

Feb 27, 2025

Author(s)




The 4-bit Breakdown
- State-of-the-art, open-source quantized reasoning models built on the DeepSeek-R1-Distill suite are now available.
- FP8 and INT8 quantized versions achieve near-perfect accuracy recovery across all tested reasoning benchmarks and model sizes—except for the smallest INT8 1.5B model, which reaches 97%.
- INT4 models recover 97%+ accuracy for 7B and larger models, with the 1.5B model maintaining ~94%.
- With vLLM 0.7.2, we validated inference performance across many common inference scenarios and GPU hardware, resulting in up to 4X better inference performance.
Quantized Reasoning Models
In recent research, including We Ran Over Half a Million Evaluations on Quantized LLMs and How Well Do Quantized Models Handle Long-Context Tasks?, we’ve shown that quantized large language models (LLMs) rival their full-precision counterparts in accuracy across diverse benchmarks, covering academic, real-world use cases, and long-context evaluations while delivering significant speed and cost benefits.
With the rise of reasoning-focused models, like DeepSeek’s R1 series, a new challenge emerges: Can quantization preserve accuracy in complex reasoning scenarios requiring chain-of-thought, thinking tokens, and long-context comprehension?
To answer this, we quantized and open-sourced the entire DeepSeek-R1-Distill model suite in three widely-used formats–FP W8A8, INT W8A8, INT W4A16–adhering to the best practices outlined in our recent paper, "Give Me BF16 or Give Me Death"? Accuracy-Performance Trade-Offs in LLM Quantization.
Our evaluations across leading reasoning benchmarks confirm that with state-of-the-art (SOTA) quantization techniques, LLMs retain competitive reasoning accuracy while unlocking significant inference speedups.
Want to get started right away? The quantized DeepSeek-R1-Distill models, including Llama-8B, Llama-70B, Qwen-1.5B, Qwen-7B, Qwen-14B, and Qwen-32B, are now available as a Hugging Face collection with full evaluations, benchmarks, and setup instructions. Check them out now, or keep reading for deeper insights and key takeaways!
Rigorous Evals, Real Insights
We quantized the DeepSeek-R1-Distill models using the LLM-Compressor library, which provides a simple, easy-to-use interface for SOTA model compression. The resulting models are optimized for high-performance inference with the popular vLLM inference and serving library.
Reasoning Benchmarks
To rigorously evaluate their reasoning capabilities, we leveraged LightEval, Hugging Face’s lightweight LLM evaluation framework, running on vLLM for fast and scalable evals. Following DeepSeek’s recommendations for text generation, we use sampling with a temperature of 0.6 and top-p of 0.95, generating 20 responses per query to estimate the pass@1 score. The repetitive sampling was important to estimate an accurate average performance for the benchmarks due to high variance across the relatively small datasets. We tested across three leading reasoning benchmarks:
- AIME 2024: 30 expert-level math problems from the American Invitational Mathematics Examination (AIME).
- MATH-500: 500 challenging problems curated from OpenAI’s MATH benchmark.
- GPQA-Diamond: A set of challenging, expert-validated multiple-choice questions spanning biology, physics, and chemistry.
