
Jul 15, 2022

Author(s)

Compress BERT-Large with pruning and quantization to create a version that maintains accuracy while beating baseline DistilBERT performance and compression
In 2019, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, a research paper from Google research, introduced two versions of a transformative new NLP model: BERT-base and BERT-Large. Both were transformer-based architectures pre-trained on a relatively sizable text corpus, yet the base model has seen much greater adoption despite BERT-Large's higher accuracy. Looking at Hugging Face downloads alone, BERT-base receives roughly 15 times more with over 15 million downloads in May of 2022. The reasons underlying this trend become clearer as soon as you start working with the models – unoptimized BERT-Large inferences are 4.5x slower and require over 1GB in disk space. For an already computationally expensive NLP approach, the extra accuracy from BERT-Large generally doesn’t justify the additional expense.
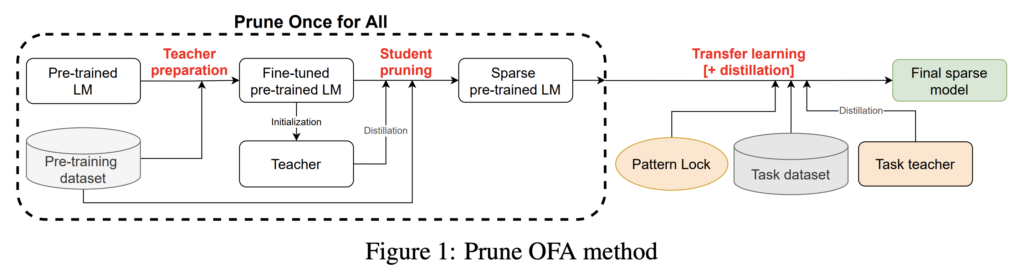
Given BERT-Large’s sizable increase over the baseline model, an intriguing question arises: how many of those parameters are required for natural language processing? Intel’s research team dove into this question in Prune Once for All: Sparse Pre-Trained Language Models. For BERT-Large, they found that 90% of the network could be pruned away with minimal effect on the accuracy. To achieve this, pruning and distillation were combined while pre-training to create general, sparse architectures that are finetuned and quantized onto datasets for standard tasks such as SQuAD for question answering. The results are highly compressed networks that closely match the accuracy of the unoptimized versions. Intel has released the Prune OFA models on the Hugging Face model repository as part of their research.
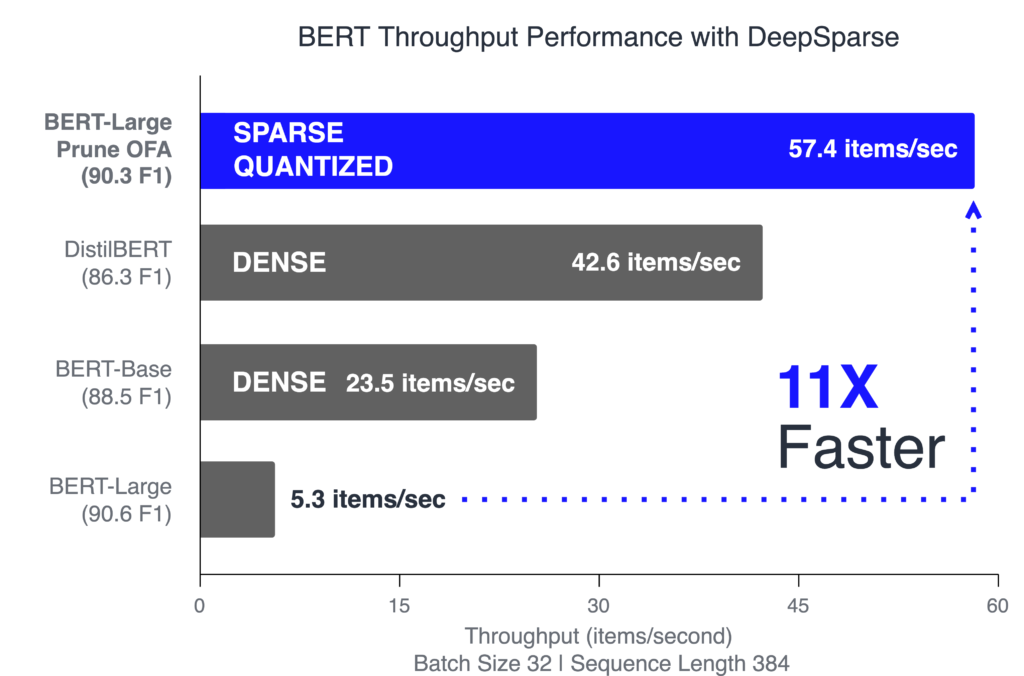
Deploy with DeepSparse for a 11x Increase in Performance
Note, the results reported below are for the SQuAD dataset. However, these results carry over to other datasets and tasks that can be found on the SparseZoo.
The freely available DeepSparse Engine is specifically engineered to speed up sparse and sparse-quantized networks. It leverages sparsity to reduce the overall compute and exploit the CPU's large caches for faster memory access. The combination of these two technologies leads to GPU-class performance on commodity CPUs. Combining DeepSparse with the Prune Once for All sparse-quantized models yields 11x better performance in throughput and 8x better performance for latency-based applications, beating BERT-base and achieving DistilBERT level performance without sacrificing accuracy.
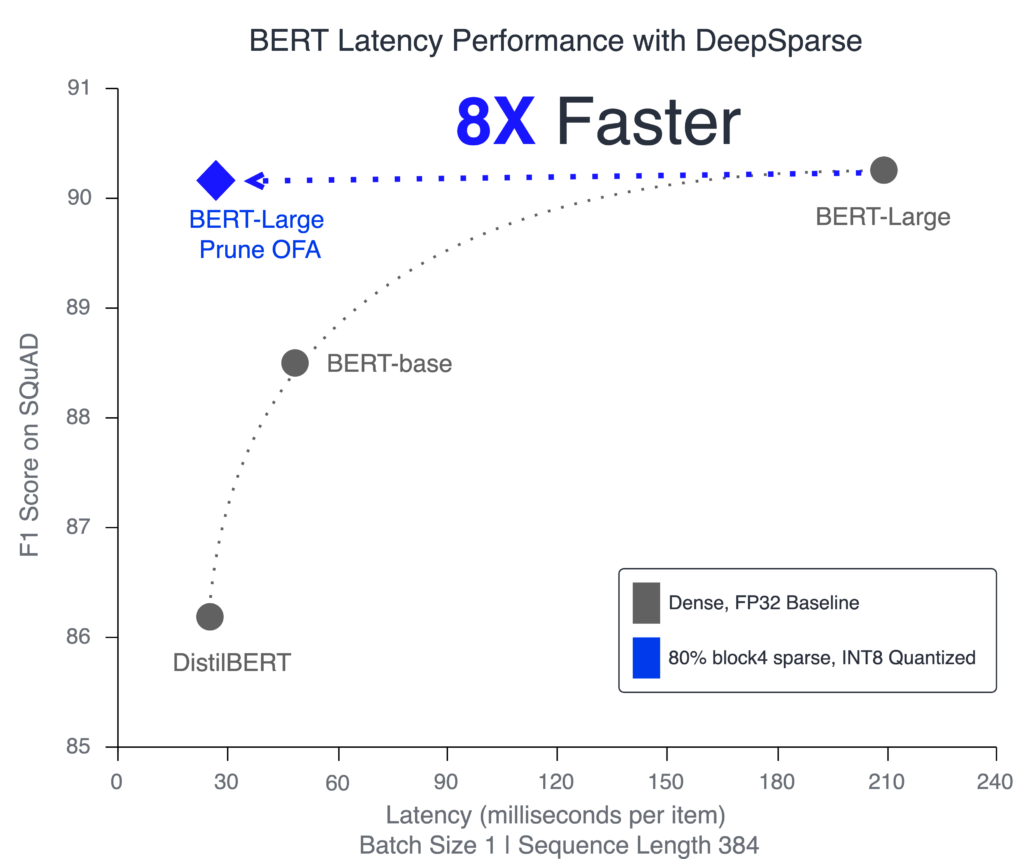
The graph above highlights the relationship between networks for scaling their structured size vs. sparsifying them to remove redundancies. The performant DistilBERT model has the least number of layers and channels and the lowest accuracy. With more layers and channels added, BERT-base is less performant and more accurate. Finally, BERT-Large is the most accurate with the largest size but the slowest inference. Despite the reduced number of parameters, the sparse-quantized BERT-Large is close in accuracy to the dense version and inferences 8x faster. So, while the larger optimization space helped when training, not all of these pathways were necessary to maintain accuracy. The redundancies in these larger networks surface even more when comparing the file sizes necessary to store these models, as shown in the graph below.

