

Oct 17, 2024

Author(s)




Quantizing models to lower precision formats, such as 8-bit or 4-bit, significantly reduces computational costs and accelerates inference. However, there has been a persistent question of whether these quantized models retain the same level of accuracy and quality. Recently, the machine learning (ML) community has raised significant concerns about whether quantized large language models (LLMs) can truly compete with their uncompressed counterparts in accuracy and the general quality of generated responses.
In this blog, we address these concerns directly to answer a key question: How much accuracy do we sacrifice when quantizing LLMs? To find out, we conducted over half a million evaluations across various benchmarks, including academic datasets, real-world tasks, and manual inspections, rigorously testing our latest quantized models. Our results revealed several likely sources for the community’s concerns, such as overly sensitive evaluations, models susceptible to the formatting of the chat template, and insufficient hyperparameter tuning in widely used quantization algorithms. By addressing these issues, we have produced highly accurate quantized models that, on average, show no discernible differences from their full-precision counterparts.
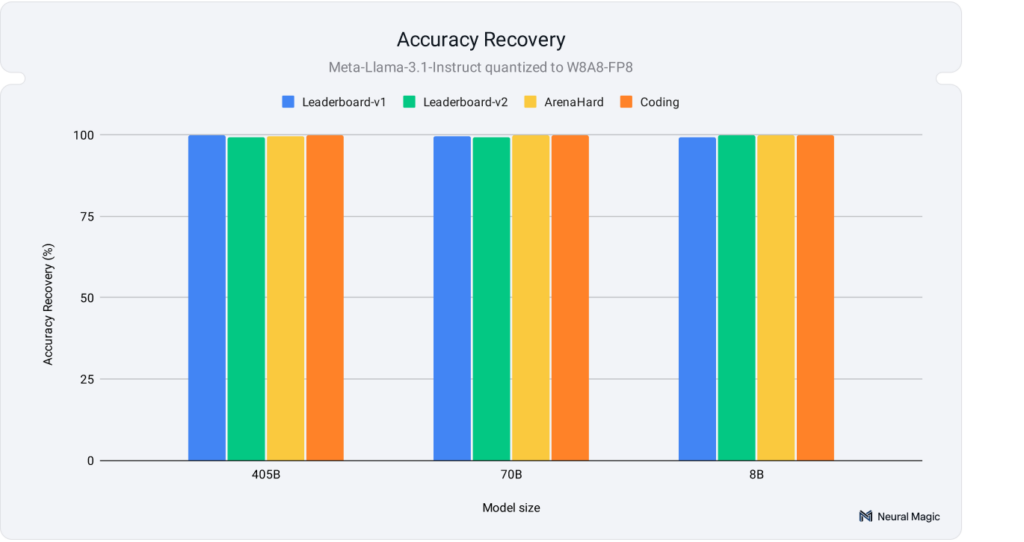
As seen in Figure 1, we achieved full accuracy recovery across various academic and real-world tasks, including the ArenaHard benchmark the community found issues with. Let’s take a closer look!
Exploring Our Approach and Rationale
Our evaluation focused on extensive testing of the Llama 3.1 series of models, which have gained significant traction in research and deployment contexts. With its streamlined and efficient base architecture, Llama 3.1 is an ideal candidate for assessing various quantization schemes.
For each Llama 3.1 size (8B, 70B, and 405B), we tested three distinct quantization schemes alongside the baseline 16-bit model. These schemes were selected to accommodate different hardware and deployment requirements, and all performance claims were validated using vLLM (0.6.2):
- W8A8-INT: This quantization scheme reduces weights and activations to 8-bit integer values, making it ideal for server or throughput-based deployments on Nvidia Ampere (A100 GPUs) and older hardware. It provides approximately 2x model size compression and delivers an average 1.8x performance speedup across various server (multi-request) scenarios.
- W8A8-FP: This quantization scheme uses an 8-bit floating point format for weights and activations rather than integer values. This simplifies the compression process but is supported only on the latest Nvidia Hopper (H100 GPUs) and Ada Lovelace hardware. It provides approximately 2x model size compression and delivers an average 1.8x performance speedup across various server (multi-request) scenarios.
- W4A16-INT: In this scheme, weights are quantized to 4-bit integers while the activations remain at 16-bit precision. This approach is optimal for latency-critical applications and edge use cases where model size and single request response time are key factors. This means that the model inference is dominated by memory access for loading the weights instead of compute-intensive operations. In this regime, W4A16 provides approximately 3.5x model size compression and delivers an average speedup of 2.4x for single-stream scenarios.
Each quantized model was created by optimizing hyperparameter and algorithmic choices on the OpenLLM Leaderboard v1 benchmarks and then evaluated across many other benchmarks to ensure it generalizes across diverse scenarios. The best choices varied by model and scheme but comprised some combination of SmoothQuant, GPTQ, and/or standard round-to-nearest quantization algorithms. Detailed documentation for each model, including the specific approaches used, can be found in the model cards available in our HuggingFace collection.
