

Mar 20, 2025
A Compressed Summary
- Open-Source Models: Quantized versions of Pixtral (12B, Large), Qwen2-VL (72B), and Qwen2.5-VL (3B, 7B, 72B) are now available.
- Competitive Accuracy Recovery: FP8 and INT8 quantized versions recover >99% across five vision benchmarks, while INT4 has a modest drop on smaller models.
- Performant Deployments: With vLLM, up to 3.5X faster throughput scenarios and 3.2X more requests per second for server scenarios.
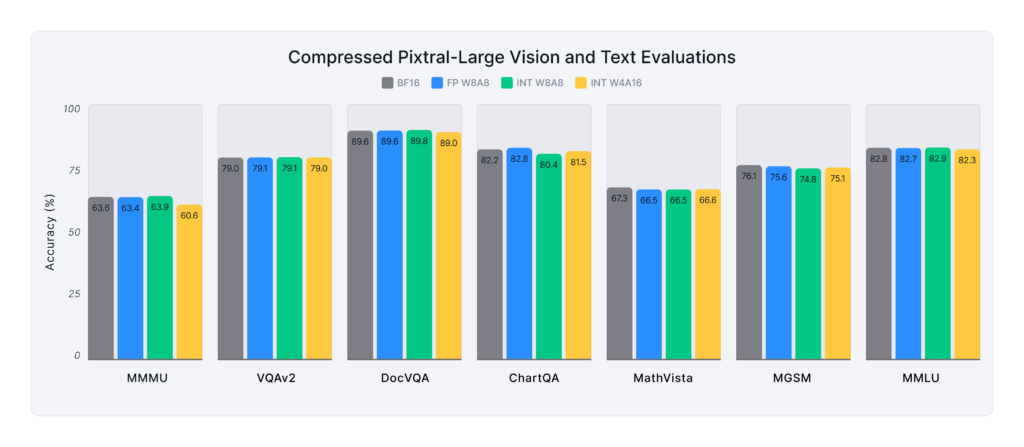
Quantized Vision-Language Models
Vision-Language Models (VLMs), such as the Pixtral and Qwen-VL series, are trained to generate text from image and text inputs. With the expanded input types and the performance of large language models, they enable accurate and promising new use cases such as content moderation, image captioning and tagging, visual question answering, and document extraction/analysis, among others. The extra modality, though, means that VLMs are even more computationally demanding, requiring more processing power and memory than the already demanding language-only architectures.
Utilizing the latest vision-language support within LLM Compressor, we created quantized, deployment-ready versions of Pixtral (12B, Large), Qwen2-VL (72B), and Qwen2.5-VL (3B, 7B, 72B) for off-the-shelf deployments with vLLM. On average, the models recovered >99% accuracy at 8-bit precision and ~98% at 4-bit across vision tasks while inferencing up to 4.3X faster for throughput or 2.2X more requests per second for low latency server scenarios. Specifically, three versions of each model were created, thoroughly evaluated, and run through numerous inference scenarios:
- FP W8A8: 8-bit floating-point weights and activations supporting server and throughput scenarios for the latest Ada Lovelace and Hopper GPUs.
- INT W8A8: 8-bit integer weights and activations supporting server and throughput scenarios for Ampere and older GPUs.
- INT W4A16: 4-bit integer weights with activations kept at the baseline 16 bits for single-stream and low queries per second scenarios.
The models, recipes, evaluations, and benchmarks are open-sourced and available in our Hugging Face model collection. These include the complete commands for deployments and replication of our data outlined in the rest of the blog to get started. Additionally, check out our previous blog in this series, which walks you through quantizing your multimodal models!
Accuracy Recovery Across Evaluations
We evaluated the quantized versions compared to their baseline performance across many current top available benchmarks. Specifically, we used mistral-evals for visual question answering, visual reasoning, chart and graph interpretation, and a few standard language tasks. The complete list is provided below and ensures a comprehensive overview and comparison for the performance of these models:
Vision Benchmarks
- MMMU: Measures the model's ability to effectively handle visual and linguistic inputs.
- ChartQA: Focuses on interpreting visual charts and graphs to generate correct textual answers.
- DocVQA: Assesses the model's performance on document-based visual question answering.
- VQAv2: Evaluates question answering accuracy over diverse visual inputs.
- Mathvista: Evaluates mathematical reasoning in visual contexts, incorporating 31 diverse datasets.
Text Benchmarks
- MMLU: Measures the model's capability to answer various questions spanning reasoning, math, and general knowledge.
- MGSM: Focuses on grade-school level math in a conversational setup across multiple languages.
