

Mar 14, 2025

Author(s)





Introduction
DeepSeek and vLLM optimizations have been a top priority for our team and the vLLM community as a whole, and we are excited to share a deep dive into our work. In this article, we will cover the key inference improvements we have made, detail the integration of DeepSeek’s latest advancements into vLLM, and discuss how we are scaling DeepSeek-R1 for real-world deployment. Additionally, we will review the various open-source contributions from DeepSeek and outline our roadmap for integrating them into vLLM.
Introduction to vLLM
vLLM is an open-source inference server designed for efficient model serving, providing a streamlined, high-performance infrastructure for large language models (LLMs). It is licensed under Apache 2.0 and can be installed via pip or deployed as a Docker image, making it easily accessible. It supports a variety of hardware platforms, including NVIDIA, AMD, Intel, Google, Amazon, and Huawei, ensuring wide compatibility across different infrastructures.
Neural Magic, now part of Red Hat, is a top commercial contributor to vLLM, working extensively on model and systems optimizations to improve vLLM performance at scale. The framework supports multimodal models, embeddings, and reward modeling, and is increasingly used in reinforcement learning with human feedback (RLHF) workflows. With features such as advanced scheduling, chunk prefill, Multi-LoRA batching, and structured outputs, vLLM is optimized for both inference acceleration and enterprise-scale deployment.
DeepSeek-R1: A Complex Model
DeepSeek-R1 has been making headlines for its exceptional reasoning capabilities and its novel architectural advancements. It introduces several technical challenges due to its complexity and scale.
One of the defining characteristics of DeepSeek-R1 is its sheer size. With 256 experts in its MLP layers, over 671 billion parameters, and 720GBs in size, it surpasses previous models such as Mixtral, which only had 8 experts. The model is so large that it cannot fit even on an 8x H100 node, requiring innovative techniques for inference and deployment. Additionally, DeepSeek-R1 is one of the first foundation models trained using FP8 quantization, a novel approach that requires custom support for inference.
Prior to DeepSeek-R1, our model and system optimization efforts focused primarily on Llama-style models. The introduction of DeepSeek-R1 has required significant modifications to accommodate its new architectural features. Over the past several weeks, we have worked on performance optimizations to enhance efficiency and reduce computational overhead. While we have made substantial progress, further work is required to refine and finalize production-ready implementations.