We designed our evaluation suite to cover a broad spectrum of inference scenarios and use cases, providing a comprehensive analysis across multiple model sizes and quantization schemes:
- Academic Benchmarks: These benchmarks, such as OpenLLM Leaderboard v1 and v2, are key for evaluating research developments and model improvements. They focus on structured tasks like question-answering and reasoning, providing consistent and easily validated accuracy scores. However, they often fail to reflect real-world scenarios where semantics, variability, and context are critical.
- Real-World Benchmarks: Unlike academic benchmarks, real-world benchmarks test models in scenarios that mimic human usage, such as instruction following, chat, and code generation. These benchmarks include ArenaHard and HumanEval, which offer a broader range of tasks with higher variation but better reflect real-world model performance. These benchmarks provide a more comprehensive view of models' performance in live environments.
- Text Similarity: Text similarity measures how closely quantized models’ outputs match their unquantized counterparts. Metrics such as ROUGE, BERTScore, and Semantic Textual Similarity (STS) evaluate the semantic and structural consistency, ensuring that the generated text's intended meaning and quality are preserved.
With this extensive evaluation framework, we ensured that deployment scenarios ranging from structured, research-driven tasks to open-ended, real-world applications were covered, providing a holistic view of the performance and capabilities of quantized LLMs.
Academic Benchmark Performance
Academic benchmarks are an excellent starting point for evaluating language models’ accuracy and reasoning capabilities. They provide structured tasks, making them essential for comparing models on well-defined criteria. Our evaluations focused on OpenLLM Leaderboard v1 and v2, ensuring consistent results across both older and newer, more challenging benchmarks. Additionally, testing on both allowed us to prevent overfitting to v1, where we optimized our quantization hyperparameters.
We evaluated OpenLLM Leaderboard v1 by utilizing Meta’s prompts for the Llama-3.1 models. We base our comparisons and recovery percentages on the average score and report a full per-task breakdown of results in our HuggingFace model collection. The Leaderboard v1 benchmark consists of a diverse range of topics, including:
- Grade school math: GSM8k
- World knowledge and reasoning: MMLU, ARC-Challenge
- Language understanding: Winogrande, HellaSwag
- Truthfulness: TruthfulQA.
As illustrated in Figure 2 (left) below, all quantization schemes—regardless of model size—recover over 99% of the average score achieved by the unquantized baseline.
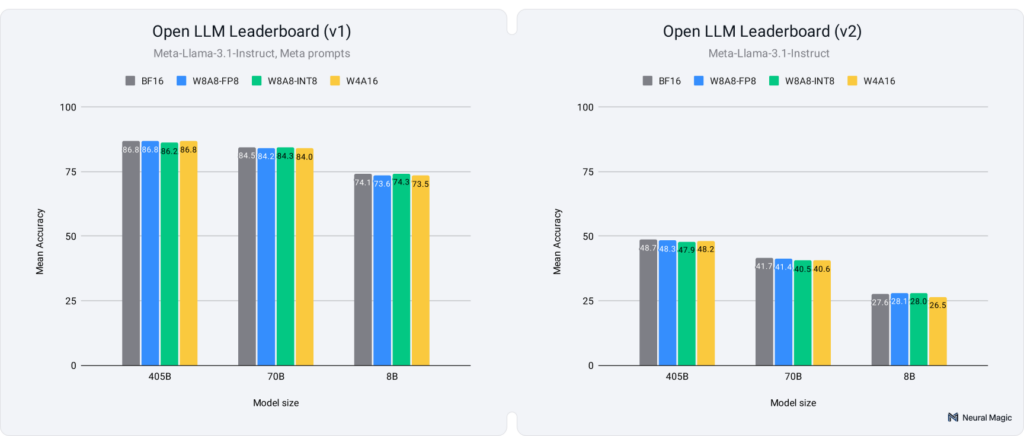
The community has evolved, and with it, so have the benchmarks. As scores began to plateau on v1, OpenLLM Leaderboard v2 was introduced to push models further, offering more challenging tasks that test deeper reasoning and knowledge capabilities. Like v1, we measured the recovery percentages based on the average scores across the v2 benchmarks (full results in our HuggingFace model collection). The benchmarks in v2 include more complex topics, such as:
- Expert knowledge and reasoning: MMLU-Pro, GPQA, Big Bench Hard
- Multistep reasoning: MuSR
- Advanced math problems: MATH Level 5
- Instruction following: IFEval.