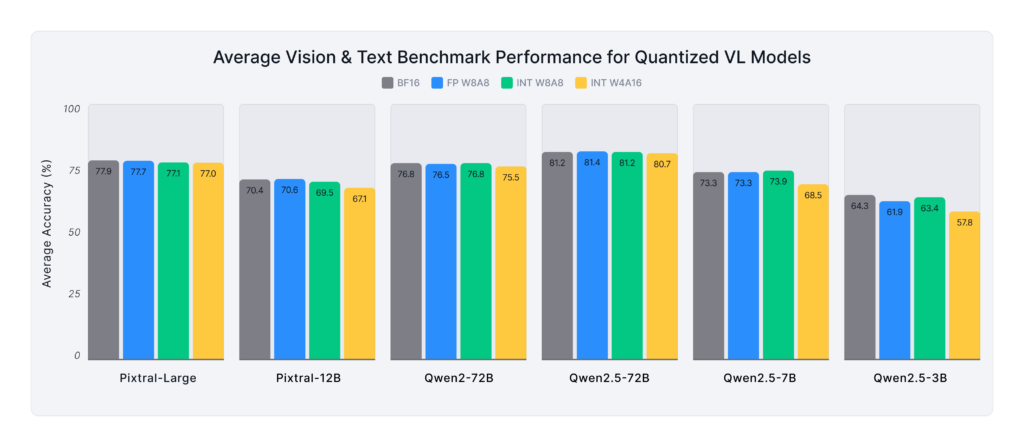
Figure 3, above, shows the average performance of various quantized multimodal models across the aforementioned vision and text benchmarks:
- FP W8A8 delivers near-lossless performance, on par with BF16 across all models.
- INT W8A8 recovers ~99% of the original accuracy, being very competitive to the FP W8A8.
- INT W4A16 performs reasonably well for most models with >96% recovery. The smaller 3B and 7B models performed worse, with >90% and >92% recovery, respectively. Note, most of the drop came from text evals; for vision alone, the recovery jumps to ~98%.
Inference Performance Across Use Cases
To ensure realistic benchmarks and measurement of the inference performance, we designed a set of vision-language workloads capturing a broad range of use cases and scenarios. For scenarios, we benchmarked across server scenarios for both low-latency and high-throughput. The workloads are defined by the number of prompt tokens and the input image size. This latter point is necessary due to the different processors within the models, which generate differing token input lengths for the exact image size. The workloads include:
- Document Visual Question Answering (DocVQA) (1680W × 2240H pixels, 64 prompt tokens, 128 generated tokens)
- Visual Reasoning (640W × 480H pixels, 128 prompt tokens, 128 generated tokens)
- Image Captioning (480W × 360H pixels, 0 prompt tokens, 128 generated tokens)
How Quantization Impacts Different Models
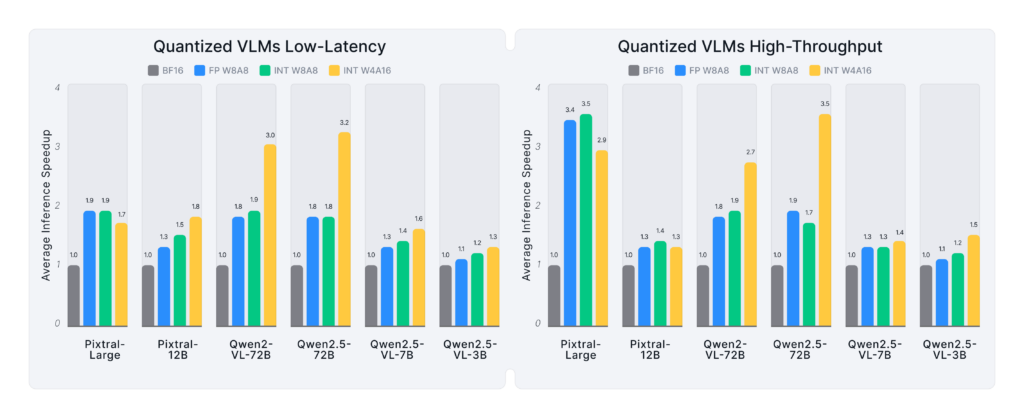
Figure 4 presents the average inference speedups across all workloads (Visual Reasoning, DocVQA, Image Captioning) and GPU platforms (A6000, A100, H100). Key insights include:
- Larger models benefit most from quantization, with Qwen2/2.5-VL-72B and Pixtral-Large achieving up to 3.5x speedups.
- Smaller models, like Qwen2.5-VL-3B, show more modest gains (1.1x–1.5x) due to lower memory and compute demands.
- Qwen2/2.5-VL models gain the most from INT W4A16, suggesting they are more memory-bound than compute-bound in most deployment scenarios.
