Nov 01, 2022

Author(s)


The world of finance and stock trading has changed in recent years. As more and more retail investors enter the market, the more important stories and social sentiment become. Think Tesla - one can argue that a lot of the company's value comes from successful social storytelling by its CEO Elon Musk. Social media has the power to turn a bull into a bear and a bear into a bull. Classifying finance tweets using NLP to understand social sentiment is increasingly more important.
Running multiple machine learning models in a low-latency environment is paramount for many real-world deployments in finance. Successful high-frequency trading requires having accurate and fast decision engines, with the ultimate objective of leveraging machine learning models for identifying and quantifying risk in the market at millisecond speeds.
This is where sparsity comes in. Sparsity is a technique of optimizing models for size and speed without impacting the model accuracy. Given the heavy deployment of the latest state-of-the-art transformers, sparsification of these models is a prerequisite for many deep learning use-cases in financial trading. By sparsifying a dense BERT model, you can eliminate 90% of the model weights, making the model smaller, faster, and easier to execute. In combination with the DeepSparse Engine, which executes sparse models faster, you can save a lot of resources while delivering a faster and equally accurate performance.
In this blog, we’ll learn to sparsify and deploy two transformer models for the task of classifying finance-related tweets in a real-time streaming scenario. Specifically we’ll:
- Profile two new open-sourced finance tweet datasets to familiarize ourselves with data sources and labeling for finance classification.
- Train accurate and optimized models using sparse transfer learning to convert dense models into sparse variants.
- Load our models and run inference via the DeepSparse Pipelines on a real-time Twitter stream, using commodity CPUs while still achieving GPU-class speeds.
We’ll be using code from the SparseStream example directory found in the DeepSparse GitHub repository.
Classifying Finance Tweets using Twitter Financial News Dataset
We will train two BERT-base-uncased models on our open-sourced Twitter Financial News dataset for sequence classification. One model will be trained to classify each tweet as either “Bullish”, “Bearish” or “Neutral” sentiment. The other will be trained to classify the topic of each tweet with a total of 20 labels.
Here is a breakdown of each class document count and total sample size:
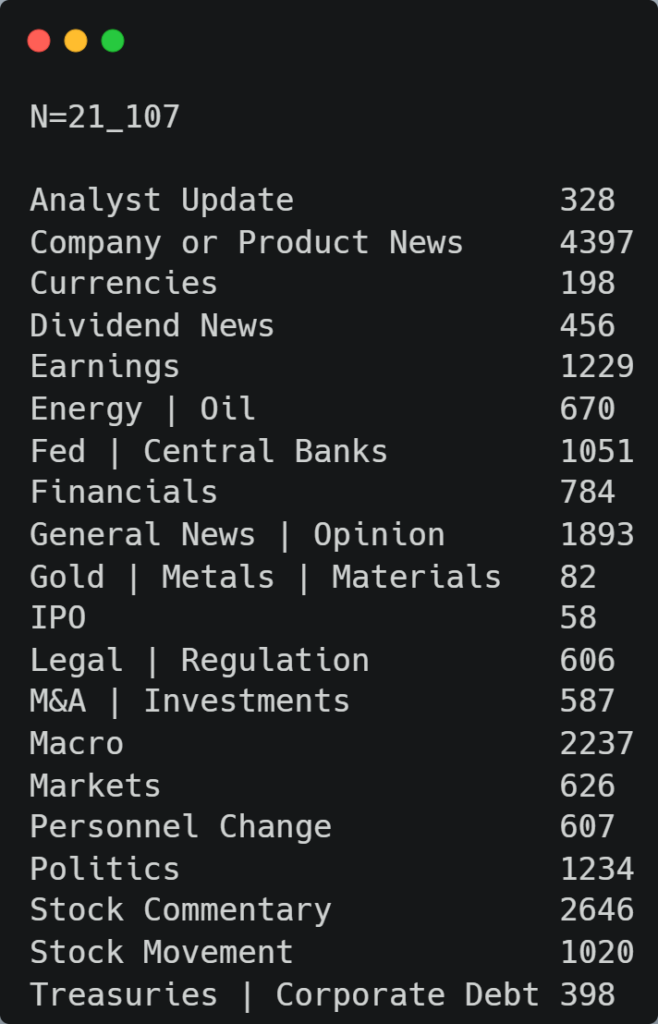
Our topic classification dataset has a total of 21,107 documents, while the sentiment classification dataset has a total of 11,932 documents.