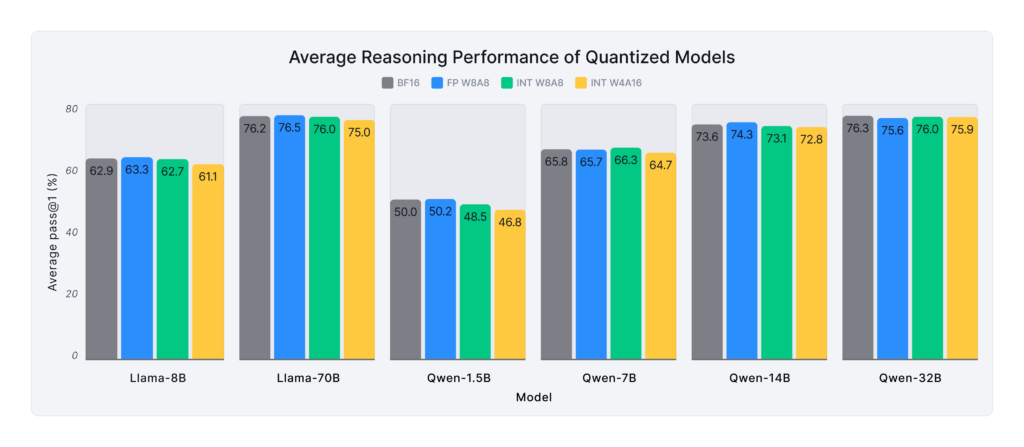
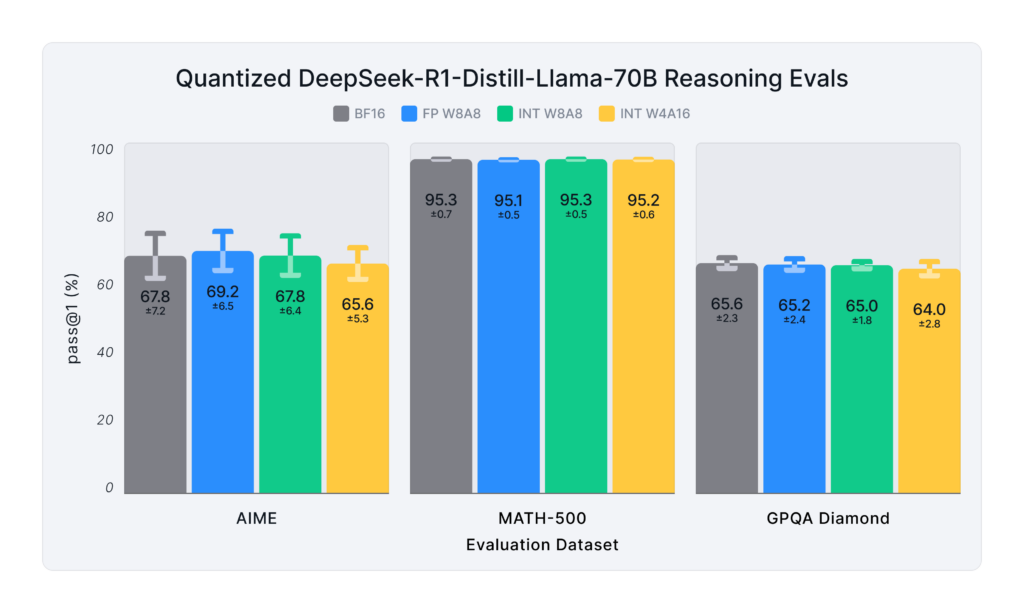
Figure 3 presents the average pass@1 scores of the various quantized DeepSeek-R1-Distill models across the reasoning benchmarks:
- FP W8A8 (8-bit floating-point weights and activations) demonstrate near-lossless accuracy, matching BF16.
- INT W8A8 (8-bit integer weights and activations) closely follows, recovering ~99% of the original accuracy.
- INT W4A16 (4-bit weight-only integer quantization) exhibits a slight drop on AIME and GPQA-Diamond, while performing strongly on MATH-500: the Qwen-1.5B model, the smallest in the suite, accounts for most of this drop.
General Benchmarks
To ensure generalization beyond reasoning tasks, we also evaluated all models on the standard Open LLM Leaderboard V1 benchmark, including MMLU, ARC-Challenge, HellaSwag, Winogrande, GSM8k, and TruthfulQA.