How Quantization Impacts Different Workloads
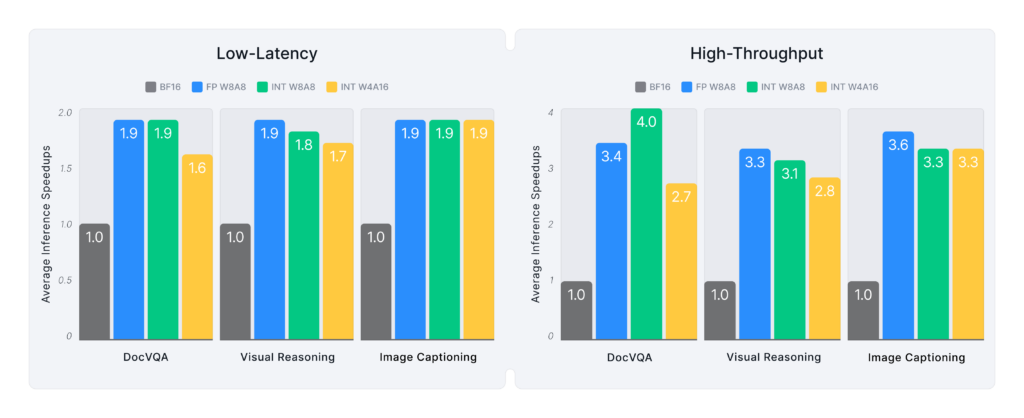
Figure 5 provides a detailed breakdown of Pixtral-Large speedups across different workloads, reinforcing that:
- Pixtral-Large benefits most from W8A8 overall.
- For lighter workloads (Visual Reasoning, Image Captioning), INT W4A16 performs comparably to W8A8.
- For more compute-intensive tasks (DocVQA), W8A8 delivers the highest speedups.
How GPU Size Impacts Performance
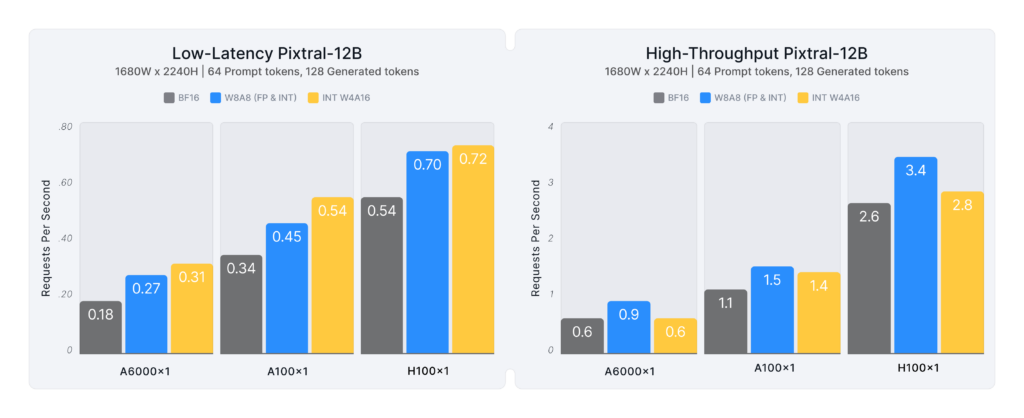
Figure 6 highlights Pixtral-12B, analyzing how quantization improves inference speed across different GPU architectures in DocVQA:
- Low-latency deployments benefit more from INT W4A16 (1.3–1.7x speedup).
- High-throughput deployments favor W8A8 formats (1.3–1.5x speedup).
- Lower-tier GPUs (e.g., A6000) experience greater gains from quantization, as workloads can overload memory and reduce BF16 request throughput. INT W4A16 and W8A8 alleviate these bottlenecks, enabling higher efficiency and serving more requests in parallel.
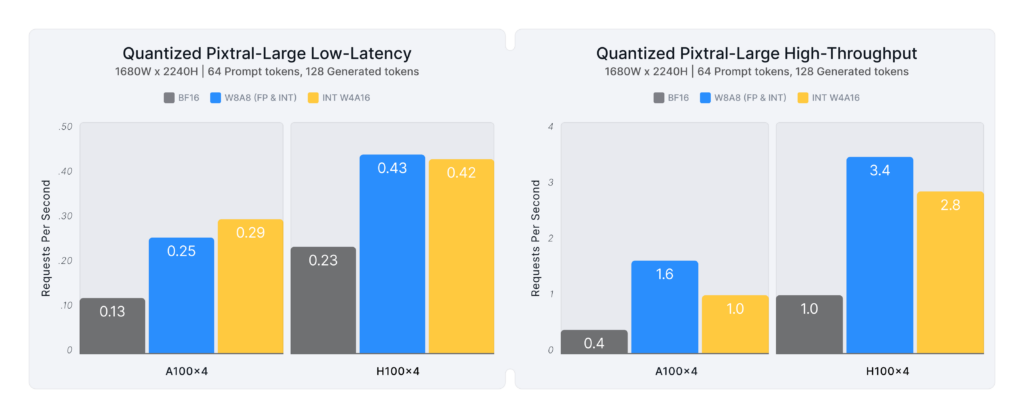
Figure 2 (at the beginning of the blog) summarizes the performance gains for Pixtral-Large on the most intensive DocVQA workload across different GPUs:
- A100: INT W4A16 enables >2.2x faster requests for low-latency scenarios, while INT W8A8 provides 1.9x higher throughput.