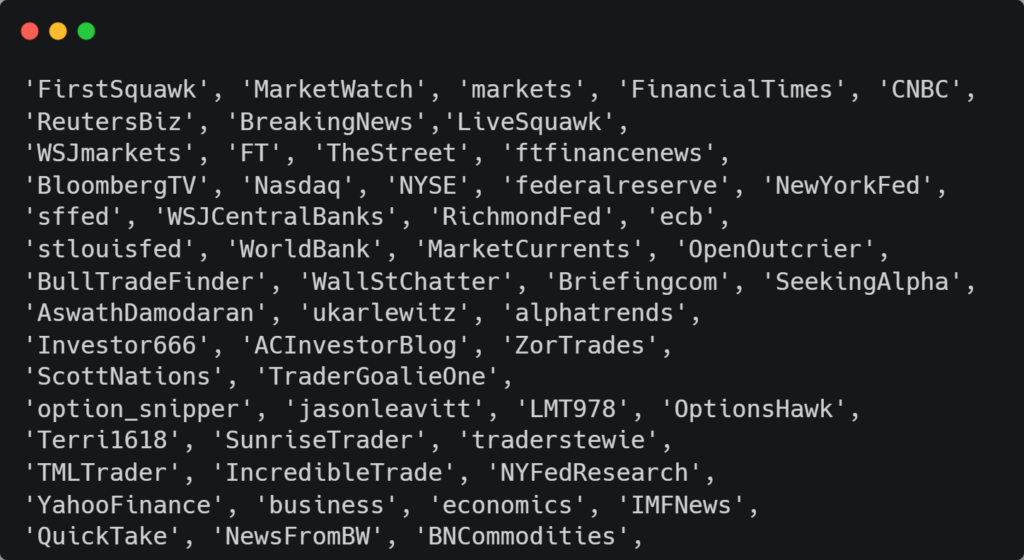
The dataset encompasses tweets from various Twitter sources ranging from established media companies such as Bloomberg and CNBC to private traders Antonio Costa (@ACInvestorBlog) and Gnotz (Bull) (@BullTradeFinder) to get a range of different tweets and enough language heterogeneity for models to be able to successfully handle differing syntax. Simply put, we want our models to be able to understand informal syntax from traders’ tweets but also from more formal syntax as tweeted by media outlets.
Classifying Finance Tweets: Sparse-Transfer Learning
pip install sparseml[torch]We will first fine-tune our dense BERT models on our new datasets as normal. We can begin our Transformers training with a SparseML training CLI command (this snippet is for topic classification):
sparseml.transformers.train.text_classification \
--output_dir dense_topic \
--model_name_or_path zoo:nlp/masked_language_modeling/bert-base/pytorch/huggingface/wikipedia_bookcorpus/base-none \
--dataset_name zeroshot/twitter-financial-news-topic \
--max_seq_length 160 \
--per_device_train_batch_size 32 \
--per_device_eval_batch_size 64 \
--preprocessing_num_workers 8 \
--do_train \
--do_eval \
--evaluation_strategy steps \
--eval_steps 200 \
--learning_rate 2e-5 \
--max_steps 2400 \
--fp16 \
--seed 42 \
--save_strategy steps \
--save_steps 200 \
--save_total_limit 3 \
--overwrite_output_dir \
--load_best_model_at_endAfter training for both tasks, our dense sentiment analysis model gets an accuracy of 87.5 and the topic classification model gets an accuracy of 90.8 with a latency (batch size=1) of 30.3ms and 30.2ms, respectively on c6i.8xlarge instance on AWS.
With the dense models trained, we can now distill them into a sparse student model by using a recipe for sparse transfer learning. Sparse transfer learning enables an easy pathway for creating performant models on your datasets. Like with dense transfer learning, sparse transfer learning works by pre-training a generalized sparse architecture on a large dataset and then fine-tuning onto another, downstream datasets. This process enables smaller models that can be deployed for cheaper and faster inferences without worrying about the hyperparameters involved in sparsifying a model from scratch for each task.