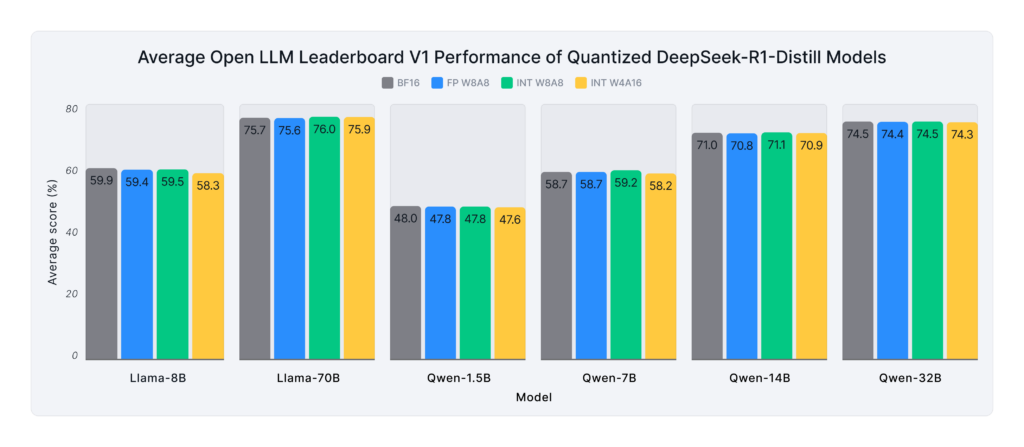
On the Open LLM Leaderboard V1 benchmark, Figure 4 shows that quantized models consistently achieve over 99% accuracy recovery, with only one outlier: the Llama-8B model at INT W4A16, which experiences a modest drop to 97.33%. Despite being optimized for complex reasoning, the original and quantized models perform strongly on standard academic benchmarks.
These results align with our recent paper, "Give Me BF16 or Give Me Death? Accuracy-Performance Trade-Offs in LLM Quantization":
- FP W8A8 consistently delivers lossless compression, maintaining full accuracy while accelerating inference on NVIDIA Hopper and Ada Lovelace GPUs.
- INT W8A8 closely matches FP W8A8 performance, making them an effective alternative for Ampere and older devices.
- INT W4A16 performs competitively on larger models but shows some accuracy loss on smaller ones.
These results confirm that state-of-the-art quantization techniques preserve reasoning accuracy while enabling more efficient deployment. However, accuracy is only one side of the equation—real-world usability depends on inference speed, latency, and hardware efficiency. In the next section, we dive into how these quantized models perform in deployment, benchmarking their inference speed across different hardware configurations and use cases.
Inference Performance in vLLM
To assess deployment performance, we benchmarked the DeepSeek-R1-Distill models across multiple hardware configurations and workloads using vLLM 0.7.2, focusing on latency, throughput, and server scenarios. More information on the workloads considered here can be found in the model cards of the quantized models.
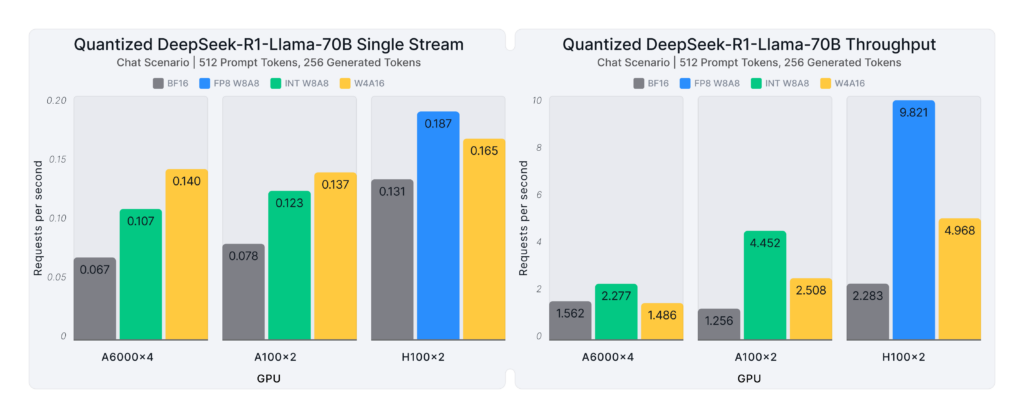
Figure 2, at the blog's beginning, briefly summarizes the general results, showcasing the performance gains from quantization for the DeepSeek-R1-Distill-Llama-70B model for a chat use case (512 prompt tokens, 256 generated tokens) across various GPU hardware platforms:
- A6000: INT W4A16 enables 2.1X faster requests for single stream while INT W8A8 provides 1.5X better throughput.
