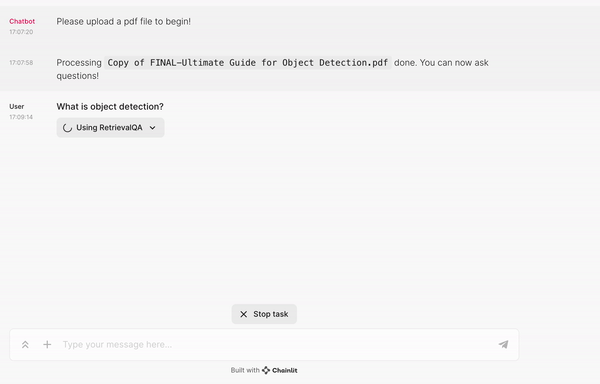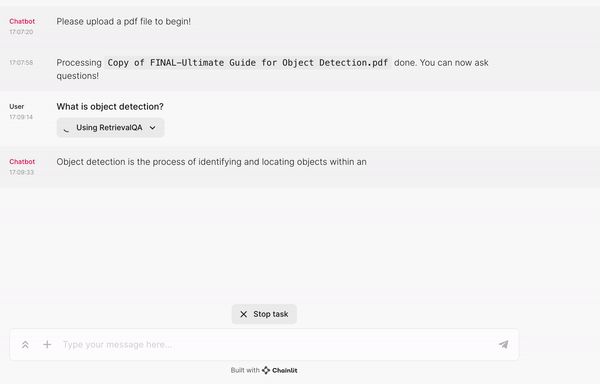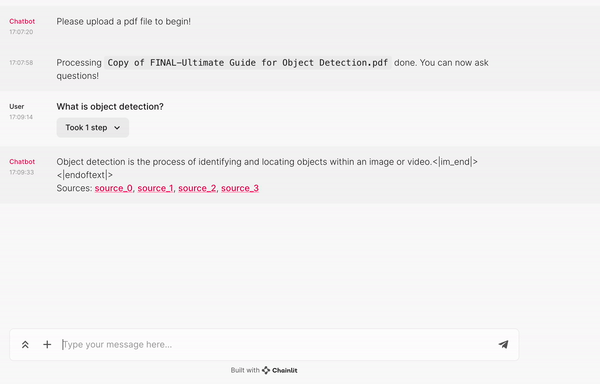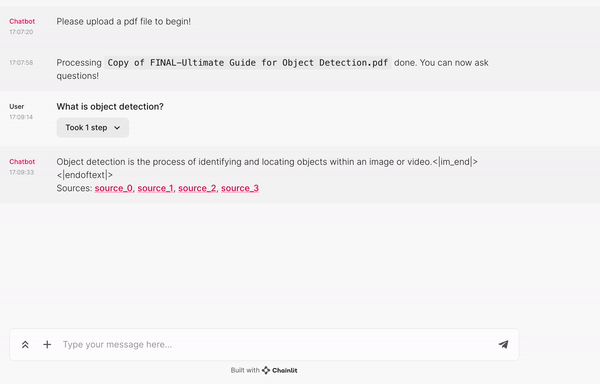
Final Thoughts
Deploying large language models on CPUs is now a reality. As you have read, you can use DeepSparse and LangChain to use with LLMs that have been optimized, to run fast on a CPU. These models enable anyone with a simple computer to start using LLMs. It also makes it faster for developers to iterate on solutions without configuring complicated hardware.
Neural Magic is excited to see what kind of LLM applications you will build on CPUs. Join us on Slack for any questions or submit an issue on GitHub. Check out the PDF chat demo on Hugging Face Spaces.