The following recipe shows what we used to transfer learn the dense to the sparse student model and all of its configurations, which includes quantization:
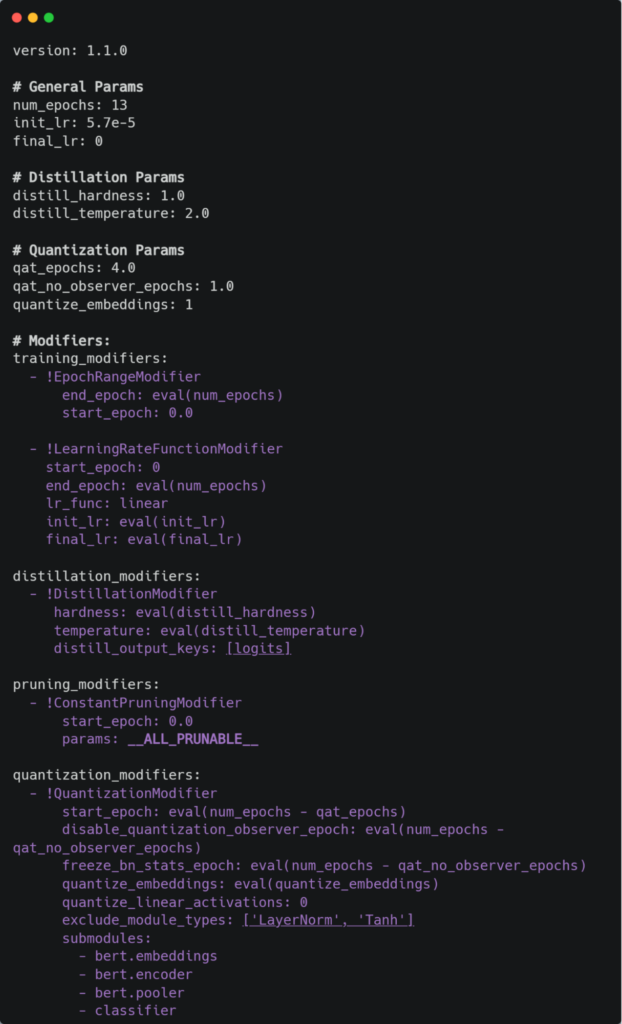
In order to start our sparse transfer learning, we want to first choose a masked language model from the Neural Magic SparseZoo trained on the MNLI dataset in order to be used for text classification. We’ll use the 80% Pruned, Quantized BERT base uncased upstream model. This model was sparsified to use the VNNI instructions on the newer x86 CPUs which will give us blazing-fast model performance thanks to native INT8 arithmetic support.
To start transfer learning from our dense models please use the following SparseML training CLI command (this snippet is for topic classification):
sparseml.transformers.train.text_classification \
--output_dir sparse-topic \
--model_name_or_path zoo:nlp/masked_language_modeling/bert-base/pytorch/huggingface/wikipedia_bookcorpus/pruned80_quant-none-vnni \
--distill_teacher zoo:nlp/text_classification/bert-base/pytorch/huggingface/twitter_financial_news_topic/base-none \
--recipe zoo:nlp/text_classification/bert-base/pytorch/huggingface/twitter_financial_news_topic/pruned80_quant-none-vnni \
--dataset_name zeroshot/twitter-financial-news-topic \
--do_train \
--do_eval \
--eval_steps 200 \
--max_seq_length 160 \
--evaluation_strategy steps \
--per_device_train_batch_size 32 \
--per_device_eval_batch_size 64 \
--preprocessing_num_workers 16 \
--fp16 \
--seed 42 \
--save_strategy steps \
--save_steps 200 \
--save_total_limit 3 \
--overwrite_output_dir \
--load_best_model_at_endFor this training run on a single V100 GPU, we will re-use the same datasets we used for the dense model training and run our training job.