As illustrated in Figure 2 (right) above, the quantized models recover close to 99% of the baseline’s average score on average, with all models maintaining at least 96% recovery. However, the increased difficulty of these tasks, especially for smaller models, resulted in higher variance for benchmarks like GPQA and MuSR, where scores approached the random guessing threshold even for the full-precision baseline. This led to more variability in the quantized versions' scores and a lack of a clear signal for accuracy recovery.
Real-World Benchmark Performance
While academic benchmarks provide structured evaluations, real-world open-ended benchmarks better represent how models perform in dynamic environments like human-chat interactions or coding tasks. These benchmarks test models on varied prompts with longer generations and multiple potential solutions, focusing on responses' correctness and semantic quality. Our evaluations targeted three key real-world benchmarks: Arena-Hard, HumanEval, and HumanEval+, which measure performance in chat, instruction-following, and code generation.
The LMSYS Chatbot Arena has established itself as a leading benchmark for LLMs, assessing how models align with human preferences. Arena-Hard Auto is an automated extension of this benchmark, where an LLM judges responses to 500 complex prompts on various topics. It has demonstrated a strong correlation with human evaluations, achieving a state-of-the-art 89% agreement with human preference rankings.
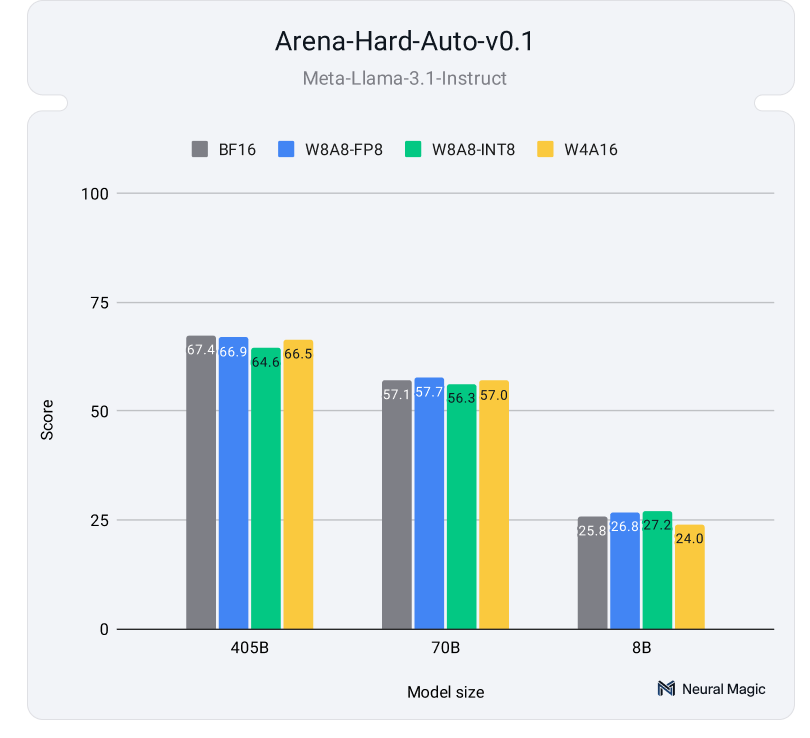
Figure 4 shows how well-quantized models compare to their full-precision counterparts on the Arena-Hard-Auto benchmark, averaging results from two evaluation runs per model. The results illustrate that the response quality of quantized models remains highly competitive with their unquantized counterparts. As shown in the detailed results on our HuggingFace Hub, the 95% confidence intervals overlap for all model sizes and quantization schemes, highlighting the minimal impact on accuracy.
In addition to chat-based interactions, LLMs are widely deployed as coding assistants. To evaluate the performance of quantized models in code generation, we tested them on HumanEval and its more challenging variant, HumanEval+. These benchmarks measure a model’s ability to generate correct and functional code based on programming problems, with HumanEval+ introducing more complex, multi-step tasks requiring deeper reasoning and problem-solving. Figure 5 below presents the pass@1 scores obtained using the EvalPlus library.
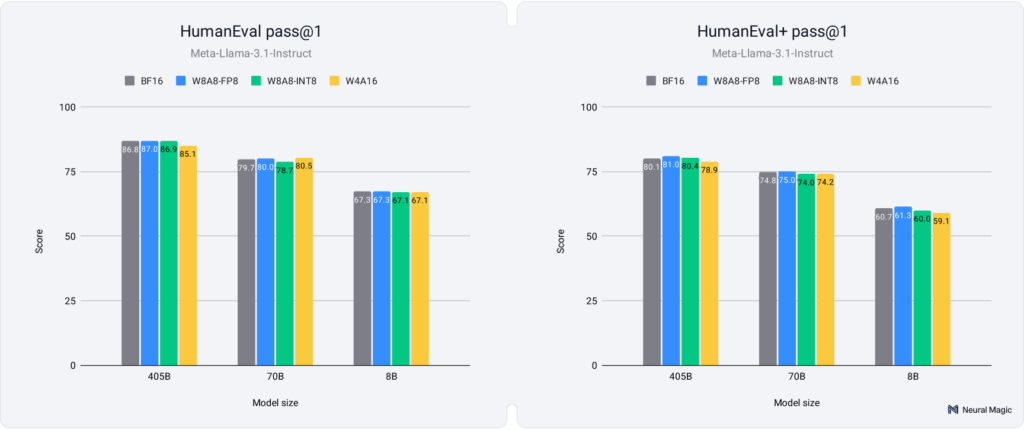
As illustrated in Figure 5, quantized models demonstrate exceptional performance on both HumanEval and HumanEval+, with 8-bit models achieving 99.9% accuracy recovery and 4-bit models recovering 98.9%. These results highlight that quantized models not only maintain high performance in simpler coding tasks but also excel in more complex scenarios, proving their reliability for real-world coding applications with minimal loss in accuracy.
