
Jul 11, 2022

Author(s)

This blog post was edited in July 2022 to reflect more-recent sparsification research, software updates, better performance numbers, and easier benchmarking and transfer learning flows.
In this post, we elaborate on how we sparsified ResNet-50 models up to 95% while retaining 99% of the baseline accuracy. Furthermore, we’ll show how we used these sparsified models to achieve GPU-class throughput and latency performance on commodity cloud CPUs. By the end of the post, you should be able to reproduce these benchmarks, apply your data via transfer learning, and deploy on CPUs at GPU speeds using free and open-source tools available in the Neural Magic GitHub repo.
Intro to Sparsification: Pruning ResNet-50
Neural Magic’s Deep Sparse Platform provides a suite of software tools to select, optimize, and deploy sparse deep learning models on commodity CPU resources. Taking advantage of “sparsification,” there are multiple ways to plug into the DeepSparse Engine which runs sparse models like ResNet-50 at accelerated speeds on CPUs. So what is sparsification and why should you care?
Sparsification is the process of taking a trained deep learning model and removing redundant information from the overprecise and over-parameterized network resulting in a faster and smaller model. Techniques for sparsification are all-encompassing including everything from inducing sparsity using pruning and quantization to enabling naturally occurring activation sparsity. When implemented correctly, these techniques result in significantly more performant and smaller models with limited to no effect on the baseline metrics. For example, as you will see shortly in our benchmarking exercise, pruning plus quantization can give over 7.3x improvement in performance while recovering to nearly the same baseline accuracy. Additionally, sparsification also reduces the model footprint. In the ResNet-50 example below, we reduced the model size from the original 90.3 MB to 3.3 MB while retaining 99% of the baseline accuracy!
The DeepSparse Platform builds on top of sparsification enabling you to easily apply the techniques to your datasets and models using recipe-driven approaches. Recipes encode the directions for how to sparsify a model into a simple, easily editable format. Simply put, you would:
- Download a sparsification recipe and sparsified model from the SparseZoo.
- Apply the recipe to the model with only a few lines of code using SparseML.
- Finally, for GPU-level performance on CPUs, you can deploy your sparse-quantized model with the freely-available DeepSparse Engine.
ResNet-50 on CPUs: Benchmarking with the DeepSparse Engine
Approach
We started with the standard, dense ResNet-50 model and applied SOTA training-aware sparsification techniques using SparseML recipes. Specifically, we utilized the AC/DC pruning method – an algorithm developed by IST Austria in partnership with Neural Magic. This new method enabled a doubling in sparsity levels from the prior best 10% non-zero weights to 5%. Now, 95% of the weights in a ResNet-50 model are pruned away while recovering within 99% of the baseline accuracy.
| Sparsification | Precision | SparseZoo Model Stub |
| Dense | FP32 | zoo:cv/classification/resnet_v1-50/pytorch/sparseml/imagenet/base-none |
| Pruned95 | FP32 | zoo:cv/classification/resnet_v1-50/pytorch/sparseml/imagenet/pruned95-none |
| Pruned85 | INT8 | zoo:cv/classification/resnet_v1-50/pytorch/sparseml/imagenet/pruned85_quant-none-vnni |
Hardware Setup and Environment
The DeepSparse Engine is completely infrastructure-agnostic, meant to plug in from edge deployments to model servers.
For this exercise, these benchmarks have been run on an AWS c5.12xlarge instance that has a modern Intel CPU with support for AVX-512 Vector Neural Network Instructions (AVX-512 VNNI). It is designed to accelerate INT8 workloads, making up to 4x speedups possible going from FP32 to INT8 inference.
We used Ubuntu 20.04.1 LTS as the operating system with Python 3.8.5. All the benchmarking dependencies are contained in DeepSparse Engine, which can be installed with:
pip3 install deepsparseMore details about DeepSparse Engine and compatible hardware are available.
Benchmark Measurements
Keeping this as simple as possible, the benchmark measures the full end-to-end time of giving an input batch to the engine and receiving predicted output, with full FP32 precision.
We perform several warm-up iterations before measuring the time for each iteration to minimize noise affecting the final results.
Here is the full-timing section from deepsparse/engine.py
start = time.time()
out = self.run(batch)
end = time.time()ResNet-50 v1 Throughput Results
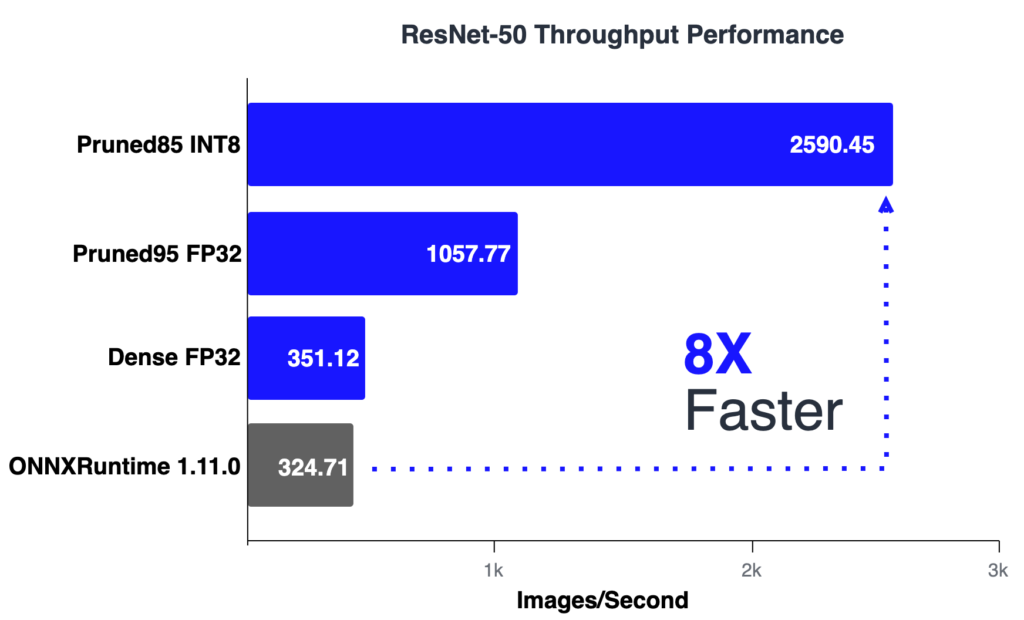
For the throughput scenario, we used a batch size of 64 with random input using all available cores.
