

Jan 30, 2025

Author(s)



A Compressed Summary
- Neural Magic is now part of Red Hat, accelerating our mission to deliver open and efficient AI.
- Our new compressed Granite 3.1 models are designed for enterprise deployments, achieving 3.3X smaller models, up to 2.8X better performance, and 99% accuracy recovery.
- Models and recipes are open-sourced on Hugging Face, deployment-ready with vLLM, and extensible using LLM Compressor.
Smaller, Faster Granite for All
Neural Magic is excited to join Red Hat, combining our expertise in AI optimization and inference with Red Hat’s legacy of open-source innovation. Together, we’re paving the way for more efficient, scalable, and accessible AI solutions tailored to the needs of developers and enterprises across the hybrid cloud.
Our first contribution in this new chapter is the release of compressed Granite 3.1 8B and 2B models. Building on the success of the Granite 3.0 series, IBM’s Granite 3.1 introduced significant upgrades, including competitive OpenLLM leaderboard scores, expanded 128K token context length, multilingual support for 12 languages, and enhanced functionality for retrieval-augmented generation (RAG) and agentic workflows. These improvements make Granite 3.1 a versatile, high-performance solution for enterprise applications.
To enhance accessibility and efficiency, we’ve created quantized versions of the Granite 3.1 models. These compressed variants reduce resource requirements while maintaining 99% accuracy recovery, making them ideal for cost-effective and scalable AI deployments. Available options include:
- FP8 Weights and Activations (FP8 W8A8): Optimized for server and throughput-based scenarios on NVIDIA Ada Lovelace and Hopper GPUs.
- INT8 Weights and Activations (INT W8A8): Ideal for servers using NVIDIA Ampere and earlier GPUs.
- INT4 Weight-Only Models (INT W4A16): Tailored for latency-sensitive applications or limited GPU resources.
Extensive evaluations confirm that the up to 3.3X smaller, compressed Granite 3.1 models deliver 99% accuracy recovery, on average, and up to 2.8X better inference performance, as shown in Figure 1 and Figure 2 below. Explore these models, recipes, and full evaluations on Hugging Face, where they are freely available under the Apache 2.0 license.
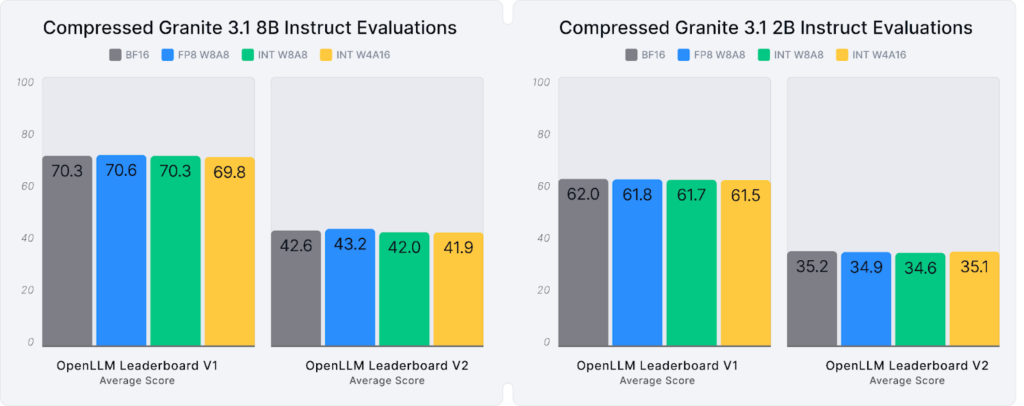
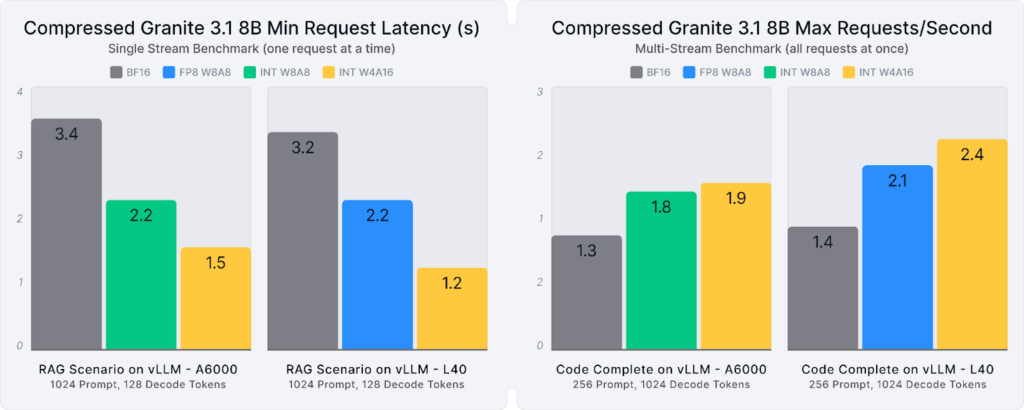
Compressed Granite in Action