- A100: INT W4A16 enables 1.7X faster requests for single stream while INT W8A8 provides 2X better throughput.
- H100: FP W8A8 enables 1.4X faster requests for single stream and provides 4.3X better throughput.
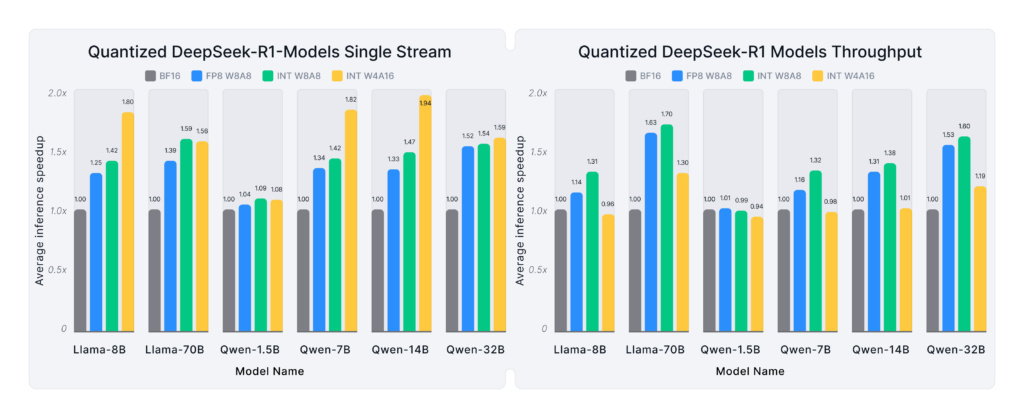
Figure 5 extends these insights by presenting average inference speedups across all workloads—including chat, instruction following, summarization, retrieval-augmented generation (RAG), and coding—on A6000, A100, and H100 GPUs.
- Single-stream (low-latency) deployments: W4A16 delivers the highest speedups, with a performance increase of up to 1.9X better than the baseline. This trend is especially pronounced for medium and large models, where memory and compute optimizations have a more substantial impact.
- High-throughput multi-stream scenarios: W8A8 (FP and INT formats) achieve the best performance gains, particularly for larger models, averaging 1.3-1.7X better throughput across the tested workloads.
- The DeepSeek-R1-Distill-Qwen-1.5B model sees minimal speedup, as its BF16 variant is already lightweight relative to the compute and memory capacity of the tested GPUs.
Conclusion
Our results demonstrate that quantized reasoning LLMs perform strongly on the most challenging benchmarks while delivering substantial inference speedups. Whether optimizing for low-latency applications or high-throughput scaling, these models provide an efficient, deployment-ready solution without sacrificing reasoning accuracy.
All models are fully open-sourced in our Hugging Face model collection, complete with LLM-Compressor recipes to reproduce and fine-tune the quantization process.
Get Started with Efficient AI
Neural Magic, now part of Red Hat, is committed to advancing open, efficient AI. Our state-of-the-art quantized models, benchmarks, and tools like LLM Compressor are fully open-sourced, enabling faster inference, lower costs, and production-ready performance. Explore our models on Hugging Face, deploy them with vLLM, or customize them with LLM Compressor to unlock tailored optimizations.
Contact us to learn more about enterprise-grade AI solutions or contribute to the open-source ecosystem today!