- H100: FP W8A8 enables 1.9x faster requests for low-latency workloads and provides 3.4x higher throughput.
Optimizing for Real-World Deployment
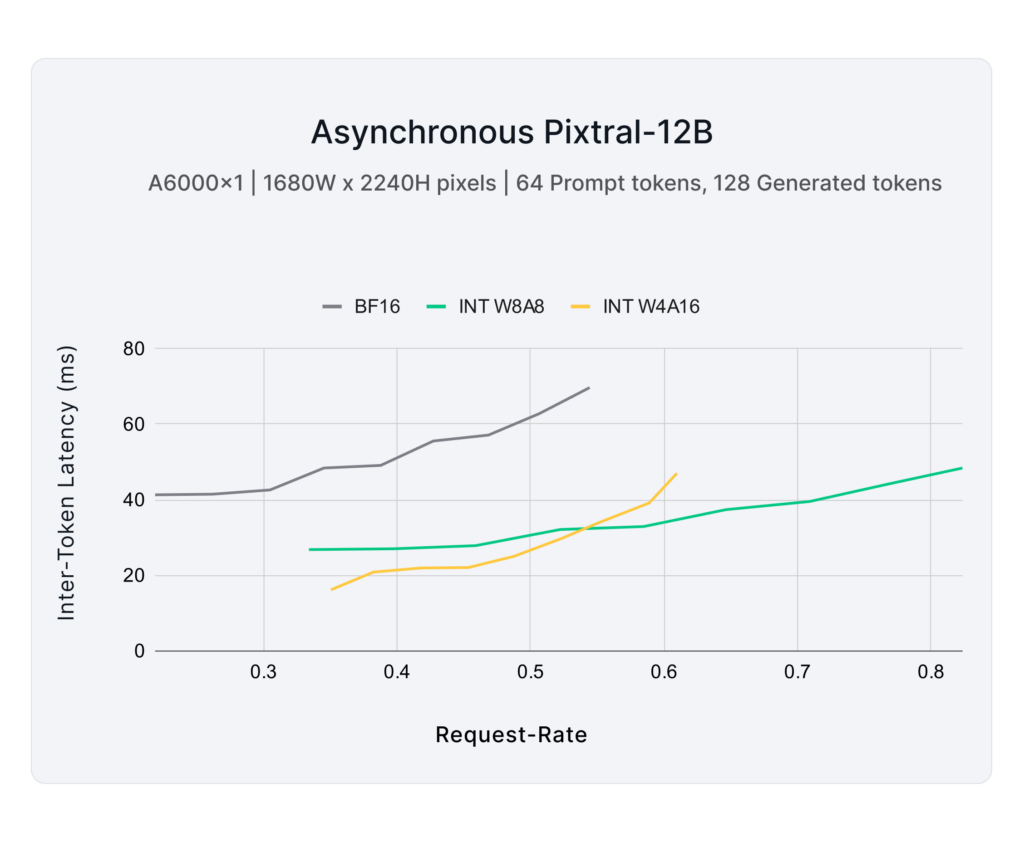
Most practical deployments fall between low-latency and high-throughput scenarios, requiring efficiency while maintaining response time constraints. Figure 7 examines how quantization impacts token generation speed under increasing load:
- INT W4A16 provides the lowest response times, maintaining minimal inter-token latency at low to medium request rates.
- INT W8A8 balances speed and efficiency, reducing latency over BF16 while supporting higher request rates, making it a strong choice for high-speed, multi-stream inference.
Get Started with Quantized VLMs
The future of Vision-Language Models (VLMs) lies in balancing performance, efficiency, and accessibility. By leveraging quantization, we enable faster inference, lower costs, and scalable AI deployment without compromising capability.
Ready to explore? Check out our fully open-source quantized models, including Qwen2, Qwen2.5, Pixtral, and more on our Hugging Face VLM collection.
Driving AI Efficiency with Quantization
We’re excited to see how the community applies these quantized VLMs—whether for efficient deployment, advancing quantization techniques, or scaling AI for broader applications. These models provide a strong foundation for real-world AI innovation.
As part of Red Hat, Neural Magic remains committed to open, efficient AI, providing cutting-edge quantization tools like LLM Compressor and optimized inference solutions via vLLM. Explore, deploy, or customize our models to suit your needs.
Get in touch to learn more about enterprise-grade AI solutions or contribute to the open-source ecosystem today!