Text Similarity and Manual Inspection
After evaluating quantized models across various academic and real-world benchmarks, we put them through the final test: How similar is the text generated by quantized models compared to their unquantized counterparts?
We used four key metrics to answer this:
- ROUGE-1 measures word-level overlap between outputs of quantized and unquantized models.
- ROUGE-L captures structural similarity by focusing on the longest common subsequence.
- BERTScore evaluates the contextual similarity at the token-level.
- STS assesses overall semantic similarity at the sentence level.
These metrics were computed across responses generated from the ArenaHard prompts, allowing us to analyze how well-quantized models preserve the meaning and structure of outputs compared to full-precision models. The results are summarized in Figure 6 below.
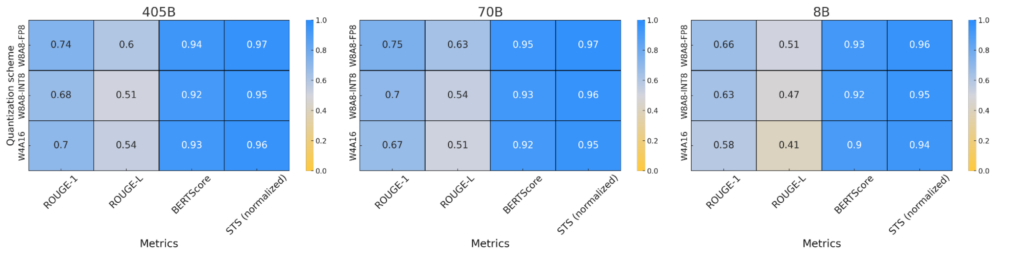
The results show that larger quantized models (70B and 405B) maintain a high degree of text similarity to their full-precision counterparts, with ROUGE-1 and ROUGE-L scores indicating strong preservation of word choice and structure. BERTScore and STS further confirm that the overall meaning remains consistent, even with slight token variations introduced by quantization. While 8B models exhibit more variability in word selection, they still preserve the core semantic meaning as shown in the BERTScore and STS results. This demonstrates that quantized models maintain high-quality output across all model sizes and quantization schemes.
So far, we’ve evaluated the performance of quantized models using a variety of benchmarks and comparison metrics distilled into raw numbers. Now, it’s time to see the results for yourself. Our interactive demo app (built on top of the fantastic HuggingFace Spaces) lets you select different models and quantization schemes to compare generated responses side-by-side with their full-precision counterparts. This tool offers an intuitive way to visually assess how quantization affects model outputs and the quality of the generated text.
If the interactive demo isn't rendering nicely in your browser, visit our HuggingFace Space for a smoother UI experience: https://huggingface.co/spaces/neuralmagic/quant-llms-text-generation-comparison.
Why Quantization is Here to Stay
In conclusion, our comprehensive evaluation demonstrates that quantized models maintain impressive accuracy and quality compared to their full-precision counterparts, making them an essential tool for optimizing LLMs in real-world deployments.
- Consistent Performance: 8-bit and 4-bit quantized LLMs show very competitive accuracy recovery across diverse benchmarks, including Arena-Hard, OpenLLM Leaderboards v1 and v2, and coding benchmarks like HumanEval and HumanEval+.
- Minimal Trade-offs: Larger models (70B, 405B) show negligible performance degradation. In comparison, smaller models (8B) may experience slight variability but still preserve their outputs' core semantic meaning and structural coherence.
- Efficiency and Scalability: Quantization provides significant computational savings and faster inference speeds while maintaining the semantic quality and reliability of responses.
These findings confirm that quantization offers large benefits in terms of cost, energy, and performance without sacrificing the integrity of the models. As LLMs grow in size and complexity, quantization will play a pivotal role in enabling organizations to deploy state-of-the-art models efficiently.
Ready to explore how quantized LLMs can enhance your business's efficiency and performance? Connect with our experts to discuss enterprise solutions tailored to your needs.