The compressed Granite 3.1 models are ready for immediate deployment, integrating seamlessly with the vLLM ecosystem. Developers can quickly start deploying these models, and with LLM Compressor, they can further customize compression recipes to meet specific requirements. Below is a simple example to get started with vLLM:
from vllm import LLM
llm = LLM(model="neuralmagic/granite-3.1-8b-instruct-quantized.w4a16")
prompts = ["The Future of AI is"]
for output in llm.generate(prompts)
print(f"Prompt {output.prompt}, Generated: {output.outputs[0].text}")
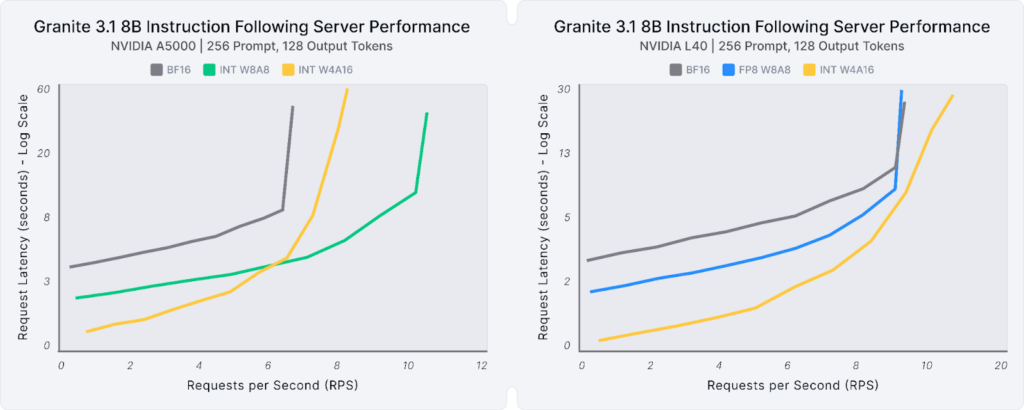
For smaller request sizes, such as instruction-following tasks in agentic pipelines (256 prompt tokens, 128 output tokens), the compressed Granite models consistently deliver performance gains across latency, server, and throughput use cases on various GPUs. Figure 3 illustrates these scenarios for the 8B model deployed on a small A5000 GPU and a medium L40 GPU. Key takeaways from the graph include:
- Single Stream, Latency: W4A16 achieves the highest efficiency with 2.7X (A5000) to 1.5X (L40) lower latency.
- Multi-Stream: W8A8 models perform best (after 6 RPS) on an A5000 enabling 1.6X more requests per second at the same performance, and W4A16 performs best on an L40 enabling up to 8X more requests per second at the same performance.
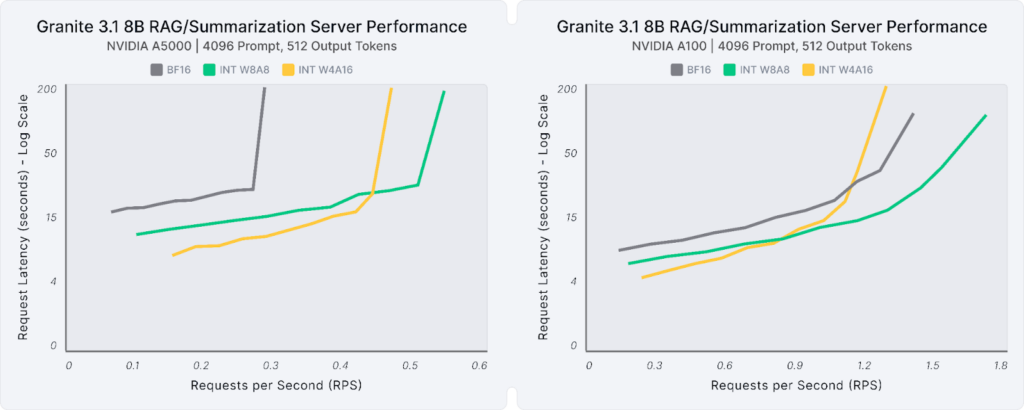
The compressed models provide comparable performance benefits for larger requests, such as retrieval-augmented generation (RAG) or summarization workflows (4096 prompt tokens, 512 output tokens). Figure 4 shows these scenarios for the 8B model on an A5000 GPU and a large A100 GPU. Highlights from the graph include:
- Single Stream, Latency: W4A16 achieves the highest efficiency with 2.4X (A5000) to 1.7X (A100) lower latency.
- Multi-Stream: W8A8 models offer the best performance, enabling up to 4X (A5000) to 3X (A100) more requests at the same performance.
Open and Scalable AI
Neural Magic’s integration into Red Hat marks an exciting new era for open and efficient AI. The compressed Granite 3.1 models and vLLM support exemplify the benefits of combining state-of-the-art model compression, advanced high-performance computing, and enterprise-grade generative AI capabilities.
Explore these models and recipes on Hugging Face, deploy them with vLLM, or customize them using LLM Compressor to unlock tailored performance and cost savings.
Ready to deploy faster, more scalable AI? Contact us to learn more about enterprise solutions or contribute to our open-source journey today!