An insightful chart, shared by UnSloth, illustrates the rapid pace of development in this space. This chart tracks the performance of various LLM serving frameworks, including those utilizing vLLM, and demonstrates how tokens per second have grown exponentially. The progress has been driven by our integration of Multi-Token Prediction (MTP), MLA, and torch.compile, among other advancements.
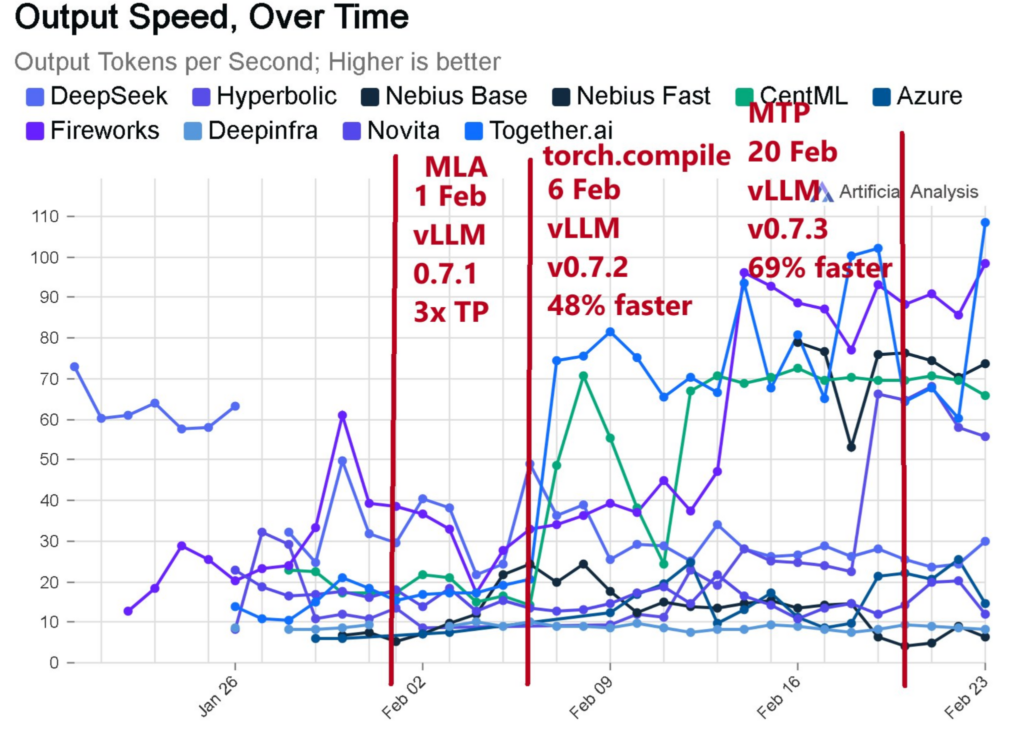
Source: https://docs.google.com/presentation/d/1h2Y7YbnbhuXrCh9rkQ33ZcC5MyB65oGK/edit#slide=id.p1
Open Infra Week Contributions
DeepSeek’s Open Infra Week in February, 2025, introduced a series of inference kernel advancements aimed at accelerating model execution. Our team has focused on integrating these optimizations into vLLM and improving their performance.
Key contributions from Open Infra Week include:
- FlashMLA (Multi-Head Latent Attention): A kernel for MLA that increases speeds up batched decoding
- DPP (Dynamic Partitioning for Parallelism): A new method to balance computational loads across distributed environments.
- Speculative Decoding Enhancements: Techniques that boost inference speed while maintaining accuracy.
We continue to collaborate with the open-source community through GitHub and Slack discussions, refining and integrating these optimizations into vLLM.
MLA, Multi-Token Prediction, and Parallelism Optimizations
To fully optimize vLLM for DeepSeek-R1, we have focused on three major areas: Multi-Head Latent Attention (MLA), Multi-Token Prediction (MTP), and parallelism strategies. These optimizations ensure that vLLM can efficiently handle the computational demands of DeepSeek-R1.
MLA: Reducing KV Cache Bottlenecks
MLA dramatically reduces KV cache size by projecting key-value heads into a compressed latent space. This optimization significantly decreases memory bandwidth usage, increasing the maximum token capacity from 67K to 650K and allowing for larger batch processing throughput.
MLA: Impact on Performance
Reduced KV cache size enables significantly more batching and therefore throughput at inference time
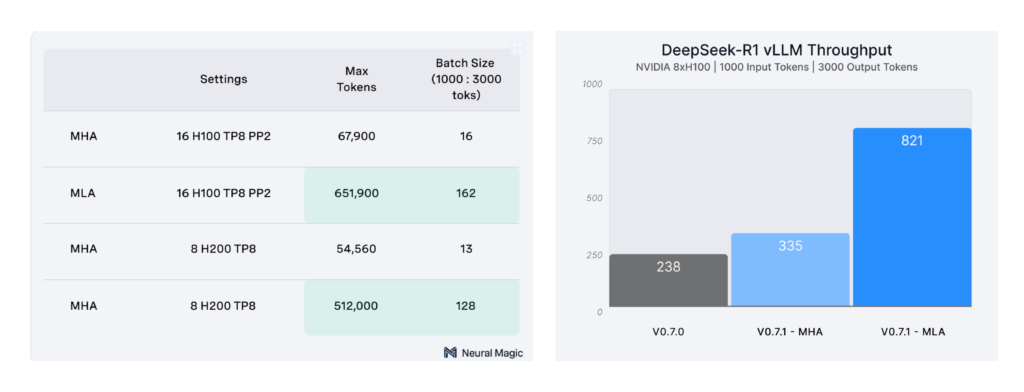
Source: https://docs.google.com/presentation/d/1h2Y7YbnbhuXrCh9rkQ33ZcC5MyB65oGK/edit#slide=id.p1
While MLA provides substantial benefits, its implementation presents challenges. Unlike traditional MHA, MLA involves varying Q, K, and V head dimensions, which many existing kernels do not support. We are actively working on integrating kernel-level optimizations to fully exploit MLA’s advantages.