| Batch 64 | items/sec | ms/batch |
| ONNXRuntime 1.11.0 | 324.71 | 197.08 |
| Dense FP32 | 351.12 | 182.26 |
| Pruned95 FP32 | 1057,77 | 60.49 |
| Pruned85 INT8 | 2590.45 | 24.69 |
This CLI command replicates the benchmark environment, where SPARSEZOO_MODEL_STUB is replaced from the table above.
deepsparse.benchmark
zoo:cv/classification/resnet_v1-50/pytorch/sparseml/imagenet/pruned85_quant-none-vnni --batch_size 64 --scenario syncResNet-50 v1 Latency Results
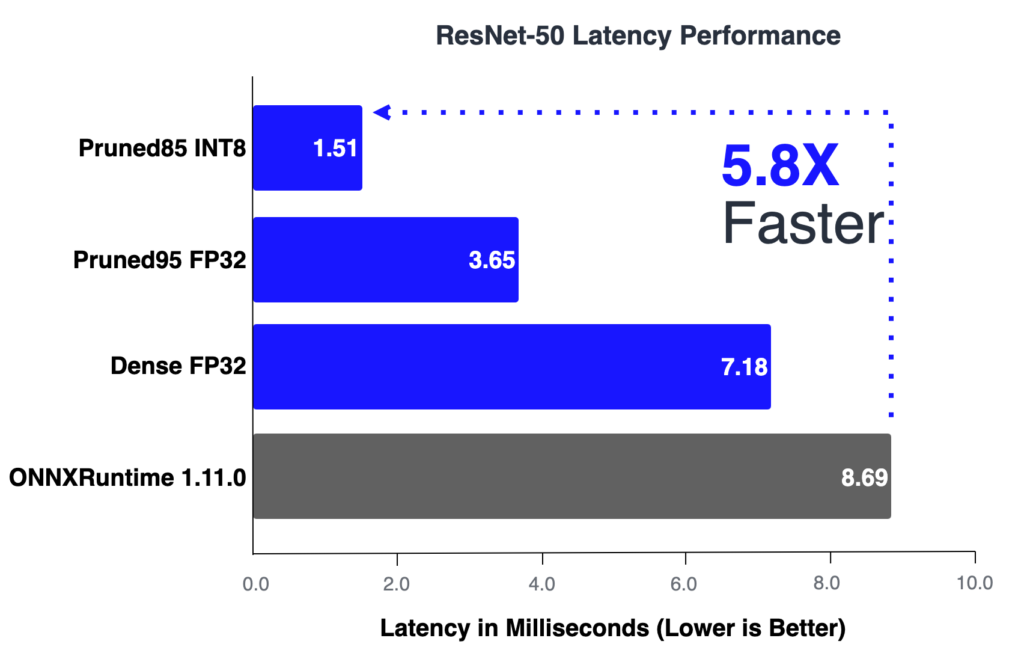
For the latency scenario, we used a batch size of 1 with random input using all available cores.
| Batch 1 | items/sec | ms/batch |
| ONNXRuntime 1.11.0 | 114.88 | 8.69 |
| Dense FP32 | 138.85 | 7.18 |
| Pruned95 FP32 | 273.38 | 3.65 |
| Pruned85 INT8 | 656.91 | 1.51 |
Try it Now: Benchmark ResNet-50
To replicate this experience and results, here are the instructions. Once you have procured infrastructure, it should take you approximately 5 minutes to run through this exercise.
- Reserve a c5.12xlarge instance on AWS; we used the Amazon Ubuntu 20.04 AMI
- Install the DeepSparse Engine by running
pip3 install deepsparse - Run the CLI command for benchmarking:
deepsparse.benchmark [zoo model stub] --batch_size 64 --scenario sync
ResNet-50 on CPUs Next Step: Transfer Learn
You can apply your data to sparse-quantized ResNet-50 models with a few lines of code using SparseML. To do so, visit our example in GitHub.
Conclusions
Sparse-quantized models like our ResNet-50 models provide attractive performance results for those with image classification and object detection use cases. With tools readily available in GitHub, as you can see from the results, leveraging models that use techniques like pruning and quantization, can achieve speedups upwards of 7.3x when using the DeepSparse Engine with compatible hardware.
These noticeable wins do not stop there with ResNet-50. Neural Magic is constantly pushing the boundaries of what’s possible with sparsification on new models and datasets across computer vision and NLP domains. The results of these advancements are pushed into our open-source repos for all to benefit.
Resources and Learning More
- Software used in benchmarking: SparseML, DeepSparse Engine
- Sparse Transfer Learning with SparseML
- Join the Deep Sparse Community in Slack to get direct access to our engineering teams and other people looking to accelerate ML performance.
- Subscribe to Neural Magic Updates: Nerd out with us on ML Performance! (We keep the email manageable and do not share your details with anyone, ever.)