Apply Your Data to these Results
Neural Magic has partnered with Intel’s research team to open-source the algorithms, models, recipes, and code so you can leverage this research for your own data and deployments. The algorithms and code are available in SparseML – install and start using command-line integrations immediately in your terminal. The models and recipes are available on SparseZoo – where the recipes encode all of the hyperparameters necessary to replicate and transfer this research onto your data.
As an example, follow the steps below to replicate the results published above for SQuAD for training and deployment.
1. Install SparseML and DeepSparse
pip install sparseml[torch] deepsparse[server]2. Train the Sparse Model with a Teacher
sparseml.transformers.train.question_answering \
--output_dir bert_large_uncased-squad \
--model_name_or_path zoo:bert-large-wikipedia_bookcorpus-pruned80.4block_quantized \
--distill_teacher zoo:nlp/question_answering/bert-large/pytorch/huggingface/squad/base-none \
--recipe zoo:nlp/question_answering/bert-large/pytorch/huggingface/squad/pruned80_quant-none-vnni \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 32 \
--gradient_accumulation_steps 4 \
--preprocessing_num_workers 6 \
--max_seq_length 384 \
--doc_stride 1283. Deploy in the DeepSparse Server
deepsparse.server --task question_answering --batch_size 1 --model_path bert_large_uncased-squadCredits
This blog was made in conjunction with Ofir Zafrir and Guy Boudoukh from Intel Labs and special thanks to them for their great comments and collaboration.