MTP: Enhancing Reasoning Model Performance
DeepSeek-R1’s reasoning tasks require generating long sequences, making inference efficiency critical. MTP enables faster processing by predicting multiple tokens per step rather than one at a time. This leads to significant improvements in inference speed, particularly for workloads that involve extended decoding phases.
The team at Meta implemented MTP over the course of the past couple of weeks. Tests show that MTP provides up to a 20% speed improvement in low QPS scenarios.
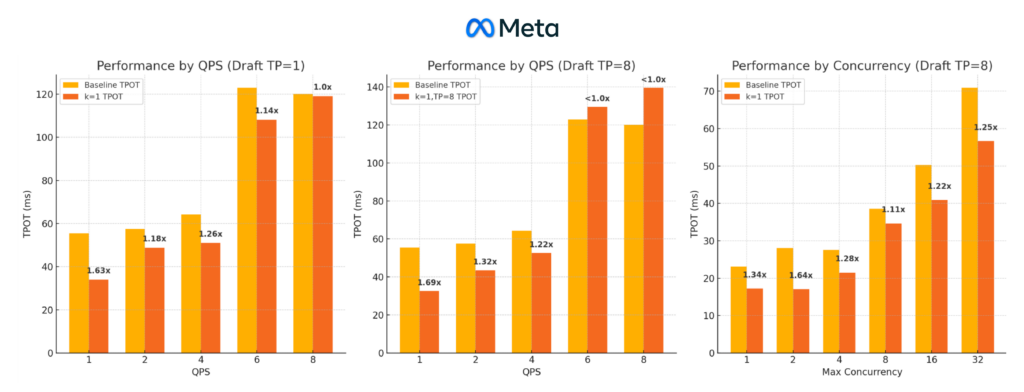
Source: https://docs.google.com/presentation/d/1h2Y7YbnbhuXrCh9rkQ33ZcC5MyB65oGK/edit#slide=id.p1
Parallelism: Scaling DeepSeek-R1 Efficiently
DeepSeek-R1’s architecture requires parallelism strategies beyond traditional tensor parallelism. These are integrations called Expert Parallelism (EP) and Data Parallelism (DP) to improve performance.
- Expert Parallelism (EP): Assigns specific experts to dedicated GPUs, ensuring efficient utilization and reducing redundancy.
- Data Parallelism (DP): Distributes batched sequences between GPUs for the attention layers, avoiding KV cache duplication to improve memory efficiency.
These techniques allow us to effectively distribute computational loads, leading to more scalable inference. Check out the Office Hours recording on Distributed Inference with vLLM.
Future Roadmap and Next Steps
Looking forward, our primary goals are to finalize key optimizations and continue refining vLLM’s performance for DeepSeek-R1. Some of the next steps include:
- Finalizing V1 MLA and FlashMLA support to fully integrate DeepSeek’s attention optimizations.
- Enhancing speculative decoding techniques to further reduce inference latency.
- Optimizing multi-node parallelism strategies to better handle DeepSeek-R1’s immense parameter count.
- Benchmarking additional DeepSeek inference kernels to validate efficiency improvements in real-world use cases.
As part of our continued development, we will be conducting large-scale benchmarking experiments and collaborating with other teams to fine-tune vLLM’s infrastructure. By focusing on both algorithmic improvements and practical deployment strategies, we aim to make vLLM the most robust and scalable inference framework for large-scale models.
Conclusion
Our work optimizing vLLM for DeepSeek-R1 has been a significant effort, made possible through collaboration with Neural Magic (Red Hat), DeepSeek, Berkeley, Meta, and the broader open-source community. Over the past few weeks, we have made substantial progress in improving inference performance through MLA, MTP, and advanced parallelism techniques.
With optimizations that reduce KV cache size, enhance multi-token prediction, and introduce scalable parallelism strategies, vLLM is well-positioned to serve next-generation AI models efficiently. Looking ahead, our continued focus will be on refining and finalizing these improvements, ensuring vLLM remains the premier open-source solution for deploying large-scale models.
We are excited about the future and look forward to sharing further updates as we push the boundaries of inference performance for DeepSeek-R1!
Author(s)