After training is complete, we can export our PyTorch models to ONNX format with the following CLI command:
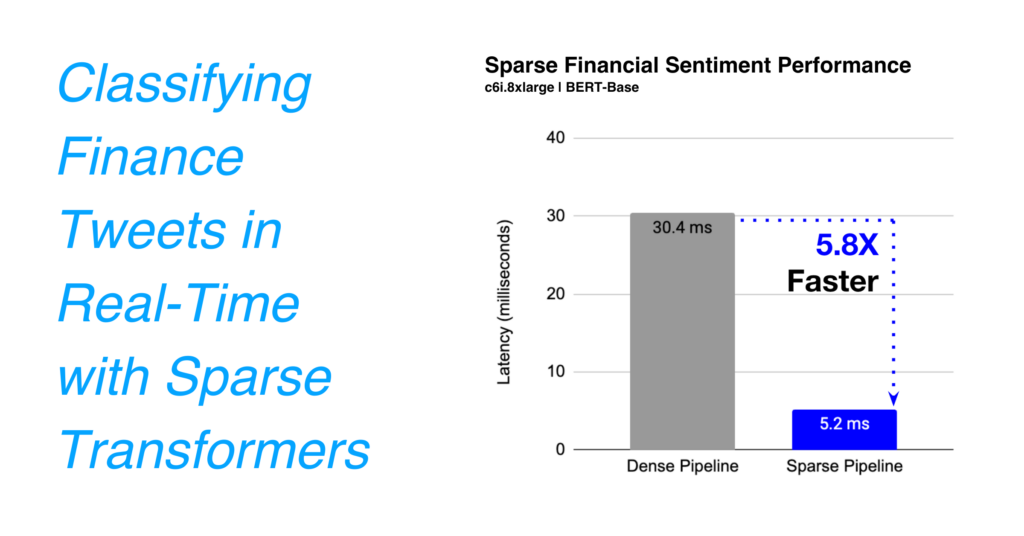
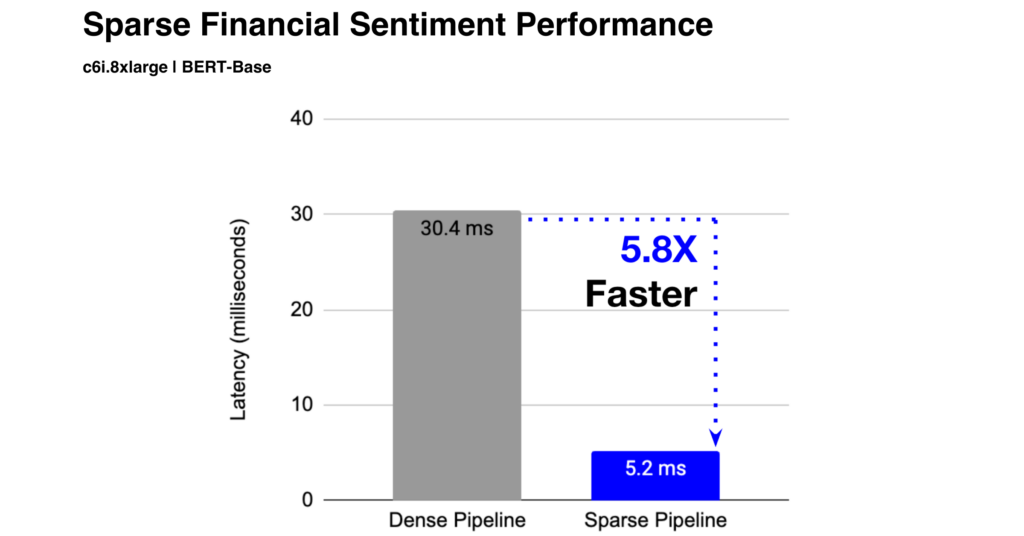
sparseml.transformers.export_onnx --model_path <full_model_path> --task 'text_classification' --sequence_length 160After converting to ONNX, we can now benchmark our new sparse models vs their dense versions and we see a significant improvement in speed-up: 30.4ms vs. 5.2ms on a c6i.8xlarge instance (w/ VNNI support). The sparse models are 6X faster than their dense counterparts!
Inference on a Twitter Stream
After our two BERT models have been sparse-transferred, we’re now ready to deploy our models in a real-time asynchronous Twitter stream!

Our SparseStream class is able to call the streaming Twitter API and pass the incoming tweets into the `sentiment_analysis’ and ‘topic_classification’ pipelines. In order to get access to the Twitter API, you will need to get access to the consumer key, consumer secret, access token and access token secret which you’ll receive after applying for a Twitter app via the Twitter developer site. Access to these tokens are free and the only requirement one needs is to own a Twitter account. After getting approved by Twitter for your app, generate and paste the 4 tokens to the config.yaml file.
Now that we have our tokens to access the Twitter API and our two model paths, we can download our SparseStream repo with the following commands:
git clone https://github.com/neuralmagic/deepsparse.git
cd deepsparse/examples/sparsestream
pip install -r requirements.txtAnd finally, to start streaming Twitter, run the stream.py file:
python stream.pyAfter executing the stream.py file, the Twitter API begins streaming in your terminal window and incoming tweets are immediately passed into the DeepSparse pipelines that classify them for sentiment and topic. To watch an example of a live Twitter stream being classified in real-time, please see the following video:
In conclusion, we showed how easy it is to distill a dense model onto a sparse student model without having to deal with the sparsification itself. With all these optimization techniques we managed to get a 6x improvement in our NLP pipeline latency. Keep in mind that using a real-time tweet inference application is best suited for trading hours when the markets are open otherwise traffic may be slow. Interested users in enhancing or editing the dataset can send commits to our dataset.
If you have any questions or comments, please reach out to our community Slack channel or submit a PR on GitHub.







